Сравнивая BSXFUN и REPMAT
Несколько вопросов задавались перед сравнением между bsxfun и repmat для производительности.
- Один из них:
Matlab - bsxfun no longer faster than repmat?. Это попыталось исследовать сопоставления производительности междуrepmatиbsxfun, специфичными для выполнения вычитания входного массива по столбцам из самого входного массива и как таковой будет исследовать только часть@minusbsxfunпротив ееrepmat. - Другой был:
In Matlab, when is it optimal to use bsxfun?. Тот пытался сделать одну и ту же операцию вычитания средним по столбцам и не расширился и на другие встроенные операции.
С этим сообщением я пытаюсь исследовать числа производительности между bsxfun и repmat, чтобы охватить все bsxfun встроенные функции, чтобы дать им более широкую перспективу, как обе эти хорошие векторизованные решения.
В частности, мои вопросы с этим сообщением:
-
Как выполняются различные встроенные операции с
bsxfunс эквивалентамиrepmat?bsxfunподдерживает операции с плавающей запятой, такие как@plus,@minus,@timesи т.д., а также реляционные и логические операции, такие как@ge,@andи т.д. Итак, которые могли бы дать мне заметные ускорения сbsxfun, чем использовать ихrepmatэквиваленты? -
Лорен в ней
blog postимеет сравнительный тестrepmatпротивbsxfunсо временем@() A - repmat(mean(A),size(A,1),1)против@() bsxfun(@minus,A,mean(A))соответственно. Если мне нужно охватить бенчмаркинг для всех встроенных модулей, могу ли я использовать некоторую другую сравнительную модель, которая будет работать с плавающей точкой, реляционными и логическими операциями?
1 ответ
Введение
Дискуссия о том, лучше ли bsxfun, чем repmat, или наоборот, продолжается как всегда. В этом посте мы попытаемся сравнить, как различные встроенные модули, которые поставляются с MATLAB, борются с эквивалентами repmat с точки зрения их исполнения во время выполнения и, надеюсь, сделают из них какие-то значимые выводы.
Знакомство с встроенными функциями BSXFUN
Если официальная документация выведена из среды MATLAB или через веб-сайт Mathworks, можно увидеть полный список встроенных функций поддерживается bsxfun. Этот список имеет функции для операций с плавающей точкой, реляционных и логических операций.
В MATLAB 2015A поддерживаемые элементы с плавающей запятой:
- @plus (суммирование)
- @minus (вычитание)
- @times (умножение)
- @rdivide (праводеление)
- @ldivide (left-divide)
- @pow (мощность)
- @rem (остаток)
- @mod (модуль)
- @atan2 (четыре квадрантных обратных касательных)
- @atan2d (четыре квадранта, обратная касательная в градусах)
- @hypot (квадратный корень из суммы квадратов).
Второй набор состоит из элементарных реляционных операций, а именно:
- @eq (равно)
- @ne (не равно)
- @lt (меньше)
- @le (меньше или равно)
- @gt (больше)
- @ge (больше или равно).
Третий и последний набор содержит логические операции, перечисленные здесь:
- @и (логический и)
- @or (логический или)
- @xor (логический xor).
Обратите внимание, что мы исключили из наших тестов сравнения два встроенных @max (maximum) и @min (minimum), так как может быть много способов реализовать их эквиваленты repmat.
Модель сравнения
Чтобы действительно сравнить характеристики между repmat и bsxfun, нам нужно убедиться, что тайминги должны покрывать только предназначенные операции. Таким образом, что-то вроде bsxfun(@minus,A,mean(A)) не будет идеальным, так как оно должно вычислять mean(A) внутри этого вызова bsxfun, каким бы незначительным это время не могло быть. Вместо этого мы можем использовать другой вход B того же размера, что и mean(A).
Таким образом, мы можем использовать: A = rand(m,n) и B = rand(1,n), где m и n - это параметры размера, которые мы могли бы варьировать и изучать характеристики, основанные на них. Это точно сделано в наших тестах бенчмаркинга, перечисленных в следующем разделе.
Версии repmat и bsxfun для работы с этими входами выглядят примерно так:
REPMAT: A + repmat(B,size(A,1),1)
BSXFUN: bsxfun(@plus,A,B)
Бенчмаркинг
Наконец, мы находимся в центре этой публикации, чтобы посмотреть, как эти двое борются с этим. Мы разделили бенчмаркинг на три набора: один для операций с плавающей запятой, другой для реляционных и третий для логических операций. Мы распространили сравнительную модель, как обсуждалось ранее, на все эти операции.
Set1: операции с плавающей запятой
Здесь первый набор эталонного кода для операций с плавающей запятой с repmat и bsxfun -
datasizes = [ 100 100; 100 1000; 100 10000; 100 100000;
1000 100; 1000 1000; 1000 10000;
10000 100; 10000 1000; 10000 10000;
100000 100; 100000 1000];
num_funcs = 11;
tsec_rep = NaN(size(datasizes,1),num_funcs);
tsec_bsx = NaN(size(datasizes,1),num_funcs);
for iter = 1:size(datasizes,1)
m = datasizes(iter,1);
n = datasizes(iter,2);
A = rand(m,n);
B = rand(1,n);
fcns_rep= {@() A + repmat(B,size(A,1),1),@() A - repmat(B,size(A,1),1),...
@() A .* repmat(B,size(A,1),1), @() A ./ repmat(B,size(A,1),1),...
@() A.\repmat(B,size(A,1),1), @() A .^ repmat(B,size(A,1),1),...
@() rem(A ,repmat(B,size(A,1),1)), @() mod(A,repmat(B,size(A,1),1)),...
@() atan2(A,repmat(B,size(A,1),1)),@() atan2d(A,repmat(B,size(A,1),1)),...
@() hypot( A , repmat(B,size(A,1),1) )};
fcns_bsx = {@() bsxfun(@plus,A,B), @() bsxfun(@minus,A,B), ...
@() bsxfun(@times,A,B),@() bsxfun(@rdivide,A,B),...
@() bsxfun(@ldivide,A,B), @() bsxfun(@power,A,B), ...
@() bsxfun(@rem,A,B), @() bsxfun(@mod,A,B), @() bsxfun(@atan2,A,B),...
@() bsxfun(@atan2d,A,B), @() bsxfun(@hypot,A,B)};
for k1 = 1:numel(fcns_bsx)
tsec_rep(iter,k1) = timeit(fcns_rep{k1});
tsec_bsx(iter,k1) = timeit(fcns_bsx{k1});
end
end
speedups = tsec_rep./tsec_bsx;
Set2: Реляционные операции
Операции реляционных операций с эталонным кодом для времени будут заменять fcns_rep и fcns_bsx на предыдущий код сравнения с этими копиями -
fcns_rep = {
@() A == repmat(B,size(A,1),1), @() A ~= repmat(B,size(A,1),1),...
@() A < repmat(B,size(A,1),1), @() A <= repmat(B,size(A,1),1), ...
@() A > repmat(B,size(A,1),1), @() A >= repmat(B,size(A,1),1)};
fcns_bsx = {
@() bsxfun(@eq,A,B), @() bsxfun(@ne,A,B), @() bsxfun(@lt,A,B),...
@() bsxfun(@le,A,B), @() bsxfun(@gt,A,B), @() bsxfun(@ge,A,B)};
Set3: Логические операции
Окончательный набор кодов бенчмаркинга будет использовать логические операции, перечисленные здесь -
fcns_rep = {
@() A & repmat(B,size(A,1),1), @() A | repmat(B,size(A,1),1), ...
@() xor(A,repmat(B,size(A,1),1))};
fcns_bsx = {
@() bsxfun(@and,A,B), @() bsxfun(@or,A,B), @() bsxfun(@xor,A,B)};
Обратите внимание, что для этого конкретного набора входные данные, необходимые A и B, были логическими массивами. Таким образом, мы должны были сделать эти изменения в более раннем эталонном коде для создания логических массивов -
A = rand(m,n)>0.5;
B = rand(1,n)>0.5;
Время выполнения и наблюдения
В этой конфигурации системы выполнялись коды бенчмаркинга:
MATLAB Version: 8.5.0.197613 (R2015a)
Operating System: Windows 7 Professional 64-bit
RAM: 16GB
CPU Model: Intel Core i7-4790K @4.00GHz
Ускорение, полученное таким образом с помощью bsxfun over repmat после запуска тестовых тестов, было построено для трех наборов, как показано ниже.
а. Операции с плавающей точкой:
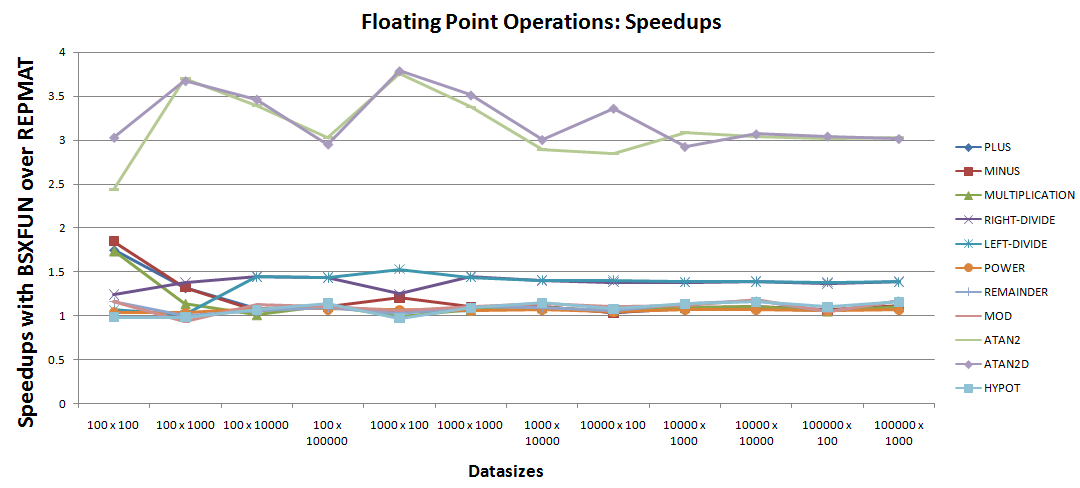
Немногочисленные наблюдения можно было бы сделать из графика ускорения:
- Значительно два хороших случая ускорения с
bsxfunдляatan2иatan2d. - Далее в этом списке находятся операции с правым и левым делением, которые увеличивают выполнение с помощью
30% - 50%по эквивалентным кодамrepmat. - Далее в этом списке идут оставшиеся операции
7, чьи ускорения кажутся очень близкими к единице и, следовательно, требуют более тщательного изучения. График ускорения можно сузить до тех же7операций, как показано ниже -
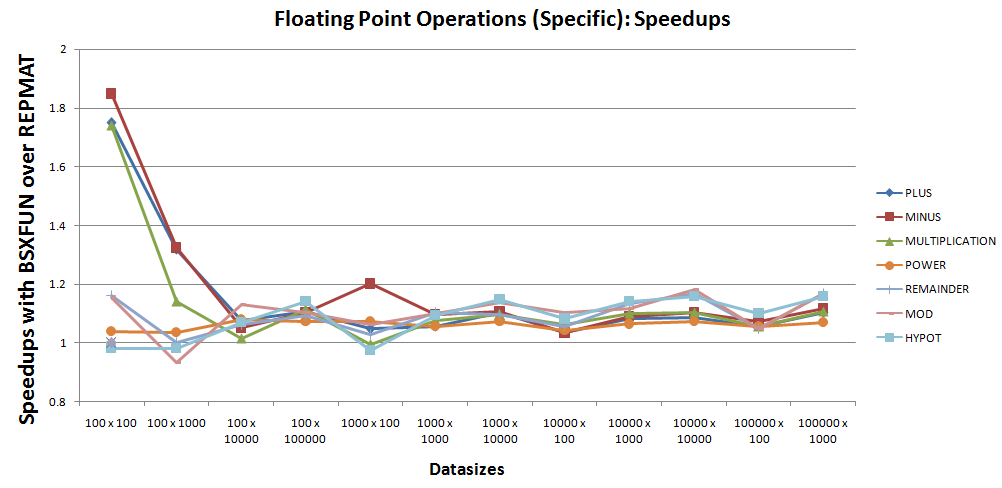
На основании вышеприведенного графика видно, что запрет одноразовых случаев с @hypot и @mod, bsxfun по-прежнему выполняет примерно на 10% лучше, чем repmat для этих операций 7.
В. Реляционные операции:
Это второй набор эталонных тестов для следующих 6 встроенных реляционных операций, поддерживаемых bsxfun.
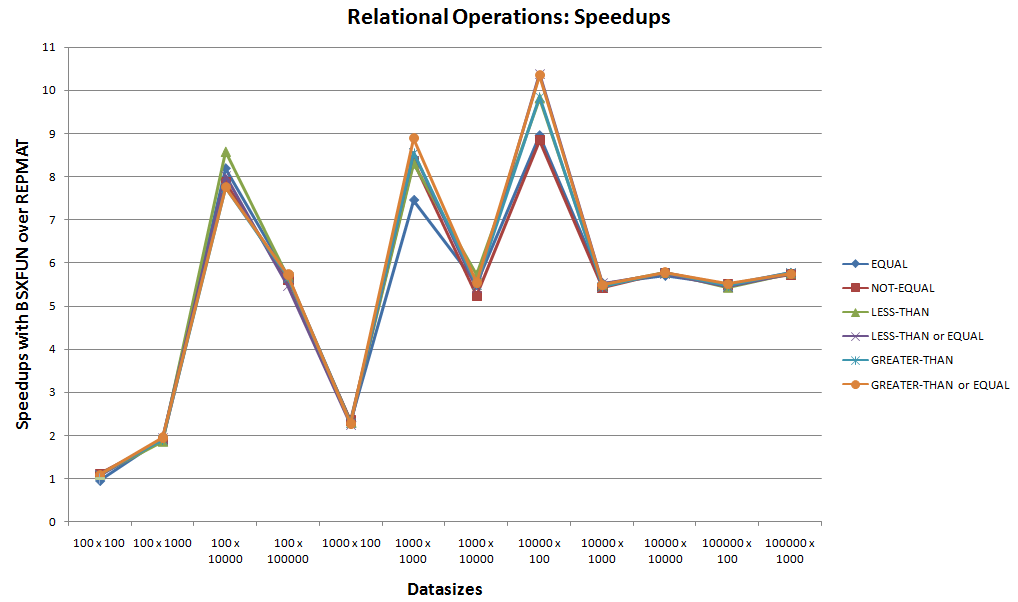
Рассматривая график ускорения выше, пренебрегая стартовым случаем, имеющим сопоставимые промежутки времени между bsxfun и repmat, можно легко увидеть bsxfun выигрыш для этих реляционных операций. С ускорением, касающимся 10x, bsxfun всегда будет предпочтительнее для этих случаев.
С. Логические операции:
Это третий набор эталонных тестов для оставшихся 3 встроенных логических операций, поддерживаемых bsxfun.

Пренебрегая одноразовым сопоставимым временем выполнения для @xor в начале, bsxfun, похоже, имеет верхнюю часть для этого набора логических операций.
Выводы
- При работе с реляционными и логическими операциями
repmatможно легко забыть в пользуbsxfun. Для остальных случаев все еще сохраняетсяbsxfun, если допустимы однократные случаи с меньшей производительностью5 - 7%. - Увидев огромный прирост производительности при использовании реляционных и логических операций с
bsxfun, можно подумать об использованииbsxfunдля работы с данными сragged patterns, что-то вроде массивов ячеек для производительность. Мне нравится называть эти случаи решения как те, которые используютbsxfunвозможность маскировки. Это в основном означает, что мы создаем логические массивы, т.е. Маски сbsxfun, которые могут использоваться для обмена данными между массивами ячеек и числовыми массивами. Одним из преимуществ наличия работоспособных данных в числовых массивах является то, что векторизованные методы могут использоваться для их обработки. Опять же, посколькуbsxfun- хороший инструмент для векторизации, вы можете снова использовать его, работая над той же проблемой, поэтому есть больше причин узнатьbsxfun. Несколько примеров решений, в которых я смог исследовать такие методы, связаны здесь в интересах читателей: 1, 2, 3, 4, 5.
Будущая работа
В настоящей работе основное внимание уделялось репликации данных по одному измерению с помощью repmat. Теперь repmat может реплицироваться по нескольким размерам, поэтому bsxfun с его расширениями, эквивалентными репликации. Таким образом, было бы интересно выполнить аналогичные тесты по репликации и расширениям на несколько измерений с помощью этих двух функций.
Ещё вопросы
- 0как использовать q.all в Angular Js?
- 1Метка в Listview изменяет высоту и ширину после прокрутки
- 0Метод uploadStoredFiles не существует в jQuery.fineUploader
- 1Чтение данных из Hashmap - Android studio, Firebase
- 0SFML возвращает окно в другой класс через конструктор, не работающий
- 0Вывод вектора списков в C ++
- 1Использование ViewRenderer для рендеринга PartialView в ответе SignalR?
- 0Изображение после sql результата Combobox PHP
- 1Утверждение и документация в классе для методов, которые ожидаются в производных классах
- 0angularjs app.service (…) вызывает «Uncaught TypeError: undefined не является функцией»
- 0PHP время назад (возвращает неверное время)
- 1Настройка SFML.net 2.1?
- 0Использование CASE в Mysql для установки значения в поле Alias
- 1Как открыть конкретный экран после нажатия на уведомление?
- 0Замена нескольких экземпляров слов на .replace
- 0API Календаря Google, getItem и getSummery ничего не возвращает
- 0Как отобразить строку как дату? [Дубликат]
- 1DataOutputStream.writeBytes добавляет ноль байтов
- 1PyQt: множественный QProcess и вывод
- 0Выберите следующее «свободное» целое число на основе ввода
- 0Группировать записи по двум столбцам
- 0Невозможно использовать возвращаемое значение метода в контексте записи
- 1Как Pythonic устанавливает в классе статический словарь, который можно изменять во время выполнения?
- 0Проверка jQuery внутри jQuery .each ()
- 0Сохраните отфильтрованный список перед применением другого фильтра с помощью ng-repeat
- 2Как установить ADB-соединения для NOX-плеера в Mac OS
- 1Android рухнул после обновления androidx biometric до 1.0.0-alpha04
- 1Как передать только сообщения об ошибках из модели в контроллер (Mongoose)?
- 0URL со ссылкой на объект из ответа HATEOAS REST в AngularJS
- 0вставлять и удалять целые числа на лету
- 1Заполнение объекта вложенного списка модели на основе выбора флажков в ASP.NET MVC
- 0MySQL: группировка по нескольким столбцам, не дающая точных результатов
- 0PHP-флеш не работает
- 1Начальная настройка Android Realm
- 1Создайте ArrayList объектов класса данных из строки в Kotlin
- 1Преобразовать значения пикселей RGB в диапазоне в последовательные числа
- 0ошибка: нет соответствующей функции для вызова const
- 1Первая сборка приложения Node.JS в TFS 2015 Update2
- 1Как перебрать список по два в Python 3? [Дубликат]
- 1Записать строку с символами новой строки в файл
- 0Цикл чтения строк в C ++
- 1Динамическое центрирование поисковой панели на основе размеров изображения
- 0Слушатель потребляет ключи даже с холста?
- 0Можем ли мы иметь автоматическую предустановку AspectRatio для выходных файлов из AWS Elastic Transcoder?
- 1Android - 403 при запросе изображения карты с действующим ключом API
- 1java.lang.NullPointerException - не может найти пустую переменную
- 0MySQL: как выбрать min (), используя подзапрос и объединения
- 0JQuery селектор, чтобы игнорировать элемент?
- 1Разница между развертыванием WAR и папки Build
- 0Создайте «форму расчета» в javascript
