Как отсортировать данные по нескольким столбцам?
Я хочу сортировать data.frame по нескольким столбцам. Например, с приведенным ниже номером data.frame, я хотел бы отсортировать по столбцу z (убыв), затем по столбцу b (по возрастанию):
dd <- data.frame(b = factor(c("Hi", "Med", "Hi", "Low"),
levels = c("Low", "Med", "Hi"), ordered = TRUE),
x = c("A", "D", "A", "C"), y = c(8, 3, 9, 9),
z = c(1, 1, 1, 2))
dd
b x y z
1 Hi A 8 1
2 Med D 3 1
3 Hi A 9 1
4 Low C 9 2
-
0Для панд решение можно найти здесь .coldspeed
19 ответов
Вы можете использовать функцию order() напрямую, не прибегая к дополнительным инструментам - посмотрите на этот более простой ответ, который использует трюк прямо в верхней части example(order) кода example(order):
R> dd[with(dd, order(-z, b)), ]
b x y z
4 Low C 9 2
2 Med D 3 1
1 Hi A 8 1
3 Hi A 9 1
Отредактируйте 2+ несколько лет спустя: просто спросили, как это сделать по индексу столбца. Ответ заключается в том, чтобы просто передать нужные столбцы сортировки в функцию order():
R> dd[order(-dd[,4], dd[,1]), ]
b x y z
4 Low C 9 2
2 Med D 3 1
1 Hi A 8 1
3 Hi A 9 1
R>
вместо того, чтобы использовать имя столбца (и with() для более простого/более прямого доступа).
-
0@Dirk Eddelbuettel Есть ли такой же простой метод для матриц?
-
12Должен работать так же, но вы не можете использовать
with. ПопробуйтеM <- matrix(c(1,2,2,2,3,6,4,5), 4, 2, byrow=FALSE, dimnames=list(NULL, c("a","b")))чтобы создать матрицуM, затем используйтеM[order(M[,"a"],-M[,"b"]),]чтобы упорядочить ее по двум столбцам.
Ваш выбор
-
orderотbase -
arrangefromdplyr -
setorderиsetordervотdata.table -
arrangeотplyr -
sortfromtaRifx -
orderByfromdoBy -
sortDatafromDeducer
В большинстве случаев вы должны использовать решения dplyr или data.table, если важны не-зависимостей, и в этом случае используйте base::order.
Недавно я добавил sort.data.frame в пакет CRAN, что делает его совместимым с классом, как описано здесь: Лучший способ создания универсальной/согласованности методов для sort.data.frame?
Поэтому, учитывая data.frame dd, вы можете сортировать следующее:
dd <- data.frame(b = factor(c("Hi", "Med", "Hi", "Low"),
levels = c("Low", "Med", "Hi"), ordered = TRUE),
x = c("A", "D", "A", "C"), y = c(8, 3, 9, 9),
z = c(1, 1, 1, 2))
library(taRifx)
sort(dd, f= ~ -z + b )
Если вы являетесь одним из авторов этой функции, свяжитесь со мной. Обсуждение общедоступности здесь: http://chat.stackoverflow.com/transcript/message/1094290#1094290
Вы также можете использовать функцию arrange() от plyr, как указал Хэдли в вышеупомянутом потоке:
library(plyr)
arrange(dd,desc(z),b)
Контрольные показатели. Обратите внимание, что я загружал каждый пакет в новый сеанс R, так как было много конфликтов. В частности, загрузка пакета doBy вызывает возврат sort "Следующие объекты замаскированы из" x (позиция 17) ": b, x, y, z" и загрузка пакета Deducer перезаписывает sort.data.frame из Kevin Райт или пакет taRifx.
#Load each time
dd <- data.frame(b = factor(c("Hi", "Med", "Hi", "Low"),
levels = c("Low", "Med", "Hi"), ordered = TRUE),
x = c("A", "D", "A", "C"), y = c(8, 3, 9, 9),
z = c(1, 1, 1, 2))
library(microbenchmark)
# Reload R between benchmarks
microbenchmark(dd[with(dd, order(-z, b)), ] ,
dd[order(-dd$z, dd$b),],
times=1000
)
Среднее время:
dd[with(dd, order(-z, b)), ] 778
dd[order(-dd$z, dd$b),] 788
library(taRifx)
microbenchmark(sort(dd, f= ~-z+b ),times=1000)
Среднее время: 1,567
library(plyr)
microbenchmark(arrange(dd,desc(z),b),times=1000)
Среднее время: 862
library(doBy)
microbenchmark(orderBy(~-z+b, data=dd),times=1000)
Среднее время: 1,694
Обратите внимание, что doBy занимает немного времени, чтобы загрузить пакет.
library(Deducer)
microbenchmark(sortData(dd,c("z","b"),increasing= c(FALSE,TRUE)),times=1000)
Невозможно выполнить загрузку Deducer. Требуется консоль JGR.
esort <- function(x, sortvar, ...) {
attach(x)
x <- x[with(x,order(sortvar,...)),]
return(x)
detach(x)
}
microbenchmark(esort(dd, -z, b),times=1000)
Кажется, что он не совместим с microbenchmark из-за прикрепления/отсоединения.
m <- microbenchmark(
arrange(dd,desc(z),b),
sort(dd, f= ~-z+b ),
dd[with(dd, order(-z, b)), ] ,
dd[order(-dd$z, dd$b),],
times=1000
)
uq <- function(x) { fivenum(x)[4]}
lq <- function(x) { fivenum(x)[2]}
y_min <- 0 # min(by(m$time,m$expr,lq))
y_max <- max(by(m$time,m$expr,uq)) * 1.05
p <- ggplot(m,aes(x=expr,y=time)) + coord_cartesian(ylim = c( y_min , y_max ))
p + stat_summary(fun.y=median,fun.ymin = lq, fun.ymax = uq, aes(fill=expr))
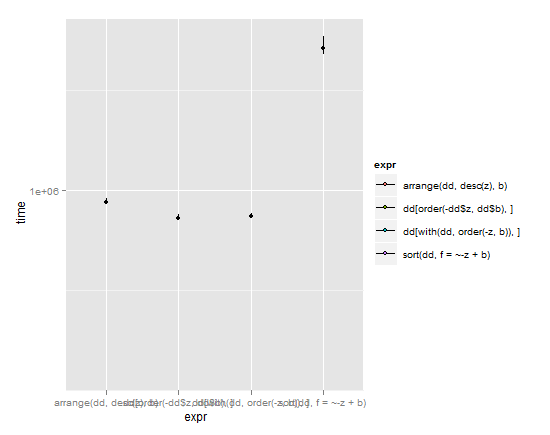
(линии простираются от нижнего квартиля до верхнего квартиля, точка - медиана)
Учитывая эти результаты и простоту в сравнении с скоростью, я должен был бы дать кивок arrange в пакете plyr. Он имеет простой синтаксис и все же почти так же быстродействующий, как и базовые команды R с их запутанными махинациями. Как правило, блестящий Хэдли Уикхем работает. Моя единственная проблема заключается в том, что он разбивает стандартную номенклатуру R, в которой сортирующие объекты вызываются sort(object), но я понимаю, почему Хэдли сделал это так из-за проблем, обсуждаемых в вопросе, указанном выше.
-
6+1 за тщательность, хотя я признаю, что нахожу вывод
microbenchmarkдовольно трудным для чтения ... -
3Вышеприведенная функция микробенчмарка ggplot2 теперь доступна как
taRifx::autoplot.microbenchmark.
Ответ на Dirk велик. Он также подчеркивает ключевое различие в синтаксисе, используемом для индексирования data.frame и data.table s:
## The data.frame way
dd[with(dd, order(-z, b)), ]
## The data.table way: (7 fewer characters, but that not the important bit)
dd[order(-z, b)]
Разница между двумя вызовами мала, но может иметь важные последствия. Особенно, если вы пишете производственный код и/или относитесь к правильности в своих исследованиях, лучше избегать ненужного повторения имен переменных. data.table
поможет вам это сделать.
Вот пример того, как повторение имен переменных может вызвать у вас проблемы:
Измените контекст из ответа Дирка и скажите, что это часть более крупного проекта, в котором много имен объектов, и они являются длинными и значимыми; вместо dd он называется quarterlyreport. Это будет:
quarterlyreport[with(quarterlyreport,order(-z,b)),]
Хорошо, отлично. В этом нет ничего плохого. Затем ваш босс попросит вас включить отчет в последний квартал в отчет. Вы просматриваете свой код, добавляя объект lastquarterlyreport в разных местах и каким-то образом (как на земле?) Вы в итоге получаете следующее:
quarterlyreport[with(lastquarterlyreport,order(-z,b)),]
Это не то, что вы имели в виду, но вы не заметили его, потому что вы сделали это быстро, и он был размещен на странице аналогичного кода. Код не падает (без предупреждения и без ошибок), потому что R думает, что это то, что вы имели в виду. Вы бы надеялись, что кто-то, кто читает ваш отчет, назовет его, но, возможно, нет. Если вы много работаете с языками программирования, то эта ситуация может быть знакомой. Вы скажете "опечатку". Я исправлю "опечатку", которую вы скажете своему боссу.
В data.table нас беспокоят крошечные детали, подобные этому. Итак, мы сделали что-то простое, чтобы не вводить имена переменных дважды. Что-то очень простое. i оценивается в рамках dd уже автоматически. Вам не нужно with() вообще.
Вместо
dd[with(dd, order(-z, b)), ]
просто
dd[order(-z, b)]
И вместо
quarterlyreport[with(lastquarterlyreport,order(-z,b)),]
просто
quarterlyreport[order(-z,b)]
Это очень маленькая разница, но в один прекрасный день она может просто спасти вашу шею. При взвешивании разных ответов на этот вопрос подумайте о подсчете повторений имен переменных в качестве одного из ваших критериев при принятии решения. В некоторых ответах есть много повторений, другие - нет.
-
9+1 Это замечательный момент, и он подробно описывает синтаксис R, который часто раздражал меня. Я иногда использую
subset()чтобы избежать необходимости повторного обращения к одному и тому же объекту в течение одного вызова. -
1Есть идеи, почему они работают по-разному?
Здесь есть много отличных ответов, но dplyr дает единственный синтаксис, который я могу быстро и легко запомнить (и поэтому теперь очень часто использую):
library(dplyr)
# sort mtcars by mpg, ascending... use desc(mpg) for descending
arrange(mtcars, mpg)
# sort mtcars first by mpg, then by cyl, then by wt)
arrange(mtcars , mpg, cyl, wt)
Для задачи OP:
arrange(dd, desc(z), b)
b x y z
1 Low C 9 2
2 Med D 3 1
3 Hi A 8 1
4 Hi A 9 1
-
2Принятый ответ не работает, когда мои столбцы имеют тип-фактор (или что-то в этом роде), и я хочу отсортировать по убыванию этот столбец с последующим целочисленным столбцом по возрастанию. Но это работает просто отлично! Спасибо!
-
10Почему "только"? Я считаю, что
dd[order(-z, b)]для data.table довольно прост в использовании и запоминании.
Пакет R data.table обеспечивает как быстрый, так и эффективный порядок памяти данных. Таблицы с прямым синтаксисом (часть из которых Мэтт довольно хорошо выделил в своем ответе). С тех пор было сделано много улучшений, а также новая функция setorder(). Из v1.9.5+, setorder() также работает с data.frames.
Сначала мы создадим набор данных достаточно большой и сравним различные методы, упомянутые в других ответах, а затем перечислим особенности data.table.
Данные:
require(plyr)
require(doBy)
require(data.table)
require(dplyr)
require(taRifx)
set.seed(45L)
dat = data.frame(b = as.factor(sample(c("Hi", "Med", "Low"), 1e8, TRUE)),
x = sample(c("A", "D", "C"), 1e8, TRUE),
y = sample(100, 1e8, TRUE),
z = sample(5, 1e8, TRUE),
stringsAsFactors = FALSE)
Ориентиры:
Сообщаемые тайминги - это запуск system.time(...) для этих функций, показанных ниже. Тайминги приведены ниже (в порядке наименьшей скорости).
orderBy( ~ -z + b, data = dat) ## doBy
plyr::arrange(dat, desc(z), b) ## plyr
arrange(dat, desc(z), b) ## dplyr
sort(dat, f = ~ -z + b) ## taRifx
dat[with(dat, order(-z, b)), ] ## base R
# convert to data.table, by reference
setDT(dat)
dat[order(-z, b)] ## data.table, base R like syntax
setorder(dat, -z, b) ## data.table, using setorder()
## setorder() now also works with data.frames
# R-session memory usage (BEFORE) = ~2GB (size of 'dat')
# ------------------------------------------------------------
# Package function Time (s) Peak memory Memory used
# ------------------------------------------------------------
# doBy orderBy 409.7 6.7 GB 4.7 GB
# taRifx sort 400.8 6.7 GB 4.7 GB
# plyr arrange 318.8 5.6 GB 3.6 GB
# base R order 299.0 5.6 GB 3.6 GB
# dplyr arrange 62.7 4.2 GB 2.2 GB
# ------------------------------------------------------------
# data.table order 6.2 4.2 GB 2.2 GB
# data.table setorder 4.5 2.4 GB 0.4 GB
# ------------------------------------------------------------
-
data.tableDT[order(...)]синтаксис был ~ 10x быстрее, чем самый быстрый из других методов (dplyr), потребляя тот же объем памяти, что иdplyr. -
data.tablesetorder()был ~ 14x быстрее, чем самый быстрый из других методов (dplyr), при этом всего 0,4 ГБ дополнительной памяти.datтеперь находится в том порядке, в котором мы требуем (поскольку он обновляется по ссылке).
функции data.table:
Скорость:
-
data.table упорядочивается очень быстро, потому что он реализует упорядочение радиуса.
-
Синтаксис
DT[order(...)]оптимизируется внутри, чтобы использовать также быстрый заказ данных. Вы можете продолжать использовать знакомый базовый синтаксис R, но ускорить процесс (и использовать меньше памяти).
Память:
-
В большинстве случаев нам не требуется исходный файл data.frame или data.table после переупорядочения. То есть мы обычно присваиваем результат обратно одному и тому же объекту, например:
DF <- DF[order(...)]Проблема в том, что для этого требуется как минимум дважды (2x) память исходного объекта. Для эффективной работы с памятью data.table также предоставляет функцию
setorder().setorder()переупорядочивает data.tablesby reference(на месте) без каких-либо дополнительных копий. Он использует только дополнительную память, равную размеру одного столбца.
Другие функции:
-
Он поддерживает типы
integer,logical,numeric,characterи дажеbit64::integer64.Обратите внимание, что
factor,Date,POSIXctи т.д. классы - всеinteger/numericтипы под дополнительными атрибутами и поэтому поддерживаются. -
В базе R мы не можем использовать
-для символьного вектора для сортировки по этому столбцу в порядке убывания. Вместо этого мы должны использовать-xtfrm(.).Однако в data.table мы можем просто сделать, например,
dat[order(-x)]илиsetorder(dat, -x).
-
0Спасибо за этот очень поучительный ответ о data.table. Хотя я не понимаю, что такое «пиковая память» и как вы ее рассчитали. Не могли бы вы объяснить, пожалуйста? Спасибо !
-
0Я использовал Instruments -> allocations и сообщил о размере «Все кучи и распределение VM».
С эта (очень полезная) функция Кевина Райт, размещенная в разделе советов R wiki, это легко достигается.
sort(dd,by = ~ -z + b)
# b x y z
# 4 Low C 9 2
# 2 Med D 3 1
# 1 Hi A 8 1
# 3 Hi A 9 1
-
2Смотрите мой ответ для сравнительного анализа алгоритма, используемого в этой функции.
или вы можете использовать пакет doBy
library(doBy)
dd <- orderBy(~-z+b, data=dd)
Предположим, что у вас есть data.frame A, и вы хотите отсортировать его с помощью столбца с именем x по убыванию. Вызовите отсортированный data.frame newdata
newdata <- A[order(-A$x),]
Если вы хотите по возрастанию, замените "-" на ничего. У вас может быть что-то вроде
newdata <- A[order(-A$x, A$y, -A$z),]
где x и z - некоторые столбцы в data.frame A. Это означает сортировку data.frame A по убыванию x, y по возрастанию и z по убыванию.
В качестве альтернативы, используя пакет Deducer
library(Deducer)
dd<- sortData(dd,c("z","b"),increasing= c(FALSE,TRUE))
если SQL приходит к вам естественным образом, sqldf обрабатывает ORDER BY как Codd.
-
7MJM, спасибо за указание на этот пакет. Это невероятно гибко, и потому, что половина моей работы уже выполнена путем извлечения из баз данных sql, это проще, чем изучать большую часть R менее интуитивного синтаксиса.
Я узнал о order со следующим примером, который затем смутил меня в течение длительного времени:
set.seed(1234)
ID = 1:10
Age = round(rnorm(10, 50, 1))
diag = c("Depression", "Bipolar")
Diagnosis = sample(diag, 10, replace=TRUE)
data = data.frame(ID, Age, Diagnosis)
databyAge = data[order(Age),]
databyAge
Единственная причина, по которой этот пример работает, заключается в том, что order сортирует по vector Age, а не по столбцу с именем Age в data frame data.
Чтобы увидеть это, создайте идентичный фрейм данных с помощью read.table с немного разными именами столбцов и без использования какого-либо из перечисленных выше векторов:
my.data <- read.table(text = '
id age diagnosis
1 49 Depression
2 50 Depression
3 51 Depression
4 48 Depression
5 50 Depression
6 51 Bipolar
7 49 Bipolar
8 49 Bipolar
9 49 Bipolar
10 49 Depression
', header = TRUE)
Вышеуказанная структура строки для order больше не работает, потому что нет вектора с именем Age:
databyage = my.data[order(age),]
Следующая строка работает, потому что order сортирует по столбцу Age в my.data.
databyage = my.data[order(my.data$age),]
Я думал, что это стоит того, чтобы рассказывать, как я был смущен этим примером надолго. Если этот пост не считается подходящим для потока, я могу его удалить.
EDIT: 13 мая 2014 года
Ниже приведен обобщенный способ сортировки кадра данных по каждому столбцу без указания имен столбцов. В приведенном ниже коде показано, как сортировать слева направо или справа налево. Это работает, если каждый столбец является числовым. Я не пробовал использовать колонку символов.
Я нашел код do.call месяц или два назад в старой почте на другом сайте, но только после обширного и сложного поиска. Я не уверен, что смогу переместить этот пост сейчас. Настоящий поток является первым хитом для упорядочивания a data.frame в R. Итак, я думал, что моя расширенная версия этого исходного кода do.call может быть полезна.
set.seed(1234)
v1 <- c(0,0,0,0, 0,0,0,0, 1,1,1,1, 1,1,1,1)
v2 <- c(0,0,0,0, 1,1,1,1, 0,0,0,0, 1,1,1,1)
v3 <- c(0,0,1,1, 0,0,1,1, 0,0,1,1, 0,0,1,1)
v4 <- c(0,1,0,1, 0,1,0,1, 0,1,0,1, 0,1,0,1)
df.1 <- data.frame(v1, v2, v3, v4)
df.1
rdf.1 <- df.1[sample(nrow(df.1), nrow(df.1), replace = FALSE),]
rdf.1
order.rdf.1 <- rdf.1[do.call(order, as.list(rdf.1)),]
order.rdf.1
order.rdf.2 <- rdf.1[do.call(order, rev(as.list(rdf.1))),]
order.rdf.2
rdf.3 <- data.frame(rdf.1$v2, rdf.1$v4, rdf.1$v3, rdf.1$v1)
rdf.3
order.rdf.3 <- rdf.1[do.call(order, as.list(rdf.3)),]
order.rdf.3
-
4Этот синтаксис работает, если вы храните ваши данные в data.table вместо data.frame:
require(data.table); my.dt <- data.table(my.data); my.dt[order(age)]Это работает, потому что имена столбцов доступны в скобках []. -
0Я не думаю, что понижение здесь необходимо, но я не думаю, что это добавляет много к рассматриваемому вопросу , особенно учитывая существующий набор ответов, некоторые из которых уже
data.frameтребование кdata.frameдля использованияwithили$.
Ответ на Dirk хорош, но если вам нужно, чтобы сортировка сохранялась, вы хотите применить сортировку обратно к названию этого фрейма данных. Используя пример кода:
dd <- dd[with(dd, order(-z, b)), ]
В ответ на комментарий, добавленный в OP для того, как сортировать программно:
Используя dplyr и data.table
library(dplyr)
library(data.table)
dplyr
Просто используйте arrange_, который является стандартной версией оценки для arrange.
df1 <- tbl_df(iris)
#using strings or formula
arrange_(df1, c('Petal.Length', 'Petal.Width'))
arrange_(df1, ~Petal.Length, ~Petal.Width)
Source: local data frame [150 x 5]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
(dbl) (dbl) (dbl) (dbl) (fctr)
1 4.6 3.6 1.0 0.2 setosa
2 4.3 3.0 1.1 0.1 setosa
3 5.8 4.0 1.2 0.2 setosa
4 5.0 3.2 1.2 0.2 setosa
5 4.7 3.2 1.3 0.2 setosa
6 5.4 3.9 1.3 0.4 setosa
7 5.5 3.5 1.3 0.2 setosa
8 4.4 3.0 1.3 0.2 setosa
9 5.0 3.5 1.3 0.3 setosa
10 4.5 2.3 1.3 0.3 setosa
.. ... ... ... ... ...
#Or using a variable
sortBy <- c('Petal.Length', 'Petal.Width')
arrange_(df1, .dots = sortBy)
Source: local data frame [150 x 5]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
(dbl) (dbl) (dbl) (dbl) (fctr)
1 4.6 3.6 1.0 0.2 setosa
2 4.3 3.0 1.1 0.1 setosa
3 5.8 4.0 1.2 0.2 setosa
4 5.0 3.2 1.2 0.2 setosa
5 4.7 3.2 1.3 0.2 setosa
6 5.5 3.5 1.3 0.2 setosa
7 4.4 3.0 1.3 0.2 setosa
8 4.4 3.2 1.3 0.2 setosa
9 5.0 3.5 1.3 0.3 setosa
10 4.5 2.3 1.3 0.3 setosa
.. ... ... ... ... ...
#Doing the same operation except sorting Petal.Length in descending order
sortByDesc <- c('desc(Petal.Length)', 'Petal.Width')
arrange_(df1, .dots = sortByDesc)
подробнее здесь: https://cran.r-project.org/web/packages/dplyr/vignettes/nse.html
Лучше использовать формулу, поскольку она также захватывает среду для оценки выражения в
data.table
dt1 <- data.table(iris) #not really required, as you can work directly on your data.frame
sortBy <- c('Petal.Length', 'Petal.Width')
sortType <- c(-1, 1)
setorderv(dt1, sortBy, sortType)
dt1
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1: 7.7 2.6 6.9 2.3 virginica
2: 7.7 2.8 6.7 2.0 virginica
3: 7.7 3.8 6.7 2.2 virginica
4: 7.6 3.0 6.6 2.1 virginica
5: 7.9 3.8 6.4 2.0 virginica
---
146: 5.4 3.9 1.3 0.4 setosa
147: 5.8 4.0 1.2 0.2 setosa
148: 5.0 3.2 1.2 0.2 setosa
149: 4.3 3.0 1.1 0.1 setosa
150: 4.6 3.6 1.0 0.2 setosa
Аранжировка() в dplyer - мой любимый вариант. Используйте оператора трубы и переходите от наименее важного к наиболее важному аспекту
dd1 <- dd %>%
arrange(z) %>%
arrange(desc(x))
Для полноты: вы также можете использовать функцию sortByCol() из пакета BBmisc:
library(BBmisc)
sortByCol(dd, c("z", "b"), asc = c(FALSE, TRUE))
b x y z
4 Low C 9 2
2 Med D 3 1
1 Hi A 8 1
3 Hi A 9 1
Сравнение производительности:
library(microbenchmark)
microbenchmark(sortByCol(dd, c("z", "b"), asc = c(FALSE, TRUE)), times = 100000)
median 202.878
library(plyr)
microbenchmark(arrange(dd,desc(z),b),times=100000)
median 148.758
microbenchmark(dd[with(dd, order(-z, b)), ], times = 100000)
median 115.872
-
3странно добавлять сравнение производительности, когда ваш метод самый медленный ... в любом случае сомнительно значение использования эталона для 4-рядного
data.frame
Как и механические карточные сортировщики давно, сначала сортируйте по наименее значащему ключу, затем следующему наиболее значимому и т.д. Никакой библиотеки не требуется, работает с любым количеством клавиш и любой комбинацией восходящих и нисходящих клавиш.
dd <- dd[order(dd$b, decreasing = FALSE),]
Теперь мы готовы сделать самый важный ключ. Сорт стабилен, и любые связи в наиболее значимом ключе уже решены.
dd <- dd[order(dd$z, decreasing = TRUE),]
Это может быть не самый быстрый, но, безусловно, простой и надежный
Другая альтернатива, использующая пакет rgr:
> library(rgr)
> gx.sort.df(dd, ~ -z+b)
b x y z
4 Low C 9 2
2 Med D 3 1
1 Hi A 8 1
3 Hi A 9 1
Я боролся с вышеуказанными решениями, когда хотел автоматизировать процесс заказа для n столбцов, имена столбцов которых могли каждый раз отличаться. Я нашел супер полезную функцию из пакета psych, чтобы сделать это простым способом:
dfOrder(myDf, columnIndices)
где columnIndices - это индексы одного или нескольких столбцов в том порядке, в котором вы хотите их отсортировать. Больше информации здесь:
Вы можете сделать это:
library(dplyr)
data<-data %>% arrange(data,columname)
Ещё вопросы
- 1Удалить текст из счетчика
- 1Удаление белой внутренней границы из выпадающего списка
- 0Хранить данные в базе данных даже удаляются на сайте
- 0Преобразуйте MySql InputStream в byte []
- 0Ошибка № 1064 в запросе SQL
- 1NetBeans не распознает импортированный класс
- 1Ошибка веб-службы Jboss Secure с использованием модуля входа в базу данных: сбой при вызове EJB
- 1аргументы во Фрагменте все еще нулевые
- 0c ++ getaddrinfo не обрабатывает большие URL
- 1Как преобразовать дату, которую пользователь выбирает в формате MM-дд-гггг, в формат гггг-мм-дд в Java
- 0Как настроить высоту угловых данных на основе данных
- 0Как выполнить модульное тестирование контроллера с обратным вызовом в AngularJS
- 0Получить параметры динамического выбора
- 1Повторение вызова метода
- 0указатели на многомерные массивы в классе
- 1Android - не удается обнаружить QR-код с библиотекой zxing
- 0Гиперссылки в TextBox / ListBox ASP.NET
- 1Группировать по numpy.mean
- 0DataGridview результат запроса 0
- 1Запись эквивалентного кода на Паскале в код C #
- 1Android-push-уведомление не работает на устройстве с 5.0 lollipop?
- 1Разделить текст из строки Java
- 1Не удается изменить InnerHTML класса span?
- 1как получить заказы из компонента ordertools в atg или как протестировать apl orderlookup droplet
- 1Что эквивалентно jasmine.createSpy (). And.callFake (fn) в sinonjs
- 0Как я могу заполнить HTML-таблицу из локального текстового файла?
- 0парсинг значения метки в jquery
- 0JavaScript, изменение изображения с анимацией
- 1D3 с пользовательским элементом: TypeError: t is null
- 0Как подключиться к серверу sql используя php в xampp
- 0Установка переменной в число на основе результата производной таблицы
- 0Использовать селекторы jQuery рекурсивно?
- 1Как сохранить urwid. Редактировать всегда в фокусе?
- 0Пользовательская тема Tumblr исчезает при выходе
- 1Создание прокручиваемого «графика» в c # (визуализация данных)
- 0проверка размера массива символов c ++
- 0Получить конкретный параметр URL
- 0Очистить разметку AngularJs
- 0Как сохранить пользовательский ввод в поле ввода? [HTML / AngularJS]
- 0Angularjs доступ к представлениям с прямым URL
- 1Как изменить цвет фона для определенных элементов виджета в RecycleView?
- 1Как принять неопределенное количество опций (и как запросить их имена / значения), используя инфраструктуру щелчка CLI?
- 0Алгоритм моделирования средних
- 1Как получить ArrayList из ArrayList.subList?
- 1D3 SVG с конечной высотой и шириной
- 1Как это сделать в C (из Java)
- 0ссылка на директиву angular js не может получить доступ к сгенерированному идентификатору элемента
- 0Пользовательский интерфейс jQuery и сортировка по горизонтали - элементы, перемещаемые влево при перетаскивании
- 1Копировать эмуляторы с другого ПК
