Как импортировать данные из файла CSV в таблицу PostgreSQL?
Как я могу написать хранимую процедуру, которая импортирует данные из файла CSV и заполняет таблицу?
-
14Почему хранимая процедура? COPY делает свое делоFrank Heikens
-
0У меня есть пользовательский интерфейс, который загружает файл CSV, чтобы подключить это мне нужна хранимая процедура, которая на самом деле копирует данные из файла CSVvardhan
12 ответов
Взгляните на короткую статью.
Решение перефразировано здесь:
Создайте таблицу:
CREATE TABLE zip_codes
(ZIP char(5), LATITUDE double precision, LONGITUDE double precision,
CITY varchar, STATE char(2), COUNTY varchar, ZIP_CLASS varchar);
Скопировать данные из файла CSV в таблицу:
COPY zip_codes FROM '/path/to/csv/ZIP_CODES.txt' WITH (FORMAT csv);
-
42фактически использование \ copy сделало бы тот же трюк, если у вас нет прав суперпользователя; это жалуется на мою Fedora 16 при использовании COPY с учетной записью без полномочий root.
-
79СОВЕТ: вы можете указать, какие столбцы у вас есть в CSV, используя zip_codes (col1, col2, col3). Столбцы должны быть перечислены в том же порядке, в котором они появляются в файле.
Если у вас нет разрешения на использование COPY (который работает на сервере db), вы можете вместо этого использовать \copy (который работает в клиенте db). Используя тот же пример, что и Божидар Бацов:
Создайте таблицу:
CREATE TABLE zip_codes
(ZIP char(5), LATITUDE double precision, LONGITUDE double precision,
CITY varchar, STATE char(2), COUNTY varchar, ZIP_CLASS varchar);
Скопировать данные из файла CSV в таблицу:
\copy zip_codes FROM '/path/to/csv/ZIP_CODES.txt' DELIMITER ',' CSV
Вы также можете указать столбцы для чтения:
\copy zip_codes(ZIP,CITY,STATE) FROM '/path/to/csv/ZIP_CODES.txt' DELIMITER ',' CSV
-
0\ копировать избирателей (ZIP, CITY) из '/Users/files/Downloads/WOOD.TXT' DELIMITER ',' CSV HEADER; ОШИБКА: дополнительные данные после последнего ожидаемого столбца КОНТЕКСТ: избиратели КОПИИ, строка 2: "OH0012781511,87,26953, ДОМАШНИЙ ХОЛДИНГ, ВЫСОКИЙ ,, 11/26 / 1965,08 / 19/1988, 211 N GARFIELD ST,, BLOOMD ...»
-
0@JZ. У меня была похожая ошибка. Это потому, что у меня были лишние пустые столбцы. Проверьте ваш CSV, и если у вас есть пустые столбцы, это может быть причиной.
Один быстрый способ сделать это с помощью библиотеки Python pandas (версия 0.15 или выше работает лучше всего). Это приведет к созданию столбцов для вас - хотя, очевидно, выбор, который он делает для типов данных, может быть не таким, каким вы хотите. Если это не совсем то, что вы хотите, вы всегда можете использовать код "create table", сгенерированный как шаблон.
Вот простой пример:
import pandas as pd
df = pd.read_csv('mypath.csv')
df.columns = [c.lower() for c in df.columns] #postgres doesn't like capitals or spaces
from sqlalchemy import create_engine
engine = create_engine('postgresql://username:password@localhost:5432/dbname')
df.to_sql("my_table_name", engine)
И вот какой код, который показывает вам, как установить различные параметры:
#Set is so the raw sql output is logged
import logging
logging.basicConfig()
logging.getLogger('sqlalchemy.engine').setLevel(logging.INFO)
df.to_sql("my_table_name2",
engine,
if_exists="append", #options are ‘fail’, ‘replace’, ‘append’, default ‘fail’
index=False, #Do not output the index of the dataframe
dtype={'col1': sqlalchemy.types.NUMERIC,
'col2': sqlalchemy.types.String}) #Datatypes should be [sqlalchemy types][1]
-
6Кроме того, параметр
if_existsможет быть установлен для замены или добавления к существующей таблице, например,df.to_sql("fhrs", engine, if_exists='replace') -
1имя пользователя и пароль: необходимо создать логин и назначить БД пользователю. Если используется pgAdmin, то создайте «Login / Group роль» с помощью графического интерфейса
Вы также можете использовать pgAdmin, который предлагает графический интерфейс для импорта. Это показано в этом потоке SO. Преимущество использования pgAdmin в том, что он также работает для удаленных баз данных.
Как и предыдущие решения, вам нужно будет иметь свою таблицу в базе данных уже. У каждого человека есть свое решение, но то, что я обычно делаю, это открыть CSV в Excel, скопировать заголовки, вставить специальные с транспозицией на другой рабочий лист, поместить соответствующий тип данных в следующий столбец, а затем просто скопировать и вставить его в текстовый редактор вместе с соответствующим запросом создания SQL-таблицы:
CREATE TABLE my_table (
/*paste data from Excel here for example ... */
col_1 bigint,
col_2 bigint,
/* ... */
col_n bigint
)
-
0Пожалуйста, покажите несколько образцов строк вставленных данных.
Как сказал Павел, импорт работает в pgAdmin:
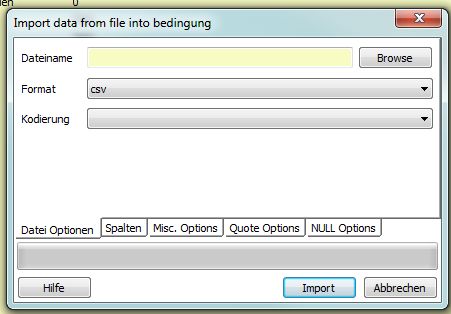
щелкните правой кнопкой мыши по таблице → import
выберите локальный файл, формат и кодирование
здесь представлен немецкий скриншот графического интерфейса пользователя pgAdmin:
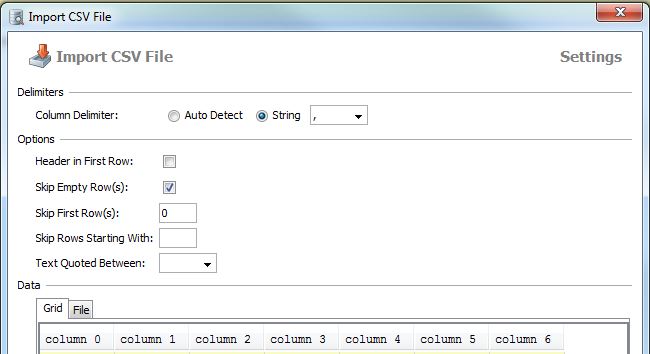
Аналогичная вещь, которую вы можете сделать с DbVisualizer (у меня есть лицензия, не уверенная о бесплатной версии)
щелкните правой кнопкой мыши по таблице → Импортировать данные таблицы...
-
2DBVisualizer занял 50 секунд, чтобы импортировать 1400 строк с тремя полями - и мне пришлось преобразовать все обратно из строки в ту, какой она должна была быть.
В большинстве других решений здесь требуется создать таблицу заранее/вручную. В некоторых случаях это может оказаться неприемлемым (например, если в таблице назначения много столбцов). Таким образом, подход ниже может пригодиться.
Предоставляя количество путей и столбцов вашего файла csv, вы можете использовать следующую функцию для загрузки таблицы в таблицу temp, которая будет называться как target_table:
Предполагается, что в верхней строке есть имена столбцов.
create or replace function data.load_csv_file
(
target_table text,
csv_path text,
col_count integer
)
returns void as $$
declare
iter integer; -- dummy integer to iterate columns with
col text; -- variable to keep the column name at each iteration
col_first text; -- first column name, e.g., top left corner on a csv file or spreadsheet
begin
set schema 'your-schema';
create table temp_table ();
-- add just enough number of columns
for iter in 1..col_count
loop
execute format('alter table temp_table add column col_%s text;', iter);
end loop;
-- copy the data from csv file
execute format('copy temp_table from %L with delimiter '','' quote ''"'' csv ', csv_path);
iter := 1;
col_first := (select col_1 from temp_table limit 1);
-- update the column names based on the first row which has the column names
for col in execute format('select unnest(string_to_array(trim(temp_table::text, ''()''), '','')) from temp_table where col_1 = %L', col_first)
loop
execute format('alter table temp_table rename column col_%s to %s', iter, col);
iter := iter + 1;
end loop;
-- delete the columns row
execute format('delete from temp_table where %s = %L', col_first, col_first);
-- change the temp table name to the name given as parameter, if not blank
if length(target_table) > 0 then
execute format('alter table temp_table rename to %I', target_table);
end if;
end;
$$ language plpgsql;
-
1Привет, Мехмет, спасибо за ответ, который ты написал, но когда я запускаю твой код, я получаю следующее сообщение об ошибке: ОШИБКА: схема "data" не существует
-
0user2867432 вам нужно изменить имя схемы, которое вы используете соответственно (например,
public)
COPY table_name FROM 'path/to/data.csv' DELIMITER ',' CSV HEADER;
Используйте этот код SQL
copy table_name(atribute1,attribute2,attribute3...)
from 'E:\test.csv' delimiter ',' csv header
ключевое слово заголовка позволяет СУБД знать, что файл csv имеет заголовок с атрибутами
для более подробной информации http://www.postgresqltutorial.com/import-csv-file-into-posgresql-table/
Личный опыт работы с PostgreSQL, все еще ждущий более быстрый способ.
1. Сначала создайте скелет таблицы, если файл хранится локально:
drop table if exists ur_table;
CREATE TABLE ur_table
(
id serial NOT NULL,
log_id numeric,
proc_code numeric,
date timestamp,
qty int,
name varchar,
price money
);
COPY
ur_table(id, log_id, proc_code, date, qty, name, price)
FROM '\path\xxx.csv' DELIMITER ',' CSV HEADER;
2. Когда \path\xxx.csv находится на сервере, postgreSQL не имеет разрешение на доступ к серверу, вам придется импортировать CSV файл через встроенные функции pgAdmin.
Щелкните правой кнопкой мыши имя таблицы, выберите импорт.
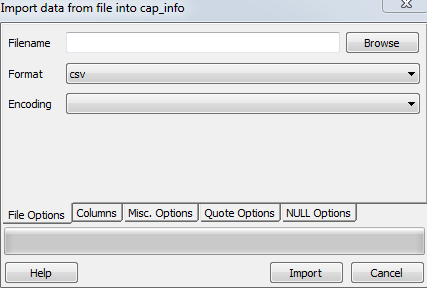
Если у вас все еще есть проблемы, обратитесь к этому руководству. http://www.postgresqltutorial.com/import-csv-file-into-posgresql-table/
IMHO, наиболее удобным способом является " Импортировать данные CSV в postgresql, удобный способ;-)", используя csvsql из csvkit, который является питоном пакет, устанавливаемый через pip.
-
2Ссылка гниль прожорлива! Статья, на которую вы ссылаетесь, больше не работает, что делает меня неудобным :(
-
0Вы могли бы упомянуть, что его зовут.
Создайте таблицу и введите необходимые столбцы, которые используются для создания таблицы в файле csv.
-
Откройте postgres и щелкните правой кнопкой мыши на целевой таблице, которую вы хотите загрузить, и выберите импорт и обновите следующие шаги в разделе параметры файла
-
Теперь просмотрите файл в имени файла
-
Выберите csv в формате
-
Кодирование как ISO_8859_5
Теперь перейти Разное. options и проверьте заголовок и нажмите на импорт.
Возможно, этот инструмент будет полезен http://www.convertcsv.com/csv-to-sql.htm Он имеет множество конфигурационных параметров для преобразования из CSV в базу данных script.
Ещё вопросы
- 1Как работает эта программа? Как работает метод firstGreaterEqual
- 0Об обработке исключений в C ++
- 0Получить значение атрибута внутри тега ввода с помощью JavaScript
- 0Как прочитать значения 2D массива в php
- 0Программирование структур данных C ++: передача значений по ссылке? [Дубликат]
- 0jquery настроить div при наведении на другой div
- 1Проблема визуализации простого графического интерфейса в Java
- 0Нужно img: парить, чтобы не повлиять на макет
- 0Обратные ссылки в PHP preg_replace () нестабильны?
- 1Несколько синхронизированных функций в одном потоке
- 0Зачем нужен $ timeout здесь?
- 0Программа C ++ не будет собираться. Получение неопределенных символов для ошибки архитектуры
- 0Ошибка: «Ответ» не был объявлен в этой области
- 0Использование отношений yii для получения данных по различным моделям
- 0UDP-сообщения продолжают поступать даже после остановки клиента или перезапуска сервера
- 1Расположение флажка в checkboxtableviewer по горизонтали в eclipse e4
- 0Передать параметр в URL в JavaScript
- 0erreur: не удалось преобразовать 'Cell <int> *' в 'List <int> *' в назначении
- 1Eclipse IDE ошибка компиляции
- 1Ошибка установки pip с проверкой сертификата SSL (_ssl.c: 833)
- 1Я не могу использовать более одного шрифта в Pygame
- 1Где разместить SwingUtilities.invokeLater в отдельном Java-приложении с поддержкой Spring?
- 1Загрузка файлов с помощью ExtJS и Jersey
- 0проблемы с поиском в базе данных, чтобы соответствовать вводу пользователя
- 1Как я могу убедиться, что все пакеты были получены и сохранены в массиве?
- 1IllegalThreadStateException при запуске потока
- 1Кодирование каждый раз производит разные хэши
- 0Выпадающий не показывает значение в IE
- 0LinkedStack и его шаблонный класс
- 0Причина, почему оператор = обычно возвращает ссылку на объект в C ++?
- 0Интеграция программы, написанной на C, с другой, написанной на C ++
- 0Как преобразовать результат хранимой процедуры MySQL в данные JSON в сценарии оболочки?
- 1Как усечь массив numpy?
- 1OSMnx Получить координаты Lat Lon чистых узлов пересечения
- 0ngModel передал через оболочку директиве child
- 0Динамический контроллер
- 0Как я могу сохранить $ location.hash () от добавления / сразу после #?
- 1Как запустить новый файл Node.js после того, как уже был запущен какой-либо другой файл Node.js. на компьютере с Windows 10?
- 1Как Node.js конвертирует ваш код в события?
- 1Javascript отображаемое имя div
- 1LocalDb в проекте asp.net требуют, чтобы некоторые конфигурации запускались на другой машине? VS2012
- 0Получение выбранного значения из выпадающего списка, помещенного в div
- 1Разрешить Java заканчиваться на main () без закрытия процессов, которые были выполнены exec ()
- 0Открытие локального файла XML в Google Chrome
- 0Как динамически настроить или изменить размер фонового изображения div в зависимости от размера контента
- 1Как изменить xaml AppBar на изменение PivotItem в Windows Phone 8.1
- 1ввод заменить символы при наборе текста?
- 0Есть ли способ добавить HTML-код в атрибут 'alt', используя fancybox?
- 1Всплывающее окно над экраном вызова в версии Android 7.0
- 0Jquery children () прозрачность анимации
