Почему использование alloca () не считается хорошей практикой?
alloca() выделяет память в стеке, а не в куче, как в случае malloc(). Поэтому, когда я возвращаюсь из рутины, память освобождается. Итак, на самом деле это решает мою проблему освобождения динамически распределенной памяти. Освобождение памяти, выделенной через malloc() является большой головной болью и, если ее пропустить, приводит к всевозможным проблемам с памятью.
Почему использование alloca() рекомендуется, несмотря на вышеуказанные функции?
-
31Просто быстрая заметка. Хотя эту функцию можно найти в большинстве компиляторов, она не требуется стандартом ANSI-C и, следовательно, может ограничивать переносимость. Другое дело, что вы не должны! free () указатель, который вы получаете, и он автоматически освобождается после выхода из функции.merkuro
-
0@meruko Хороший вопрос .. определенно влияет на портативностьVaibhav
25 ответов
Ответ прямо в man странице (по крайней мере на Linux):
ВОЗВРАЩАЕМОЕ ЗНАЧЕНИЕ Функция alloca() возвращает указатель на начало выделенного пространства. Если распределение вызывает переполнение стека, поведение программы не определено.
Что не означает, что его никогда не следует использовать. Один из проектов OSS, над которым я работаю, широко использует его, и если вы не злоупотребляете им (alloca огромные значения), это нормально. Когда вы пройдете отметку "несколько сотен байт", самое время использовать malloc и друзей. Вы все еще можете получить ошибки выделения, но, по крайней мере, у вас будет какое-то указание на ошибку, а не просто выброс стека.
-
27Таким образом, на самом деле нет никаких проблем с этим, которые вы бы не имели при объявлении больших массивов?
-
8@ Sean Я понимаю это, если я выделю слишком много памяти (поскольку пространство стека ограничено по сравнению с кучей), это приведет к переполнению; но то же самое относится и к локальному массиву. Если я останусь в своих пределах, тогда я буду в порядке, верно? Тогда также я все еще вижу анти-аллоа комментарии.
Одна из самых запоминающихся ошибок, которые у меня были, это сделать с встроенной функцией, которая использовала alloca. Он проявлялся как переполнение стека (потому что он выделяется в стеке) в случайных точках выполнения программы.
В файле заголовка:
void DoSomething() {
wchar_t* pStr = alloca(100);
//......
}
В файле реализации:
void Process() {
for (i = 0; i < 1000000; i++) {
DoSomething();
}
}
Итак, что произошло, была встроенная функция компилятора DoSomething, и все распределения стека выполнялись внутри функции Process() и, таким образом, выдували стек. В моей защите (и я не был тем, кто нашел этот вопрос, мне пришлось идти и кричать одному из старших разработчиков, когда я не мог это исправить), это было не прямо alloca, это было одним из Макросы преобразования строки ATL.
Итак, урок - не используйте alloca в функциях, которые, по вашему мнению, могут быть встроены.
-
71Интересно. Но разве это не квалифицируется как ошибка компилятора? В конце концов, встраивание изменило поведение кода (оно задержало освобождение пространства, выделенного с помощью alloca).
-
45По-видимому, по крайней мере GCC примет это во внимание: «Обратите внимание, что некоторые использования в определении функции могут сделать его непригодным для встроенной замены. Среди этих применений: использование varargs, использование alloca, [...]». gcc.gnu.org/onlinedocs/gcc/Inline.html
Старый вопрос, но никто не упомянул, что он должен быть заменен массивами переменной длины.
char arr[size];
вместо
char *arr=alloca(size);
Он в стандарте C99 и существовал как расширение компилятора во многих компиляторах.
-
5Это упоминается Джонатаном Леффлером в комментарии к ответу Артура Ульфельда.
-
1Действительно, но это также показывает, как легко это пропустить, так как я не видел его, несмотря на то, что прочитал все ответы перед публикацией.
alloca() очень полезна, если вы не можете использовать стандартную локальную переменную, потому что ее размер должен определяться во время выполнения, и вы можете абсолютно гарантировать, что указатель, который вы получаете от alloca(), НИКОГДА не будет использоваться после возвращения этой функции.
Вы можете быть достаточно безопасными, если вы
- не возвращайте указатель или все, что содержит его.
- не хранить указатель в любой структуре, выделенной в куче
- не позволяйте никому другому потоку использовать указатель
Настоящая опасность исходит из вероятности того, что кто-то другой нарушит эти условия когда-нибудь позже. Имея это в виду, отлично подходит для передачи буферов функциям, которые форматируют текст в них:)
-
11Функция VLA (массив переменной длины) в C99 поддерживает динамические локальные переменные без явного указания на использование alloca ().
-
2Neato! Более подробную информацию можно найти в разделе «3.4 Массив переменной длины» на сайте programmersheaven.com/2/Pointers-and-Arrays-page-2.
Как отмечено в этой публикации в новостной группе, есть несколько причин, по которым использование alloca можно считать сложным и опасным:
- Не все компиляторы поддерживают
alloca. - Некоторые компиляторы интерпретируют предполагаемое поведение
allocaпо-разному, поэтому переносимость не гарантируется даже между компиляторами, которые его поддерживают. - Некоторые реализации ошибочны.
-
23Одна вещь, о которой я упоминал в этой ссылке, которой нет нигде на этой странице, - это то, что функция, которая использует
alloca()требует отдельных регистров для хранения указателя стека и указателя кадра. На процессорах x86> = 386 указатель стекаESPможет использоваться для обоих, освобождаяEBP- если не используетсяalloca(). -
7Другим хорошим моментом на этой странице является то, что, если генератор кода компилятора не обрабатывает его как особый случай,
f(42, alloca(10), 43);может произойти сбой из-за вероятности того, что указатель стека отрегулирован с помощьюalloca()после того, как на него будетalloca()хотя бы один из аргументов.
Одна проблема заключается в том, что она не является стандартной, хотя широко поддерживается. При прочих равных условиях я бы всегда использовал стандартную функцию, а не распространенное расширение компилятора.
все еще alloca использование не рекомендуется, почему?
Я не воспринимаю такой консенсус. Множество сильных профи; несколько минусов:
- C99 предоставляет массивы переменной длины, которые часто используются предпочтительно, так как нотация, более согласованная с массивами фиксированной длины и интуитивно понятным общим
- у многих систем меньше всего объема памяти/адресного пространства для стека, чем у кучи, что делает программу немного более восприимчивой к исчерпанию памяти (через переполнение стека): это можно рассматривать как хорошее или плохое вещь - одна из причин, по которой стек не автоматически растет, как это делает куча, чтобы предотвратить неконтролируемое использование программ контроля над всей машиной.
- при использовании в более локальной области (например, в цикле
whileилиfor) или в нескольких областях памяти память накапливается на каждую итерацию/область действия и не освобождается до выхода функции: это контрастирует с определенными переменными в рамках структуры управления (например,for {int i = 0; i < 2; ++i) { X }будет накапливатьalloca-ed память, запрошенную в X, но память для массива фиксированного размера будет переработана на итерацию). - Современные компиляторы обычно не выполняют функции
inline, которые вызываютalloca, но если вы их заставляете, тоallocaпроизойдет в контексте вызывающих абонентов (т.е. стек не будет выпущен до тех пор, пока вызывающий абонент не вернется) - давно
allocaперешел из непереносимой функции/взлома в стандартизованное расширение, но некоторое негативное восприятие может сохраняться - время жизни привязано к области видимости функции, которая может или не подходит программисту лучше, чем
mallocявный контроль - чтобы использовать
malloc, побуждает думать об освобождении - если это управляется через функцию обертки (например,WonderfulObject_DestructorFree(ptr)), тогда функция предоставляет точку для операций очистки операций (например, закрытие дескрипторов файлов, освобождение внутренних указателей или выполнение некоторых протоколов) без явных изменений кода клиента: иногда это хорошая модель для последовательного принятия- в этом псевдо-OO-стиле программирования, естественно, хотеть что-то вроде
WonderfulObject* p = WonderfulObject_AllocConstructor();- это возможно, когда "конструктор" - это функция, возвращающая памятьmalloc-ed (поскольку память остается выделенной после того, как функция возвращает значение, которое должно быть сохранено вp), но не если "конструктор" используетalloca- макро-версия
WonderfulObject_AllocConstructorможет достичь этого, но "макросы являются злыми" в том, что они могут конфликтовать друг с другом и не-макрокодом и создавать непреднамеренные замены и, следовательно, трудно диагностировать проблемы.
- макро-версия
- Отсутствующие операции
freeмогут быть обнаружены ValGrind, Purify и т.д., но отсутствующие вызовы "деструктор" не всегда могут быть обнаружены вообще - одно очень незначительное преимущество с точки зрения обеспечения предполагаемого использования; в некоторых реализацияхalloca()(например, GCC) используется встроенный макрос дляalloca(), поэтому замещение библиотеки памяти для использования во время выполнения невозможно, как это делается дляmalloc/realloc/free( например, электрический забор).
- в этом псевдо-OO-стиле программирования, естественно, хотеть что-то вроде
- В некоторых реализациях есть тонкие проблемы: например, с man-страницы Linux:
Во многих системах alloca() не может использоваться внутри списка аргументов вызова функции, поскольку пространство стека, зарезервированное alloca(), будет отображаться в стеке в середине пространства для аргументов функции.
Я знаю, что этот вопрос отмечен C, но как программист на С++ я думал, что буду использовать С++ для иллюстрации потенциальной утилиты alloca: ниже приведен код (и здесь ideone) создает векторное отслеживание полиморфных типов разного размера, которые выделяются стеком (с привязкой к времени жизни к возврату функции), а не выделенной кучей.
#include <alloca.h>
#include <iostream>
#include <vector>
struct Base
{
virtual ~Base() { }
virtual int to_int() const = 0;
};
struct Integer : Base
{
Integer(int n) : n_(n) { }
int to_int() const { return n_; }
int n_;
};
struct Double : Base
{
Double(double n) : n_(n) { }
int to_int() const { return -n_; }
double n_;
};
inline Base* factory(double d) __attribute__((always_inline));
inline Base* factory(double d)
{
if ((double)(int)d != d)
return new (alloca(sizeof(Double))) Double(d);
else
return new (alloca(sizeof(Integer))) Integer(d);
}
int main()
{
std::vector<Base*> numbers;
numbers.push_back(factory(29.3));
numbers.push_back(factory(29));
numbers.push_back(factory(7.1));
numbers.push_back(factory(2));
numbers.push_back(factory(231.0));
for (std::vector<Base*>::const_iterator i = numbers.begin();
i != numbers.end(); ++i)
{
std::cout << *i << ' ' << (*i)->to_int() << '\n';
(*i)->~Base(); // optionally / else Undefined Behaviour iff the
// program depends on side effects of destructor
}
}
-
0+1 за упоминание C99 VLA
-
0нет +1 из-за подозрительного и необычного способа обработки нескольких типов :-(
Все уже указали на большую вещь, которая является потенциальным поведением undefined из, но я должен упомянуть, что в среде Windows есть большой механизм, чтобы поймать это, используя структурированные исключения (SEH) и защитные страницы. Поскольку стек растет только по мере необходимости, эти страницы защиты находятся в областях, которые нераспределены. Если вы выделяете в них (путем), генерируется исключение.
Вы можете поймать это исключение SEH и вызвать _resetstkoflw в reset стек и продолжить свой веселый путь. Это не идеальный, но другой механизм, по крайней мере, знать что-то пошло не так, когда материал попадает в вентилятор. * nix может иметь что-то подобное, о котором я не знаю.
Я рекомендую ограничить максимальный размер выделения, обернув alloca и отслеживая его внутренне. Если бы вы были очень хардкорны, вы могли бы бросить часовые прицелы в верхней части своей функции, чтобы отслеживать любые распределения alloca в области функций и здравомыслия, проверяя это на максимальную сумму, разрешенную для вашего проекта.
Кроме того, в дополнение к недопущению утечек памяти alloca не вызывает фрагментации памяти, что очень важно. Я не думаю, что alloca - это плохая практика, если вы используете ее разумно, что в принципе верно для всего.: -)
-
0Проблема в том, что
alloca()может требовать столько места, что указатель стека попадает в кучу. При этом злоумышленник, который может контролировать размер дляalloca()и данных, поступающих в этот буфер, может перезаписать кучу (что очень плохо).
Все остальные ответы верны. Однако, если вещь, которую вы хотите выделить с помощью alloca(), достаточно мала, я думаю, что это хорошая техника, которая быстрее и удобнее, чем использование malloc() или иначе.
Другими словами, alloca( 0x00ffffff ) опасен и может вызвать переполнение, ровно столько же, сколько char hugeArray[ 0x00ffffff ];. Будьте осторожны и разумны, и все будет хорошо.
Много интересных ответов на этот "старый" вопрос, даже некоторые относительно новые ответы, но я не нашел никаких упоминаний об этом.
При правильном использовании и осторожности последовательное использование
alloca()(возможно, для всего приложения) для обработки небольших распределений переменной длины (или C99 VLAs, если доступно) может привести к нижнему сумме роста, чем эквивалентная реализация, использующая негабаритные локальные массивы фиксированной длины. Поэтомуalloca()может быть хорошим для вашего стека, если вы его тщательно используете.
Я нашел эту цитату.... Хорошо, я сделал эту цитату. Но на самом деле, подумайте об этом....
@j_random_hacker очень прав в своих комментариях по другим ответам: избегать использования alloca() в пользу больших локальных массивов не делает вашу программу более безопасной из (если ваш компилятор не является достаточно старым, чтобы разрешить встраивание функций, которые используйте alloca(), в этом случае вы должны обновить или если вы не используете внутренние циклы alloca(), и в этом случае вы не должны использовать alloca() внутренние циклы).
Я работал на настольных/серверных средах и встраиваемых системах. Многие встроенные системы вообще не используют кучу (они даже не ссылаются на поддержку) по причинам, которые включают в себя восприятие того, что динамически распределенная память является злой из-за риска утечек памяти в приложении, которое никогда когда-либо перезагружается в течение многих лет за раз, или более разумное обоснование того, что динамическая память опасна, потому что неизвестно, что приложение никогда не будет фрагментировать свою кучу до уровня исчерпания ложной памяти. Поэтому встроенные программисты остались с несколькими альтернативами.
alloca() (или VLAs) может быть правильным инструментом для задания.
Я снова и снова видел, где программист создает буфер, распределенный по стекам, "достаточно большой для обработки любого возможного случая". В глубоко вложенном дереве вызовов повторное использование этого шаблона (anti-?) Приводит к преувеличенному использованию стека. (Представьте, что дерево вызовов 20 уровней глубоко, где на каждом уровне по разным причинам функция слепо перераспределяет буфер размером 1024 байта "только для того, чтобы быть в безопасности", когда обычно он будет использовать только 16 или меньше из них, и только в очень редкие случаи могут использовать больше.) Альтернативой является использование alloca() или VLA и выделение только столько места стека, сколько требуется вашей функции, чтобы избежать ненужного обременения стека. Надеемся, что когда одна функция в дереве вызовов нуждается в распределении большего, чем обычно, другие в дереве вызовов все еще используют свои обычные небольшие распределения, а общее использование стека приложений значительно меньше, чем если бы каждая функция вслепую чрезмерно распределяла локальный буфер.
Но если вы решите использовать alloca()...
На основании других ответов на этой странице кажется, что VLA должны быть безопасными (они не объединяют распределения стека, если они вызваны из цикла), но если вы используете alloca(), будьте осторожны, чтобы не использовать его внутри цикла и убедитесь, что ваша функция не может быть встроена, если есть вероятность, что она может быть вызвана в пределах другого цикла функций.
-
1Твердый смысл избегать повторных распределений в худшем случае ....
-
0Я согласен с этим пунктом. Опасность
alloca()верна, но то же самое можно сказать о утечках памяти с помощьюmalloc()(почему бы тогда не использовать GC? Можно поспорить).alloca()при осторожном использовании может быть очень полезна для уменьшения размера стека.
alloca() хорош и эффективен... но он также сильно нарушен.
- поведение с измененной областью (область действия вместо области блока)
- использовать несогласованный с malloc (alloca() Указанный указатель не должен быть освобожден, отныне вы должны отслеживать, где указатели идут от free() те, которые у вас есть с malloc())
- плохое поведение, когда вы также используете inlining (область действия иногда переходит к функции вызывающего абонента, зависящей от того, настроен ли запрос или нет).
- проверка границы стека
- undefined поведение в случае сбоя (не возвращает NULL, как malloc... и что означает отказ, поскольку он не проверяет границы стека в любом случае...)
- не ansi standard
В большинстве случаев вы можете заменить его, используя локальные переменные и размер мажоранты. Если он используется для больших объектов, их размещение в куче обычно является более безопасной идеей.
Если вам это действительно нужно, вы можете использовать VLA (нет vla на С++, слишком плохо). Они намного лучше, чем alloca() относительно поведения и согласованности области. Как я вижу, VLA - это своего рода alloca().
Конечно, локальная структура или массив, использующие мажоранту необходимого пространства, все же лучше, и если у вас нет такого распределения кучи мажоранты с использованием простого malloc(), вероятно, разумно. Я не вижу разумного варианта использования, когда вам действительно нужно либо alloca(), либо VLA.
-
0Я не вижу причины понижения (без комментариев, кстати)
-
0Только имена имеют область.
allocaне создает имя, только диапазон памяти, который имеет время жизни .
Вот почему:
char x;
char *y=malloc(1);
char *z=alloca(&x-y);
*z = 1;
Не то, чтобы кто-нибудь написал этот код, но аргумент размера, который вы передаете в alloca, почти наверняка исходит из какого-то ввода, который может злонамеренно стремиться к тому, чтобы ваша программа была alloca что-то такое огромное. В конце концов, если размер не основан на вводе или не имеет возможности быть большим, почему вы просто не объявили небольшой локальный буфер фиксированного размера?
Практически весь код с использованием alloca и/или C99 vlas имеет серьезные ошибки, которые приведут к сбоям (если вам повезет) или к компрометации привилегий (если вам не повезло).
-
2Downvoter, хотите прокомментировать?
-
1Мир может никогда не узнать. :( Тем не менее, я надеюсь, что вы могли бы уточнить мой вопрос о
alloca. Вы сказали, что почти во всем коде, в котором он используется, есть ошибка, но я планировал ее использовать; обычно я игнорировал бы такое утверждение, но Исходя из вас, я не буду. Я пишу виртуальную машину, и я хотел бы выделить переменные, которые не выходят из функции в стеке, а не динамически, из-за огромного ускорения. Альтернативный подход, который имеет те же характеристики производительности? Я знаю, что могу приблизиться к пулам памяти, но это все же не так дешево. Что бы вы сделали?
Место, где alloca() особенно опасно, чем malloc() - ядро - ядро типичной операционной системы имеет фиксированное пространство стека, жестко закодированное в один из его заголовков; он не такой гибкий, как стек приложения. Выполнение вызова alloca() с неоправданным размером может привести к сбою ядра.
Некоторые компиляторы предупреждают об использовании alloca() (и даже VLA, если на то пошло) при определенных параметрах, которые должны быть включены при компиляции кода ядра. Здесь лучше выделять память в куче, которая не фиксируется жесткой конфигурацией, закодированный предел.
-
6
alloca()не более опасна, чемint foo[bar];гдеbar- произвольное целое число.
Одна ловушка с alloca - это то, что longjmp перематывает его.
То есть, если вы сохраняете контекст с помощью setjmp, затем alloca некоторую память, а затем longjmp для контекста, вы можете потерять память alloca (без какого-либо уведомления). Указатель стека возвращается туда, где он был, и поэтому память больше не резервируется; если вы вызываете функцию или делаете другой alloca, вы закроете исходный alloca.
Чтобы прояснить, что я конкретно имею в виду, это ситуация, когда longjmp не возвращается из функции, где происходил alloca ! Скорее функция сохраняет контекст с помощью setjmp; затем выделяет память с помощью alloca и, наконец, в этом контексте выполняется longjmp. Эта функция alloca память не все освобождены; просто вся память, которую он выделил начиная с setjmp. Конечно, я говорю о наблюдаемом поведении; такое требование не документировано любой alloca, что я знаю.
В документации основное внимание обычно уделяется концепции, что alloca памяти связано с активацией функции, а не с каким-либо блоком; что многочисленные вызовы alloca просто захватывают больше стековой памяти, которая освобождается после завершения функции. Не так; память фактически связана с контекстом процедуры. Когда контекст восстанавливается с помощью longjmp, то же происходит и с предыдущим состоянием alloca. Это является следствием того, что сам регистр указателя стека используется для распределения, а также (обязательно) сохраняется и восстанавливается в jmp_buf.
Между прочим, это, если оно работает таким образом, обеспечивает правдоподобный механизм для преднамеренного освобождения памяти, которая была выделена с помощью alloca.
Я столкнулся с этим как основной причиной ошибки.
-
0Это то, что он должен делать -
longjmpвозвращается и делает так, что программа забывает обо всем, что произошло в стеке: все переменные, вызовы функций и т. Д. Аallocaподобна массиву в стеке, поэтому ожидается, что они будут быть забитым, как и все остальное в стеке. -
0
man allocaдал следующее предложение: «Поскольку пространство, выделенное alloca (), выделяется в кадре стека, это пространство автоматически освобождается, если при возврате функции вызывается longjmp (3) или siglongjmp (3)». , Таким образом, задокументировано, что память, выделенная с помощьюallocaстановится засоренной послеlongjmp.
Я не думаю, что кто-то упомянул об этом: Использование функции alloca в функции будет препятствовать или отключать некоторые оптимизации, которые в противном случае могли бы применяться в функции, поскольку компилятор не может знать размер фрейма стека функций.
Например, общая оптимизация компиляторами C заключается в том, чтобы исключить использование указателя фрейма внутри функции, вместо этого образы кадров сделаны относительно указателя стека; поэтому есть еще один регистр для общего использования. Но если alloca вызывается внутри функции, разница между sp и fp будет неизвестна для части функции, поэтому эта оптимизация не может быть выполнена.
Учитывая редкость его использования и его теневой статус как стандартной функции, разработчики компилятора вполне могут отключить любую оптимизацию, которая может вызвать проблемы с alloca, если бы потребовалось больше усилий, чтобы заставить ее работать с alloca.
Если вы случайно напишите за пределами блока, выделенного с помощью alloca (из-за переполнения буфера, например), вы перезапишите обратный адрес своей функции, потому что он находится "сверху" в стеке, то есть после ваш выделенный блок.
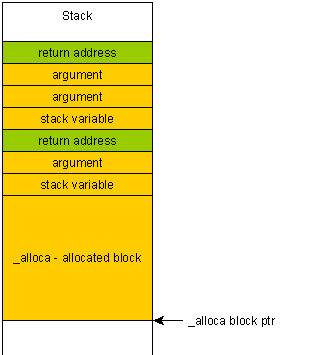
Следствием этого является двукратное:
-
Программа будет аварийно завершена, и невозможно будет понять, почему или где она разбилась (стек, скорее всего, отключится от случайного адреса из-за перезаписанного указателя кадра).
-
Это делает переполнение буфера во много раз более опасным, так как злонамеренный пользователь может создать специальную полезную нагрузку, которая будет помещена в стек, и поэтому может быть выполнена.
В отличие от этого, если вы пишете над блоком в куче, вы "просто" получаете кучу коррупции. Программа, вероятно, неожиданно завершится, но будет правильно раскручивать стек, тем самым уменьшив вероятность выполнения вредоносного кода.
-
6Ничто в этой ситуации кардинально не отличается от опасностей переполнения буфера в буфере, выделенном стеком фиксированного размера. Эта опасность не уникальна для
alloca. -
2Конечно, нет. Но, пожалуйста, проверьте оригинальный вопрос. Вопрос в том, что представляет опасность для
allocaпо сравнению сmalloc(таким образом, это не буфер фиксированного размера в стеке).
К сожалению, действительно удивительный alloca() отсутствует в почти потрясающей tcc. У Gcc есть alloca().
-
Он сеет семя своего собственного разрушения. С возвратом в качестве деструктора.
-
Как и
malloc(), он возвращает недопустимый указатель на fail, который будет segfault на современных системах с MMU (и, надеюсь, перезапустить их без). -
В отличие от автоматических переменных вы можете указать размер во время выполнения.
Это хорошо работает с рекурсией. Вы можете использовать статические переменные для достижения чего-то подобного хвостовой рекурсии и использовать только несколько других, чтобы передавать информацию на каждую итерацию.
Если вы нажимаете слишком глубоко, вы уверены в segfault (если у вас есть MMU).
Обратите внимание, что malloc() не предлагает больше, поскольку возвращает NULL (который также будет segfault, если он назначен), когда система не работает. То есть все, что вы можете сделать, это залог или просто попытаться назначить его любым способом.
Чтобы использовать malloc(), я использую глобальные переменные и назначаю их NULL. Если указатель не равен NULL, я освобожу его, прежде чем использовать malloc().
Вы также можете использовать realloc() в качестве общего случая, если хотите скопировать любые существующие данные. Перед тем, как работать, вам нужно проверить указатель, если вы собираетесь копировать или конкатенировать после realloc().
-
3На самом деле спецификация alloca не говорит, что возвращает неверный указатель при сбое (переполнение стека), она говорит, что имеет неопределенное поведение ... и для malloc она говорит, что возвращает NULL, а не случайный неверный указатель (ОК, оптимистичная реализация памяти в Linux делает это бесполезный).
-
0@kriss Linux может убить ваш процесс, но, по крайней мере, он не рискует неопределенным поведением
Процессы имеют ограниченное количество пространства стека - намного меньше объема памяти, доступного для malloc().
Используя alloca(), вы значительно увеличите свои шансы получить ошибку (если вам повезет или необъяснимый сбой, если вы этого не сделали).
Фактически, alloca не гарантирует использование стека. В самом деле реализация gcc-2.95 alloca выделяет память из кучи, используя сам malloc. Кроме того, эта реализация глючит, это может привести к утечке памяти и к неожиданному поведению, если вы вызовете ее внутри блока с дальнейшим использованием goto. Нет, чтобы сказать, что вы никогда не должны использовать его, но несколько раз alloca приводит к большему количеству накладных расходов, чем он отходит от него.
-
0Похоже, что gcc-2.95 сломал alloca и, вероятно, не может быть безопасно использован для программ, которые требуют
alloca. Как бы это очистило память, когдаlongjmpиспользуется, чтобы отказаться от кадров, которые сделалиalloca? Когда кто-нибудь сегодня использует gcc 2.95?
Не очень красиво, но если производительность действительно имеет значение, вы можете предварительно выделить некоторое пространство в стеке.
Если у вас уже есть максимальный размер блока памяти, и вы хотите сохранить проверку переполнения, вы можете сделать что-то вроде:
void f()
{
char array_on_stack[ MAX_BYTES_TO_ALLOCATE ];
SomeType *p = (SomeType *)array;
(...)
}
-
12Гарантируется ли правильное выравнивание массива char для любого типа данных? Alloca дает такое обещание.
-
0@ JuhoÖstman: вы можете использовать массив struct (или любого другого типа) вместо char, если у вас есть проблемы с выравниванием.
Я не думаю, что кто-то упоминал об этом, но у alloca также есть некоторые серьезные проблемы с безопасностью, которые не обязательно присутствуют в malloc (хотя эти проблемы также возникают с любыми массивами на основе стека, динамическими или нет). Так как память выделяется в стеке, переполнение/переполнение буфера имеет гораздо более серьезные последствия, чем просто malloc.
В частности, адрес возврата для функции хранится в стеке. Если это значение будет повреждено, ваш код может быть перемещен в любую исполняемую область памяти. Компиляторы делают все возможное, чтобы сделать это трудным (в частности, путем рандомизации размещения адресов). Тем не менее, это явно хуже, чем просто переполнение стека, так как лучший случай - SEGFAULT, если возвращаемое значение повреждено, но он также может начать выполнять случайный фрагмент памяти или в худшем случае некоторую область памяти, которая ставит под угрозу безопасность вашей программы.,
Большинство ответов здесь в значительной степени упущены: причина, по которой использование _alloca() потенциально хуже, чем просто хранение больших объектов в стеке.
Основное различие между автоматическим хранилищем и _alloca() заключается в том, что последний страдает от дополнительной (серьезной) проблемы: выделенный блок не контролируется компилятором, поэтому компилятор не может оптимизировать или перерабатывать его.
Для сравнения:
while (condition) {
char buffer[0x100]; // Chill.
/* ... */
}
с:
while (condition) {
char* buffer = _alloca(0x100); // Bad!
/* ... */
}
Проблема с последним должна быть очевидной.
-
0Есть ли у вас практические примеры, демонстрирующие разницу между VLA и
alloca(да, я действительно говорю VLA, потому чтоalloca- это больше, чем просто создатель массивов статического размера)? -
0Есть варианты использования для второго, который первый не поддерживает. Я могу захотеть иметь n записей после того, как цикл будет выполнен n раз - возможно, в связанном списке или дереве; эта структура данных затем удаляется, когда функция в конце концов возвращается. Нельзя сказать, что я бы что-нибудь кодировал таким образом :-)
По-моему, alloca(), где доступно, следует использовать только ограниченным образом. Очень похоже на использование "goto", довольно много других разумных людей испытывают сильное отвращение не только к использованию, но и к существованию alloca().
Для встроенного использования, когда размер стека известен, и ограничения могут быть навязаны посредством соглашения и анализа по размеру распределения и где компилятор не может быть обновлен для поддержки C99 +, использование alloca() в порядке, и я как известно, использовали его.
Когда доступно, VLA могут иметь некоторые преимущества перед alloca(): компилятор может генерировать ограничения на лимит стека, которые будут захватывать доступ к ограничениям при использовании доступа к стилю массива (я не знаю, делают ли какие-либо компиляторы это, но это можно сделать), и анализ кода может определить, правильно ли ограничены выражения доступа к массиву. Обратите внимание, что в некоторых средах программирования, таких как автомобильная, медицинская техника и авионика, этот анализ необходимо проводить даже для массивов фиксированного размера, как автоматического (в стеке), так и статического распределения (глобального или локального).
В архитектурах, в которых хранятся как данные, так и обратные адреса/указатели фреймов в стеке (из того, что я знаю, что все они), любая назначенная стеком переменная может быть опасной, поскольку адрес переменной может быть взят и непроверенный ввод ценности могут допускать всевозможные озорства.
Портативность менее опасна во встроенном пространстве, однако это хороший аргумент против использования alloca() вне тщательно контролируемых условий.
Вне встроенного пространства я использовал alloca() в основном внутри функций ведения журналов и форматирования для эффективности и в нерекурсивном лексическом сканере, где временные структуры (выделенные с помощью alloca() создаются во время токенизации и классификации, то перед возвратом функции сохраняется постоянный объект (выделенный через malloc()). Использование alloca() для небольших временных структур значительно уменьшает фрагментацию, когда выделяется постоянный объект.
Функция alloca велика, и все скептики просто распространяют FUD.
void foo()
{
int x = 50000;
char array[x];
char *parray = (char *)alloca(x);
}
Массив и парсер являются ТОЧНО одинаковыми с ТОЧНО теми же рисками. Говорить один лучше другого - это синтаксический выбор, а не технический.
Как для выбора переменных стека против переменных кучи, существует много преимуществ для долгосрочных программ, использующих стек над кучей для переменных с временными сроками действия. Вы избегаете фрагментации кучи, и вы можете избежать роста пространства процесса с неиспользуемым (непригодным) кучевым пространством. Вам не нужно его чистить. Вы можете контролировать распределение стека в процессе.
Почему это плохо?
ИМХО, alloca считается плохой практикой, потому что все боятся исчерпать ограничение размера стека.
Я многому научился, прочитав этот поток и некоторые другие ссылки:
- https://unix.stackexchange.com/questions/63742/what-is-automatic-stack-expansion
- Ограничение распределения стека для программ на 32-битной машине Linux
- ulimit -s
Я использую alloca в основном для того, чтобы сделать мои простые файлы C компилируемыми на msvc и gcc без каких-либо изменений, стиль C89, no #ifdef _MSC_VER и т.д.
Спасибо! Этот поток заставил меня зарегистрироваться на этом сайте:)
-
0Имейте в виду, что на этом сайте нет такого понятия, как «ветка». Переполнение стека имеет формат вопросов и ответов, а не формат цепочки обсуждений. «Ответить» не похоже на «Ответить» в дискуссионном форуме; это означает, что вы фактически даете ответ на вопрос и не должны использоваться для ответа на другие ответы или для комментариев по теме. Если у вас есть хотя бы 50 повторений, вы можете оставлять комментарии , но обязательно прочитайте «Когда я не должен комментировать?» раздел. Пожалуйста, прочитайте страницу « О нас», чтобы лучше понять формат сайта.
Ещё вопросы
- 0Почему у меня возникают проблемы с изменением курсоров мыши в моей реализации интерактивного QGraphicsView в Qt?
- 1Игнорируйте отсутствующие изображения в SVG с данными D3 и введите методы [дубликаты]
- 0Как включить кусок кода Java внутри HTML-тега в шаблон игрового фреймворка?
- 0Лучший способ для двух последовательных таблиц SELECT
- 0Присвойте значение к URL-адресу JSON при установке флажка и автоматически обновите JSON
- 0Изображение после sql результата Combobox PHP
- 0Функция AngularJS ng-click не работает после содержимого информационного окна $ compile map
- 0Перенести значение из выпадающего в текстовое поле
- 0Spring boot schema.sql не работает с файлом mysqldump
- 1Webscraping с запросами, возвращающими родительскую веб-страницу HTML
- 0Как снять угловой наблюдатель с направляющего элемента?
- 0Управление памятью с помощью std :: vector <Eigen :: MatrixXd>
- 1Декомпрессия ZLib
- 1преобразовать гггг-дд-мм в гггг-мм-дд в Python
- 1Java: удаление компонента Runnable Canvas
- 0Изменение переменной контроллера с завода. AngularJS
- 0Ищем CSS столбцы ALA Газета / ms-word, для контента - столбец 1 сверху вниз, затем перенос в столбец 2, сверху вниз
- 0Как использовать угловой повтор с ng-grid и щелкнуть мышью?
- 1Горизонтальное ограничение зрения в ConstraintLayout
- 1Как найти имена файлов внутри каталогов в Python, используя regexp
- 0центрировать несколько вложенных тегов div в одном теге контейнера div
- 0Как получить ID оборудования в Java и C ++
- 1Как конфертировать из ICollection в IEnumerable?
- 0Ошибка сегментации: 11 при использовании форсированного мьютекса
- 1PrintWriter удаляет старое содержимое текстового файла при записи
- 0Данные успешно удалены из БД, но не обновили текущую страницу в AngularJS
- 0Передача объекта и получение возвращаемого значения из вызова потока
- 0Получить текст из строки столбца
- 0Динамический метатег с angularJS
- 1Пользовательские элементы управления ASP.Net совместно используются несколькими проектами
- 0привязка к объекту iframe или html5
- 1Приложения Сценарии авторизации OAuth2 с использованием гэппи из HtmlService
- 0(JS) вызывает внешнюю функцию .js с тегом <script>
- 0анимация на виде позвоночника
- 1Связь супервизора в шторме 0.9.0.1 с Netty
- 1Можно ли передать HTML в таблицу прокрутки в Gojs?
- 0pouchdb не определяется в приложении angularjs
- 0почему это JQuery не добавляет правильные значения в моей БД
- 0`ngAnimate` - проблема интеграции
- 0получение данных от угловой JS
- 0PHP Echo не включает межстрочный интервал
- 0AngularJS Routing с несколькими атрибутами URL
- 1Веб-приложения White Label
- 1Создать «курсор» в середине слова
- 1Как вызвать метод в другом классе из универсального метода?
- 0Какой лучший способ Yii получить данные из 2 таблиц?
- 1ffmpeg не работает с именем файла, есть пробел
- 0Проверка успешности, ошибок и полных статусов в скрипте ajax
- 0сумма полей в разных идентификаторах
