Регулярное выражение для соответствия строке, которая не содержит слова?
Я знаю, что можно совместить слово, а затем разворачивать спички, используя другие инструменты (например, grep -v). Тем не менее, я хотел бы знать, возможно ли совпадение строк, которые не содержат конкретного слова (например, hede), с использованием регулярного выражения.
Input:
hoho
hihi
haha
hede
код:
grep "<Regex for 'doesn't contain hede'>" input
Требуемый вывод:
hoho
hihi
haha
28 ответов
Понятие о том, что регулярное выражение не поддерживает обратное совпадение, не совсем верно. Вы можете имитировать это поведение, используя негативные образы:
^((?!hede).)*$
Регулярное выражение выше будет соответствовать любой строке или строке без разрыва строки, не, содержащей (под) строку 'hede'. Как уже упоминалось, это не то, что регулярное выражение "хорошо" (или должно делать), но все же возможно.
И если вам нужно также совместить символы разрыва строки, используйте модификатор DOT-ALL (конечный s в следующем шаблоне ):
/^((?!hede).)*$/s
или используйте его в строке:
/(?s)^((?!hede).)*$/
(где /.../ являются разделителями регулярных выражений, т.е. не являются частью шаблона)
Если модификатор DOT-ALL недоступен, вы можете имитировать такое же поведение с классом символов [\s\S]:
/^((?!hede)[\s\S])*$/
Описание
Строка - это всего лишь список символов n. До и после каждого символа есть пустая строка. Таким образом, список символов n будет содержать n+1 пустые строки. Рассмотрим строку "ABhedeCD":
┌──┬───┬──┬───┬──┬───┬──┬───┬──┬───┬──┬───┬──┬───┬──┬───┬──┐
S = │e1│ A │e2│ B │e3│ h │e4│ e │e5│ d │e6│ e │e7│ C │e8│ D │e9│
└──┴───┴──┴───┴──┴───┴──┴───┴──┴───┴──┴───┴──┴───┴──┴───┴──┘
index 0 1 2 3 4 5 6 7
где e - это пустые строки. Регулярное выражение (?!hede). смотрит вперед, чтобы увидеть, нет ли подстроки "hede", и если это так (так что что-то еще видно), то . (точка) будет соответствовать любому символу, кроме разрыва строки, Look-arounds также называются утверждениями с нулевой шириной, потому что они не потребляют никаких символов. Они только утверждают/проверяют что-то.
Итак, в моем примере каждая пустая строка сначала проверяется, чтобы увидеть, нет ли "hede" впереди, прежде чем символ будет потребляться . (точка). Регулярное выражение (?!hede). будет делать это только один раз, поэтому оно завернуто в группу и повторяется ноль или более раз: ((?!hede).)*. Наконец, начало и конец ввода привязаны, чтобы убедиться, что весь вход потреблен: ^((?!hede).)*$
Как вы можете видеть, вход "ABhedeCD" завершится с ошибкой, потому что на e3 не выполняется повторное выражение (?!hede) (впереди есть "hede"!).
-
21Я бы не сказал, что это плохо для регулярных выражений. Удобство этого решения довольно очевидно, и снижение производительности по сравнению с программным поиском часто оказывается несущественным.
-
19Строго говоря, отрицательный перебор делает регулярное выражение нерегулярным.
Обратите внимание, что решение не начинается с "hede" :
^(?!hede).*$
как правило, намного эффективнее, чем решение не содержит "hede" :
^((?!hede).)*$
Первая проверяет "hede" только на первой позиции входных строк, а не на каждой позиции.
-
4Спасибо, я использовал его для проверки того, что строка не содержит последовательность цифр ^ ((?! \ D {5,}).) *
-
0
^((?!hede).)*$работал на меня, используя плагин jQuery DataTable, чтобы исключить строку из набора данных
Если вы просто используете его для grep, вы можете использовать grep -v hede для получения всех строк, которые не содержат hede.
ETA О, перечитав вопрос, grep -v, вероятно, вы подразумеваете под "инструментальными опциями".
-
18Совет: для постепенной фильтрации того, что вам не нужно: grep -v "hede" | grep -v "хихи" | ...так далее.
-
43Или используя только один процесс
grep -v -e hede -e hihi -e ...
Ответ:
^((?!hede).)*$
Объяснение:
^ начало строки,
( и захватить до \1 (0 или более раз (сопоставление максимально возможной суммы)), (?! Посмотрите вперед, чтобы увидеть, нет ли этого,
hede ваша строка,
) конец ожидания,
. любой символ кроме \n, )* end of\1 (Примечание: поскольку вы используете квантификатор для этого захвата, только LAST повторение захваченного шаблона будет сохранено в \1) $ перед необязательным \n, а конец строки
-
13здорово, что у меня
^((?!DSAU_PW8882WEB2|DSAU_PW8884WEB2|DSAU_PW8884WEB).)*$в возвышенном тексте 2, используя несколько слов '^((?!DSAU_PW8882WEB2|DSAU_PW8884WEB2|DSAU_PW8884WEB).)*$' -
2@DamodarBashyal Я знаю, что я довольно поздно здесь, но вы можете полностью удалить второй срок там, и вы получите точно такие же результаты
Данные ответы совершенно прекрасные, просто академические точки:
Регулярные выражения в значении теоретических компьютерных наук НЕ ДОЛЖНЫ делать это так. Для них это должно было выглядеть примерно так:
^([^h].*$)|(h([^e].*$|$))|(he([^h].*$|$))|(heh([^e].*$|$))|(hehe.+$)
Это соответствует только FULL. Выполнение этого для вспомогательных матчей было бы еще более неудобным.
-
1Важно отметить, что в нем используются только основные регулярные выражения POSIX.2, и поэтому он более переносим, когда PCRE недоступен.
-
5Согласен. Многие, если не большинство регулярных выражений, не являются регулярными языками и не могут быть распознаны конечными автоматами.
Здесь хорошее объяснение, почему нелегко свести на нет произвольное регулярное выражение. Я должен согласиться с другими ответами, хотя: если это что-то другое, кроме гипотетического вопроса, тогда регулярное выражение здесь не является правильным выбором.
-
10Некоторые инструменты, в частности mysqldumpslow, предлагают только такой способ фильтрации данных, поэтому в таком случае поиск регулярного выражения для этого является лучшим решением, кроме переписывания инструмента (различные исправления для этого не включены в MySQL AB / Sun). Оракул.
-
1Точно аналогично моей ситуации. Шаблонный движок Velocity использует регулярные выражения, чтобы решить, когда применять преобразование (escape html), и я хочу, чтобы он всегда работал, КРОМЕ в одной ситуации.
Если вы хотите, чтобы тест регулярного выражения завершился неудачей, только если вся строка совпадает, будет работать следующее:
^(?!hede$).*
Например, если вы хотите разрешить все значения, кроме "foo" (то есть "foofoo", "barfoo" и "foobar" пройдут, но "foo" завершится ошибкой), используйте: ^(?!foo$).*
Конечно, если вы проверяете точное равенство, лучшим общим решением в этом случае является проверка на равенство строк, т.е.
myStr !== 'foo'
Вы могли бы даже поставить отрицание вне теста, если вам нужны какие-либо функции регулярных выражений (здесь, нечувствительность к регистру и соответствие диапазона):
!/^[a-f]oo$/i.test(myStr)
Однако решение regex в верхней части этого ответа может быть полезным в ситуациях, когда требуется положительный тест regex (возможно, через API).
-
0как насчет конечных пробелов? Например, если я хочу, чтобы проверка
" hede "неудачей со строкой" hede "? -
0@eagor директива
\sсоответствует одному символу пробела
FWIW, поскольку регулярные языки (ака рациональные языки) замкнуты относительно дополнения, всегда можно найти регулярное выражение (aka рациональное выражение), которое отрицает другое выражение. Но это не так много инструментов.
Vcsn поддерживает этот оператор (который он обозначает {c}, postfix).
Сначала вы определяете тип своих выражений: ярлыки - буква (lal_char) для выбора из a в z например (определение алфавита при работе с дополнением, конечно, очень важно), а "значение", рассчитанное для каждого слова, просто логическое: true слово принято, false, отклонено.
В Python:
In [5]: import vcsn
c = vcsn.context('lal_char(a-z), b')
c
Out[5]: {a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z} → ?
то вы вводите свое выражение:
In [6]: e = c.expression('(hede){c}'); e
Out[6]: (hede)^c
преобразуйте это выражение в автомат:
In [7]: a = e.automaton(); a
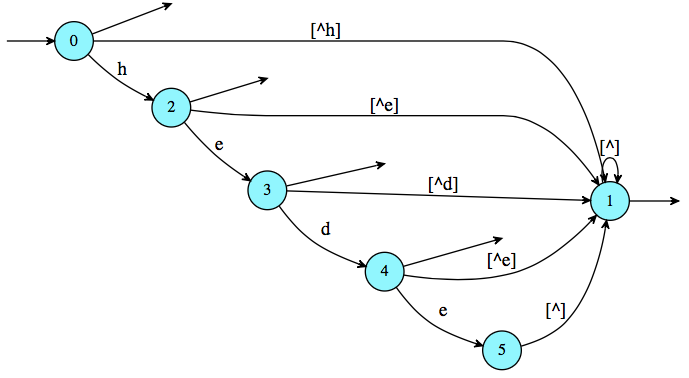
наконец, преобразуем этот автомат обратно в простое выражение.
In [8]: print(a.expression())
\e+h(\e+e(\e+d))+([^h]+h([^e]+e([^d]+d([^e]+e[^]))))[^]*
где + обычно обозначается | , \e обозначает пустое слово, а [^] обычно записывается . (любой символ). Итак, с немного переписыванием ()|h(ed?)?|([^h]|h([^e]|e([^d]|d([^e]|e.)))).*.
Вы можете увидеть этот пример здесь, и попробовать VCSN онлайн там.
-
5Правда, но некрасиво и выполнимо только для небольших наборов символов. Вы не хотите делать это со строками Unicode :-)
-
0Есть больше инструментов, которые позволяют это, одним из самых впечатляющих является Ragel . Там это будет записано как (any * - ('hehe' any *)) для начального совпадения или (any * - ('hehe' any *)) для невыровненного.
Бенчмарки
Я решил оценить некоторые из представленных опций и сравнить их производительность, а также использовать некоторые новые функции. Бенчмаркинг в .NET Regex Engine: http://regexhero.net/tester/
Контрольный текст:
Первые 7 строк не должны совпадать, так как они содержат искомое выражение, в то время как нижние 7 строк должны совпадать!
Regex Hero is a real-time online Silverlight Regular Expression Tester.
XRegex Hero is a real-time online Silverlight Regular Expression Tester.
Regex HeroRegex HeroRegex HeroRegex HeroRegex Hero is a real-time online Silverlight Regular Expression Tester.
Regex Her Regex Her Regex Her Regex Her Regex Her Regex Her Regex Hero is a real-time online Silverlight Regular Expression Tester.
Regex Her is a real-time online Silverlight Regular Expression Tester.Regex Hero
egex Hero egex Hero egex Hero egex Hero egex Hero egex Hero Regex Hero is a real-time online Silverlight Regular Expression Tester.
RRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRegex Hero is a real-time online Silverlight Regular Expression Tester.
Regex Her
egex Hero
egex Hero is a real-time online Silverlight Regular Expression Tester.
Regex Her is a real-time online Silverlight Regular Expression Tester.
Regex Her Regex Her Regex Her Regex Her Regex Her Regex Her is a real-time online Silverlight Regular Expression Tester.
Nobody is a real-time online Silverlight Regular Expression Tester.
Regex Her o egex Hero Regex Hero Reg ex Hero is a real-time online Silverlight Regular Expression Tester.
Результаты:
Результаты - Итерации в секунду в качестве медианы из 3 прогонов - Большее число = лучше
01: ^((?!Regex Hero).)*$ 3.914 // Accepted Answer
02: ^(?:(?!Regex Hero).)*$ 5.034 // With Non-Capturing group
03: ^(?>[^R]+|R(?!egex Hero))*$ 6.137 // Lookahead only on the right first letter
04: ^(?>(?:.*?Regex Hero)?)^.*$ 7.426 // Match the word and check if you're still at linestart
05: ^(?(?=.*?Regex Hero)(?#fail)|.*)$ 7.371 // Logic Branch: Find Regex Hero? match nothing, else anything
P1: ^(?(?=.*?Regex Hero)(*FAIL)|(*ACCEPT)) ????? // Logic Branch in Perl - Quick FAIL
P2: .*?Regex Hero(*COMMIT)(*FAIL)|(*ACCEPT) ????? // Direct COMMIT & FAIL in Perl
Так как .NET не поддерживает действие Глаголы (* FAIL и т.д.), я не смог проверить решения P1 и P2.
Резюме:
Я попытался протестировать большинство предлагаемых решений, некоторые оптимизации возможны для определенных слов.
Например, если первые две буквы строки поиска не совпадают, ответ 03 может быть расширен до
^(?>[^R]+|R+(?!egex Hero))*$, что приводит к небольшому усилению производительности.
Но общее наиболее читаемое и быстродействующее решение, похоже, имеет значение 05, используя условное выражение или 04 с вероятным квантором. Я думаю, что решения Perl должны быть еще быстрее и более легко читаемыми.
-
4Тебе тоже нужно время
^(?!.*hede). /// Кроме того, вероятно, лучше ранжировать выражения для совпадающего и несовпадающего корпусов по отдельности, потому что это обычно тот случай, когда большинство совпадений строк или большинство строк этого не делают.
С отрицательным взглядом регулярное выражение может соответствовать тому, что не содержит определенного шаблона. Об этом отвечает и объясняет Барт Кирс. Отличное объяснение!
Тем не менее, с ответом Барта Кирса, контрольная часть будет проверять от 1 до 4 символов вперед при сопоставлении любого отдельного символа. Мы можем избежать этого и позволить обзорной части проверить весь текст, гарантировать, что нет "hede" , а затем нормальная часть (. *) Может съесть весь текст за один раз.
Вот улучшенное регулярное выражение:
/^(?!.*?hede).*$/
Обратите внимание, что (*?) ленивый квантификатор в отрицательной части обзора необязателен, вместо этого вы можете использовать (*) жадный квантификатор, в зависимости от ваших данных: если "hede" присутствует и в начале половины текста, ленивый квантификатор может быть быстрее; в противном случае, жадный квантор будет быстрее. Однако, если "hede" не присутствует, оба будут равными медленными.
Вот демон-код .
Для получения дополнительной информации о lookahead, посмотрите отличную статью: Освоение Lookahead и Lookbehind.
Кроме того, ознакомьтесь с RegexGen.js, генератором регулярных выражений JavaScript, который помогает создавать сложные регулярные выражения. С помощью RegexGen.js вы можете создать регулярное выражение более читаемым образом:
var _ = regexGen;
var regex = _(
_.startOfLine(),
_.anything().notContains( // match anything that not contains:
_.anything().lazy(), 'hede' // zero or more chars that followed by 'hede',
// i.e., anything contains 'hede'
),
_.endOfLine()
);
-
3поэтому просто проверьте, не содержит ли данная строка строки str1 и str2:
^(?!.*(str1|str2)).*$ -
1Да, или вы можете использовать ленивый квантификатор:
^(?!.*?(?:str1|str2)).*$, В зависимости от ваших данных. Добавил?:как нам не нужно его захватывать.
Не регулярное выражение, но я нашел логичным и полезным использовать последовательные greps с трубкой для устранения шума.
например. искать конфигурационный файл apache без комментариев -
grep -v '\#' /opt/lampp/etc/httpd.conf # this gives all the non-comment lines
и
grep -v '\#' /opt/lampp/etc/httpd.conf | grep -i dir
Логика последовательного grep (не комментарий) и (соответствует dir)
-
2Я думаю, что он запрашивает регулярную версию
grep -v -
9Это опасно Также пропускает строки вроде
good_stuff #comment_stuff
при этом вы избегаете проверки взглядов на каждую позицию:
/^(?:[^h]+|h++(?!ede))*+$/
эквивалент (для.net):
^(?>(?:[^h]+|h+(?!ede))*)$
Старый ответ:
/^(?>[^h]+|h+(?!ede))*$/
-
7Хорошая точка зрения; Я удивлен, что никто не упомянул этот подход раньше. Тем не менее, это конкретное регулярное выражение склонно к катастрофическому откату назад применительно к тексту, который не соответствует. Вот как бы я это сделал:
/^[^h]*(?:h+(?!ede)[^h]*)*$/ -
0... или вы можете просто сделать все квантификаторы притяжательными. ;)
Вот как бы я это сделал:
^[^h]*(h(?!ede)[^h]*)*$
Точный и эффективный, чем другие ответы. Он реализует технику эффективности "разворачивания в петлю" Friedl и требует гораздо меньшего возврата.
Вышеупомянутый (?:(?!hede).)* велик, потому что он может быть привязан.
^(?:(?!hede).)*$ # A line without hede
foo(?:(?!hede).)*bar # foo followed by bar, without hede between them
Но в этом случае достаточно:
^(?!.*hede) # A line without hede
Это упрощение готово к добавлению предложений "И":
^(?!.*hede)(?=.*foo)(?=.*bar) # A line with foo and bar, but without hede
^(?!.*hede)(?=.*foo).*bar # Same
Если вы хотите совместить символ, чтобы отменить слово, аналогичное классу отрицательных символов:
Например, строка:
<?
$str="aaa bbb4 aaa bbb7";
?>
Не использовать:
<?
preg_match('/aaa[^bbb]+?bbb7/s', $str, $matches);
?>
Использование:
<?
preg_match('/aaa(?:(?!bbb).)+?bbb7/s', $str, $matches);
?>
Примечание "(?!bbb)." не является ни lookbehind, ни lookahead, он выглядит как текущий, например:
"(?=abc)abcde", "(?!abc)abcde"
-
3В регулярном выражении Perl нет «lookcurrent». Это действительно отрицательный прогноз (префикс
(?!). Положительный префикс Lookahead будет(?=то время как соответствующие префиксы lookbehind будут(?<!И(?<=Соответственно). Предварительный просмотр означает, что вы читаете следующие символы (следовательно, «Вперед»), не потребляя их. Взгляд назад означает, что вы проверяете уже использованные символы.
В OP не указывалось или Tag сообщение, указывающее контекст (язык программирования, редактор, инструмент), в котором будет использоваться Regex.
Для меня иногда требуется сделать это, редактируя файл с помощью Textpad.
Textpad поддерживает некоторое Regex, но не поддерживает lookahead или lookbehind, поэтому требуется несколько шагов.
Если я хочу сохранить все строки, что НЕ содержит строку hede, я бы сделал это следующим образом:
1. Найдите/замените весь файл, чтобы добавить уникальный "тег" в начало каждой строки, содержащей любой текст.
Search string:^(.)
Replace string:<@#-unique-#@>\1
Replace-all
2. Удалите все строки, содержащие строку
hede(строка замены пуста):
Search string:<@#-unique-#@>.*hede.*\n
Replace string:<nothing>
Replace-all
3. На этом этапе все оставшиеся строки NOT содержат строку
hede. Удалите уникальный "тег" со всех строк (строка замены пуста):
Search string:<@#-unique-#@>
Replace string:<nothing>
Replace-all
Теперь у вас есть исходный текст со всеми строками, содержащими строку hede.
Если я ищу Do Something Else только строки, в которых NOT содержит строку hede, я бы сделал это следующим образом:
1. Найдите/замените весь файл, чтобы добавить уникальный "тег" в начало каждой строки, содержащей любой текст.
Search string:^(.)
Replace string:<@#-unique-#@>\1
Replace-all
2. Для всех строк, содержащих строку
hede, удалите уникальный "тег" :
Search string:<@#-unique-#@>(.*hede)
Replace string:\1
Replace-all
3. На этом этапе все строки, начинающиеся с уникального "тега", NOT содержат строку
hede. Теперь я могу сделать свой Something Else только для этих строк.
4. Когда я закончил, я удаляю уникальный "тег" со всех строк (строка замены пуста):
Search string:<@#-unique-#@>
Replace string:<nothing>
Replace-all
-
0хаха - я использовал замену всего, это простой трюк.
С момента введения ruby-2.4.1 мы можем использовать новый Absent Operator в регулярных выражениях Rubys
из официального doc
(?~abc) matches: "", "ab", "aab", "cccc", etc.
It doesn't match: "abc", "aabc", "ccccabc", etc.
Таким образом, в вашем случае ^(?~hede)$ выполняется задание для вас
2.4.1 :016 > ["hoho", "hihi", "haha", "hede"].select{|s| /^(?~hede)$/.match(s)}
=> ["hoho", "hihi", "haha"]
Через глагол PCRE (*SKIP)(*F)
^hede$(*SKIP)(*F)|^.*$
Это полностью пропустит строку, которая содержит точную строку hede и соответствует всем оставшимся строкам.
Выполнение частей:
Рассмотрим приведенное выше регулярное выражение, разделив его на две части.
-
Часть перед символом
|. Часть не должна совпадать.^hede$(*SKIP)(*F) -
Часть после символа
|. Часть должна быть сопоставлена .^.*$
ЧАСТЬ 1
Механизм Regex начнет выполнение с первой части.
^hede$(*SKIP)(*F)
Объяснение:
-
^Утверждается, что мы находимся в начале. -
hedeСоответствует строкеhede -
$Указывает, что мы находимся на конце строки.
Таким образом, строка, содержащая строку hede, будет сопоставлена. Как только механизм регулярных выражений увидит следующий (*SKIP)(*F) (Примечание: вы можете написать (*F) как (*FAIL)) глагол, он пропустит и сделает совпадение неудачным. | называется изменением или логическим оператором OR, добавленным рядом с глаголом PCRE, который inturn соответствует всем границам, существующим между каждым символом во всех строках, за исключением того, что строка содержит точную строку hede. См. Демонстрацию здесь. То есть, он пытается сопоставить символы из оставшейся строки. Теперь будет выполняться регулярное выражение во второй части.
ЧАСТЬ 2
^.*$
Объяснение:
-
^Утверждается, что мы находимся в начале. т.е. он соответствует всем путям строк, кроме одного в строкеhede. См. Демонстрацию здесь. -
.*В многострочном режиме.будет соответствовать любому символу, кроме символов новой строки или символа возврата каретки. И*повторит предыдущий символ ноль или более раз. Таким образом,.*будет соответствовать всей строке. См. Демонстрацию здесь.Привет, почему вы добавили. * вместо. +?
Потому что
.*будет соответствовать пустой строке, но.+не будет соответствовать пробелу. Мы хотим сопоставить все строки, кромеhede, может быть возможность пустых строк также на входе. поэтому вы должны использовать.*вместо.+..+повторял предыдущий символ один или несколько раз. См..*соответствует пустой строке здесь. -
$Здесь не требуется завершение привязки линии.
Поскольку никто другой не дал прямого ответа на заданный вопрос, я сделаю это.
Ответ заключается в том, что с POSIX grep невозможно буквально удовлетворить этот запрос:
grep "Regex for doesn't contain hede" Input
Причина в том, что POSIX grep требуется только для работы с Basic Regular Expressions, которые просто недостаточно эффективны для выполнения этой задачи (они не способны анализировать обычные языки из-за отсутствия чередования и группировки).
Однако GNU grep реализует расширения, которые позволяют это. В частности, \| является оператором чередования в реализации GNU BRE, а \( и \) - операторы группировки. Если ваш механизм регулярных выражений поддерживает чередование, отрицательные выражения скобок, группировку и звезду Kleene и способен привязывать к началу и концу строки, все, что вам нужно для этого подхода.
С GNU grep было бы что-то вроде:
grep "^\([^h]\|h\(h\|eh\|edh\)*\([^eh]\|e[^dh]\|ed[^eh]\)\)*\(\|h\(h\|eh\|edh\)*\(\|e\|ed\)\)$" Input
(найденный с Grail и некоторые дальнейшие оптимизации, сделанные вручную).
Вы также можете использовать инструмент, который реализует расширенные регулярные выражения, например egrep, для устранения обратных косых черт:
egrep "^([^h]|h(h|eh|edh)*([^eh]|e[^dh]|ed[^eh]))*(|h(h|eh|edh)*(|e|ed))$" Input
Вот скрипт для его проверки (обратите внимание, что он генерирует файл testinput.txt в текущем каталоге):
#!/bin/bash
REGEX="^\([^h]\|h\(h\|eh\|edh\)*\([^eh]\|e[^dh]\|ed[^eh]\)\)*\(\|h\(h\|eh\|edh\)*\(\|e\|ed\)\)$"
# First four lines as in OP testcase.
cat > testinput.txt <<EOF
hoho
hihi
haha
hede
h
he
ah
head
ahead
ahed
aheda
ahede
hhede
hehede
hedhede
hehehehehehedehehe
hedecidedthat
EOF
diff -s -u <(grep -v hede testinput.txt) <(grep "$REGEX" testinput.txt)
В моей системе он печатает:
Files /dev/fd/63 and /dev/fd/62 are identical
как и ожидалось.
Для тех, кто интересуется деталями, применяемая техника состоит в том, чтобы преобразовать регулярное выражение, которое соответствует слову, в конечный автомат, а затем инвертировать автомат, изменив каждое состояние принятия на непринятие и наоборот, а затем преобразуя полученную FA обратно в регулярное выражение.
Наконец, как все отметили, если ваш механизм регулярных выражений поддерживает негативный взгляд, это значительно упрощает задачу. Например, с GNU grep:
grep -P '^((?!hede).)*$' Input
Обновление: Недавно я нашел отличную библиотеку FormalTheory от Kendall Hopkins, написанную на PHP, которая обеспечивает функциональность, похожую на Grail. Используя это и упроститель, написанный мной, я смог написать онлайн-генератор отрицательных регулярных выражений с учетом входной фразы (только буквенно-цифровые и пробельные символы, которые в настоящее время поддерживаются): http://www.formauri.es/personal/pgimeno/разное/неигровые-регулярное выражение /
Для hede он выводит:
^([^h]|h(h|e(h|dh))*([^eh]|e([^dh]|d[^eh])))*(h(h|e(h|dh))*(ed?)?)?$
что эквивалентно приведенному выше.
Он может быть более поддерживаемым для двух регулярных выражений в вашем коде, один для первого совпадения, а затем, если он совпадает с run, второе регулярное выражение проверяет наличие случаев, которые вы хотите заблокировать, например, ^.*(hede).*, затем имеет соответствующую логику в ваш код.
Хорошо, я признаю, что на самом деле это не ответ на опубликованный вопрос, и он может также использовать немного больше обработки, чем одно регулярное выражение. Но для разработчиков, которые пришли сюда, чтобы найти быстрое исправление для случая превышения, это решение не следует упускать из виду.
Язык TXR поддерживает отрицание регулярных выражений.
$ txr -c '@(repeat)
@{nothede /~hede/}
@(do (put-line nothede))
@(end)' Input
Более сложный пример: сопоставьте все строки, которые начинаются с a и заканчиваются на z, но не содержат подстроку hede:
$ txr -c '@(repeat)
@{nothede /a.*z&~.*hede.*/}
@(do (put-line nothede))
@(end)' -
az <- echoed
az
abcz <- echoed
abcz
abhederz <- not echoed; contains hede
ahedez <- not echoed; contains hede
ace <- not echoed; does not end in z
ahedz <- echoed
ahedz
Отрицание регулярных выражений не особенно полезно само по себе, но когда у вас также есть пересечение, вещи становятся интересными, поскольку у вас есть полный набор операций с булевыми множествами: вы можете выразить "множество, которое соответствует этому, за исключением вещей, которые соответствуют этому".
-
0Обратите внимание, что это также решение для регулярного выражения ElasticSearch на основе Lucene.
Функция ниже поможет вам получить желаемый результат
<?PHP
function removePrepositions($text){
$propositions=array('/\bfor\b/i','/\bthe\b/i');
if( count($propositions) > 0 ) {
foreach($propositions as $exceptionPhrase) {
$text = preg_replace($exceptionPhrase, '', trim($text));
}
$retval = trim($text);
}
return $retval;
}
?>
На мой взгляд, более читаемый вариант верхнего ответа:
^(?!.*hede)
По сути, "сопоставлять в начале строки тогда и только тогда, когда в ней нет слова" хеде "", поэтому требование почти напрямую переводится в регулярное выражение.
Конечно, это может иметь несколько требований отказа:
^(?!.*(hede|hodo|hada))
Детали: Якорь ^ гарантирует, что механизм регулярных выражений не повторяет совпадение в каждом месте строки, что соответствует каждой строке.
Якорь ^ в начале предназначен для обозначения начала строки. Инструмент grep сопоставляет каждую строку по одной за раз, в тех случаях, когда вы работаете с многострочной строкой, вы можете использовать флаг "m":
/^(?!.*hede)/m # JavaScript syntax
или же
(?m)^(?!.*hede) # Inline flag
С помощью ConyEdit вы можете использовать командную строку cc.gl ! /hede/ для получения строк, которые не содержат соответствия регулярных выражений, или используйте командную строку cc.dl/hede/ для удаления строк, содержащих соответствие регулярных выражений. Они имеют одинаковый результат.
Я не понимаю потребности в сложном регулярном выражении или даже взглядах:
/hede|^(.*)$/gm
Не помещайте в группу захвата вещь, которую вы не хотите, но используйте ее для всего остального. Это будет соответствовать всем строкам, которые не содержат "hede".
Возможно, вы найдете это в Google, пытаясь написать регулярное выражение, которое может соответствовать сегментам строки (в отличие от целых строк), которые не содержат подстроку. Поймайте мне время, чтобы разобраться, поэтому я поделюсь:
Учитывая строку: <span class="good">bar</span><span class="bad">foo</span><span class="ugly">baz</span>
Я хочу сопоставить теги <span> которые не содержат подстроку "bad".
/<span(?:(?!bad).)*?> будет соответствовать <span class=\"good\"> и <span class=\"ugly\">.
Обратите внимание, что есть два набора (слоев) круглых скобок:
- Самый внутренний - для негативного взгляда (это не группа захвата)
- Самый внешний интерпретируемый Ruby как группа захвата, но мы не хотим, чтобы он был группой захвата, поэтому я добавил?: При этом он начинается и больше не интерпретируется как группа захвата.
Демо в Ruby:
s = '<span class="good">bar</span><span class="bad">foo</span><span class="ugly">baz</span>'
s.scan(/<span(?:(?!bad).)*?>/)
# => ["<span class=\"good\">", "<span class=\"ugly\">"]
Как использовать контрольные глаголы PCRE backtracking для соответствия строке, не содержащей слова
Вот метод, который я раньше не видел:
/.*hede(*COMMIT)^|/
Как это работает
Сначала он пытается найти "hede" где-то в строке. В случае успеха (*COMMIT) в этот момент указывает движку не только не возвращаться в случае сбоя, но и не пытаться выполнить дальнейшее сопоставление в этом случае. Затем мы пытаемся сопоставить то, что не может совпадать (в данном случае ^).
Если строка не содержит "hede", вторая альтернатива, пустой подшаблон, успешно соответствует теме.
Этот метод не более эффективен, чем негативный взгляд, но я решил, что просто брошу его здесь, если кто-то найдет его отличным и найдет для него использование для других, более интересных приложений.
Более простым решением является использование неоператора !
Ваш оператор if должен соответствовать "содержит" и не соответствует "исключает".
var contains = /abc/;
var excludes =/hede/;
if(string.match(contains) && !(string.match(excludes))){ //proceed...
Я считаю, что дизайнеры RegEx предполагали использование не операторов.
Ещё вопросы
- 0Вставка латинских символов в mysql с использованием php?
- 0PHP submit обновляет страницу и принимает идентификатор отправки в качестве параметра
- 0проверить, существует ли запись (PDO)
- 0Как зарегистрировать новый модуль в Zend Framework 2
- 1Импорт pcap на малину
- 1Подсчитать количество экземпляров строки в очень большом массиве и добавить значение к значению хеша
- 1изменить данные XML в C #
- 1Читайте целочисленные значения через Reader. (Sql-сервер)
- 0как убрать абсолютную позицию с помощью jquery?
- 1Почему Process.Start отображает окно с сообщением об ошибке, хотя я перенаправляю стандартную ошибку?
- 1Ошибка Stackoverflow при рекурсивном поиске в дереве
- 1Ударьте или пропустите морфологию в python, чтобы найти структуры в изображениях, не дает требуемых результатов
- 0Сортировка массива структур
- 0Почему контроллер не вызывается, когда я вручную перезагружаю страницу? И как это исправить?
- 1Чем Process.Start отличается от Пуск> Выполнить?
- 1удаленная отладка Visual Studio 2010: запустить внешнюю программу: каталог не существует
- 0Определите, какой элемент является первым, и сделайте это
- 0C ++ создает расширяемый массив с использованием указателей
- 1Таймеры перезапускаются «для петель»? Я пытаюсь сделать таймер, чтобы панель циклически перебирала 5 разных цветов через заданный интервал времени.
- 0Создана форма регистрации и входа с php и mysql, и ошибка не работает в форме регистрации
- 1изменить корневой контекст приложения Vaadin 7
- 1Редактировать изображения в файле PDF с помощью объекта COSStream
- 1Угадай номер игры в Java
- 0Невозможно отобразить php на html-странице
- 0Работа с XML-файлом и PHP
- 1Angular UrlResolver не переопределяется пользовательским провайдером
- 1Как я могу включить в своем коде код actionListener для нажатия кнопки для извлечения данных, введенных в графический интерфейс для нескольких частей кода?
- 0Контент в моем iframe не кликабелен в Chrome, но работает в IE
- 0Вызов Jquery из сервлета
- 0jQuery UI прерывает CSS
- 1Java помощь относительно циклов
- 0как интегрировать soap xml api с веб-сервисом в php
- 1Внутри класса доступ к значениям словаря в одной функции из другой
- 0Uncaught исключение «PDOException» с сообщением «не удалось найти драйвер» (для базы данных Oracle)
- 0css первая буква исключить другие теги
- 1Сбой сборки Oreo 8.1 boringssl для принудительного режима FIPS
- 0Как глубоко скопировать конструктор с уникальным указателем внутри класса шаблона?
- 0Увеличивайте скорость animate () с каждым кликом ()
- 0как выбрать таблицу по метке th с помощью jquery
- 0как переписать URL в Yii?
- 1Firebase отстает с обновлением данных - многопользовательская игра
- 0Как я могу использовать jQuery для обновления поля в моей модели рельсов?
- 0используйте qt c ++, установите местоположение вручную и создайте файл
- 1Как создать персонализированный токен пользователя музыки в Apple Music?
- 0Центрирование растрового текста в прямоугольнике с помощью OpenGL
- 1Как создать несколько элементов в разных местах, используя методы DOM
- 0Экспресс не получает данные от angularjs
- 0Конвертировать Mikrotik Datetime в Mysql Date Time
- 0Пул объектов - создание объектов позже не работает
- 0Передача данных между 2 окнами. Qt

([^h]*(h([^e]|$)|he([^d]|$)|hed([^e]|$)))*? Идея проста. Продолжайте сопоставлять до тех пор, пока не увидите начало нежелательной строки, а затем сопоставляйте только в N-1 случаях, когда строка не завершена (где N - длина строки). Этими случаями N-1 являются «h, за которыми следует не-e», «он следует за не-d» и «hed, за которым следует не-e». Если вам удалось пропустить эти случаи N-1, вы не соответствовали нежелательной строке, поэтому вы можете снова начать поиск[^h]*