Кластерный анализ в R: определить оптимальное количество кластеров
Будучи новичком в R, я не очень уверен, как выбрать лучшее количество кластеров для анализа k-средств. После построения подмножества данных ниже, сколько кластеров будет подходящим? Как выполнить анализ кластерного дендро?
n = 1000
kk = 10
x1 = runif(kk)
y1 = runif(kk)
z1 = runif(kk)
x4 = sample(x1,length(x1))
y4 = sample(y1,length(y1))
randObs <- function()
{
ix = sample( 1:length(x4), 1 )
iy = sample( 1:length(y4), 1 )
rx = rnorm( 1, x4[ix], runif(1)/8 )
ry = rnorm( 1, y4[ix], runif(1)/8 )
return( c(rx,ry) )
}
x = c()
y = c()
for ( k in 1:n )
{
rPair = randObs()
x = c( x, rPair[1] )
y = c( y, rPair[2] )
}
z <- rnorm(n)
d <- data.frame( x, y, z )
7 ответов
Если ваш вопрос how can I determine how many clusters are appropriate for a kmeans analysis of my data?, то вот несколько вариантов. В статье wikipedia об определении количества кластеров есть хороший обзор некоторых из этих методов.
Во-первых, некоторые воспроизводимые данные (данные в Q... неясны для меня):
n = 100
g = 6
set.seed(g)
d <- data.frame(x = unlist(lapply(1:g, function(i) rnorm(n/g, runif(1)*i^2))),
y = unlist(lapply(1:g, function(i) rnorm(n/g, runif(1)*i^2))))
plot(d)
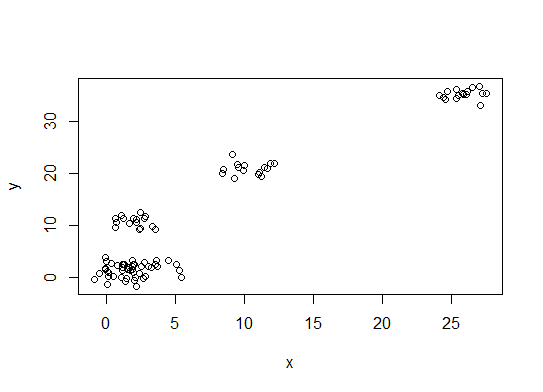
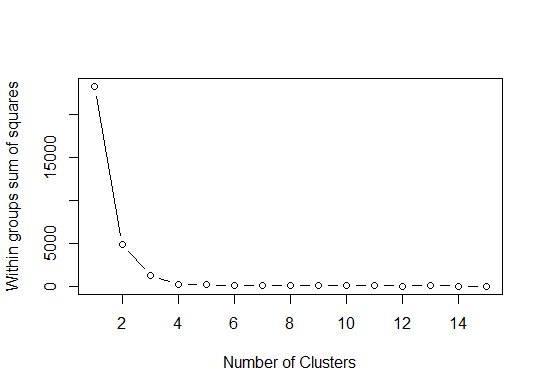
One. Посмотрите на изгиб или локоть в сумме кривой scree error (SSE). Подробнее см. http://www.statmethods.net/advstats/cluster.html и http://www.mattpeeples.net/kmeans.html. Расположение локтя в полученном графике предполагает подходящее количество кластеров для километров:
mydata <- d
wss <- (nrow(mydata)-1)*sum(apply(mydata,2,var))
for (i in 2:15) wss[i] <- sum(kmeans(mydata,
centers=i)$withinss)
plot(1:15, wss, type="b", xlab="Number of Clusters",
ylab="Within groups sum of squares")
Мы можем заключить, что этим кластером будет указан 4 кластера:
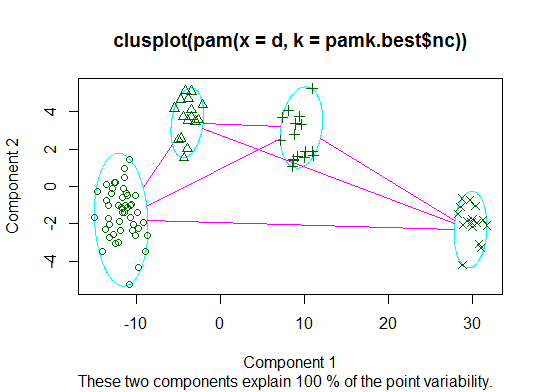
Два. Вы можете сделать разбиение по медоидам, чтобы оценить количество кластеров, используя функцию pamk в пакете fpc.
library(fpc)
pamk.best <- pamk(d)
cat("number of clusters estimated by optimum average silhouette width:", pamk.best$nc, "\n")
plot(pam(d, pamk.best$nc))
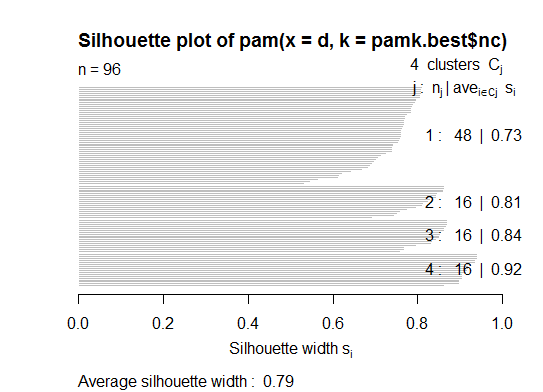
# we could also do:
library(fpc)
asw <- numeric(20)
for (k in 2:20)
asw[[k]] <- pam(d, k) $ silinfo $ avg.width
k.best <- which.max(asw)
cat("silhouette-optimal number of clusters:", k.best, "\n")
# still 4
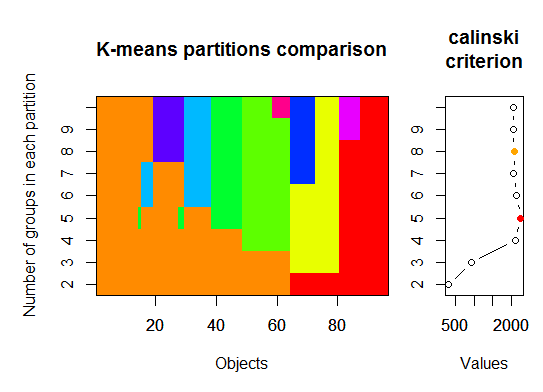
Три. Критерий Калинского: Другой подход к диагностике того, сколько кластеров соответствует данным. В этом случае мы пробуем от 1 до 10 групп.
require(vegan)
fit <- cascadeKM(scale(d, center = TRUE, scale = TRUE), 1, 10, iter = 1000)
plot(fit, sortg = TRUE, grpmts.plot = TRUE)
calinski.best <- as.numeric(which.max(fit$results[2,]))
cat("Calinski criterion optimal number of clusters:", calinski.best, "\n")
# 5 clusters!
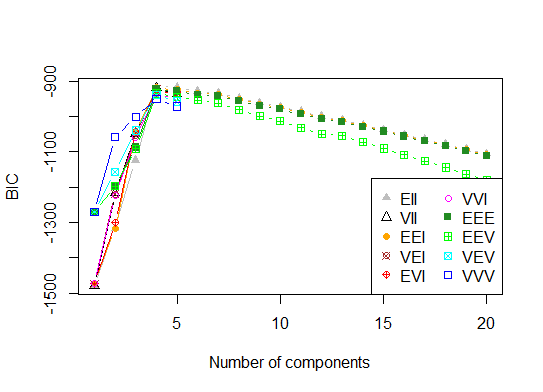
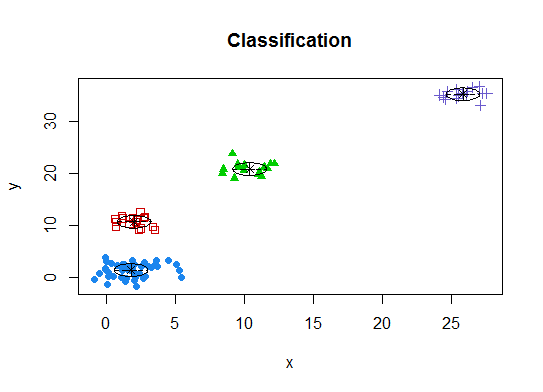
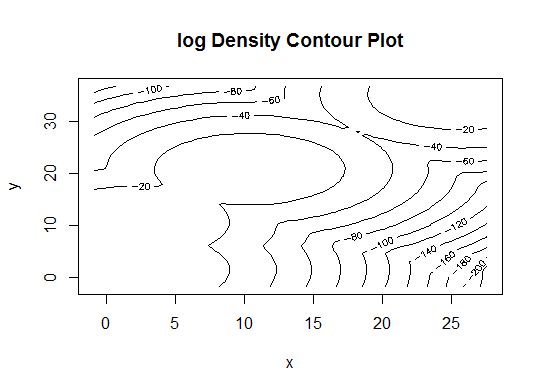
Четыре. Определить оптимальную модель и количество кластеров в соответствии с байесовским информационным критерием для максимизации ожиданий, инициализированную иерархической кластеризацией для параметризованных моделей смеси Гаусса
# See http://www.jstatsoft.org/v18/i06/paper
# http://www.stat.washington.edu/research/reports/2006/tr504.pdf
#
library(mclust)
# Run the function to see how many clusters
# it finds to be optimal, set it to search for
# at least 1 model and up 20.
d_clust <- Mclust(as.matrix(d), G=1:20)
m.best <- dim(d_clust$z)[2]
cat("model-based optimal number of clusters:", m.best, "\n")
# 4 clusters
plot(d_clust)
Пять. Кластеризация распространения аффинности (AP), см. http://dx.doi.org/10.1126/science.1136800
library(apcluster)
d.apclus <- apcluster(negDistMat(r=2), d)
cat("affinity propogation optimal number of clusters:", length(d.apclus@clusters), "\n")
# 4
heatmap(d.apclus)
plot(d.apclus, d)
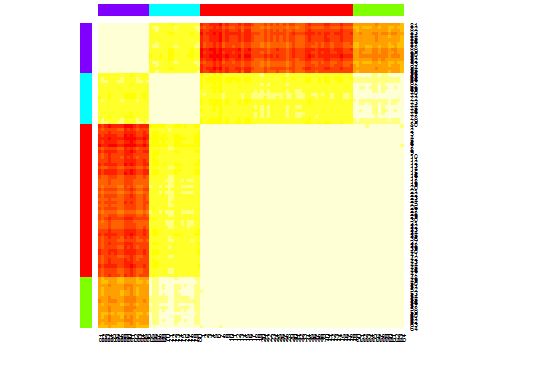
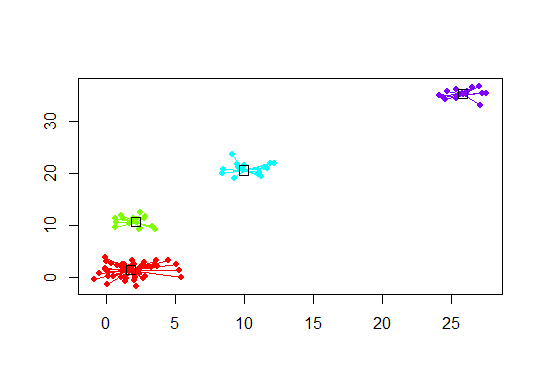
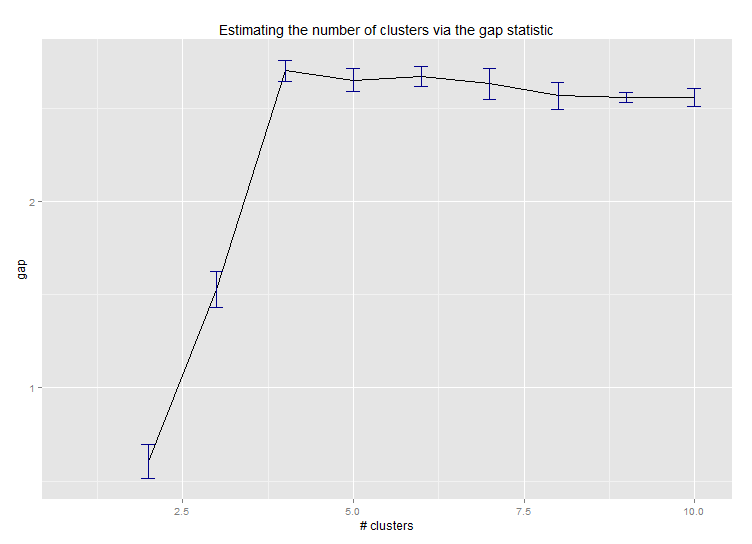
Шесть. Статистические данные о пробелах для оценки количества кластеров. См. Также код для приятного графического вывода. Попробуйте 2-10 кластеров здесь:
library(cluster)
clusGap(d, kmeans, 10, B = 100, verbose = interactive())
Clustering k = 1,2,..., K.max (= 10): .. done
Bootstrapping, b = 1,2,..., B (= 100) [one "." per sample]:
.................................................. 50
.................................................. 100
Clustering Gap statistic ["clusGap"].
B=100 simulated reference sets, k = 1..10
--> Number of clusters (method 'firstSEmax', SE.factor=1): 4
logW E.logW gap SE.sim
[1,] 5.991701 5.970454 -0.0212471 0.04388506
[2,] 5.152666 5.367256 0.2145907 0.04057451
[3,] 4.557779 5.069601 0.5118225 0.03215540
[4,] 3.928959 4.880453 0.9514943 0.04630399
[5,] 3.789319 4.766903 0.9775842 0.04826191
[6,] 3.747539 4.670100 0.9225607 0.03898850
[7,] 3.582373 4.590136 1.0077628 0.04892236
[8,] 3.528791 4.509247 0.9804556 0.04701930
[9,] 3.442481 4.433200 0.9907197 0.04935647
[10,] 3.445291 4.369232 0.9239414 0.05055486
Здесь результат работы Эдвина Чэня статистики пробелов:
Семь. Вам также может быть полезно изучить ваши данные с помощью clustergrams, чтобы визуализировать назначение кластера, см. http://www.r-statistics.com/2010/06/clustergram-visualization-and-diagnostics-for-cluster-analysis-r-code/ для получения более подробной информации.
Восемь. пакет NbClust содержит 30 индексов для определения количества кластеров в наборе данных.
library(NbClust)
nb <- NbClust(d, diss="NULL", distance = "euclidean",
min.nc=2, max.nc=15, method = "kmeans",
index = "alllong", alphaBeale = 0.1)
hist(nb$Best.nc[1,], breaks = max(na.omit(nb$Best.nc[1,])))
# Looks like 3 is the most frequently determined number of clusters
# and curiously, four clusters is not in the output at all!
<Т411 >
Если ваш вопрос how can I produce a dendrogram to visualize the results of my cluster analysis, вы должны начать с них:
http://www.statmethods.net/advstats/cluster.html
http://www.r-tutor.com/gpu-computing/clustering/hierarchical-cluster-analysis
http://gastonsanchez.wordpress.com/2012/10/03/7-ways-to-plot-dendrograms-in-r/ И посмотрите здесь более экзотические методы: http://cran.r-project.org/web/views/Cluster.html
Вот несколько примеров:
d_dist <- dist(as.matrix(d)) # find distance matrix
plot(hclust(d_dist)) # apply hirarchical clustering and plot
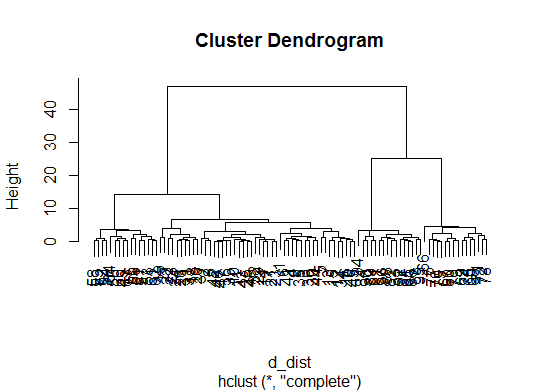
# a Bayesian clustering method, good for high-dimension data, more details:
# http://vahid.probstat.ca/paper/2012-bclust.pdf
install.packages("bclust")
library(bclust)
x <- as.matrix(d)
d.bclus <- bclust(x, transformed.par = c(0, -50, log(16), 0, 0, 0))
viplot(imp(d.bclus)$var); plot(d.bclus); ditplot(d.bclus)
dptplot(d.bclus, scale = 20, horizbar.plot = TRUE,varimp = imp(d.bclus)$var, horizbar.distance = 0, dendrogram.lwd = 2)
# I just include the dendrogram here
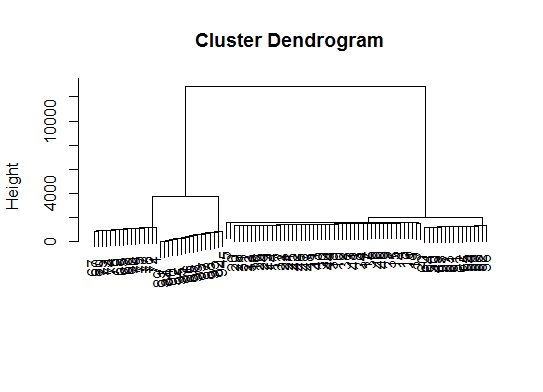
Кроме того, для высокоразмерных данных используется библиотека pvclust, которая вычисляет значения p для иерархической кластеризации с помощью повторной выборки с многомасштабной перезагрузкой. Вот пример из документации (не работает над такими низкоразмерными данными, как в моем примере):
library(pvclust)
library(MASS)
data(Boston)
boston.pv <- pvclust(Boston)
plot(boston.pv)
Помогает ли это?
Трудно добавить что-то слишком сложный ответ. Хотя я чувствую, что мы должны упомянуть identify здесь, особенно потому, что @Ben показывает много примеров дендрограмм.
d_dist <- dist(as.matrix(d)) # find distance matrix
plot(hclust(d_dist))
clusters <- identify(hclust(d_dist))
identify позволяет вам интерактивно выбирать кластеры из дендрограммы и сохраняет ваши варианты в списке. Нажмите Esc, чтобы выйти из интерактивного режима и вернуться в консоль R. Обратите внимание, что список содержит индексы, а не имена ростов (в отличие от cutree).
Чтобы определить оптимальный k-кластер в методах кластеризации. Обычно я использую метод Elbow, который сопровождает параллельную обработку, чтобы избежать компрометации времени. Этот код может выглядеть следующим образом:
Метод локтя
elbow.k <- function(mydata){
dist.obj <- dist(mydata)
hclust.obj <- hclust(dist.obj)
css.obj <- css.hclust(dist.obj,hclust.obj)
elbow.obj <- elbow.batch(css.obj)
k <- elbow.obj$k
return(k)
}
Параллельный локоть
no_cores <- detectCores()
cl<-makeCluster(no_cores)
clusterEvalQ(cl, library(GMD))
clusterExport(cl, list("data.clustering", "data.convert", "elbow.k", "clustering.kmeans"))
start.time <- Sys.time()
elbow.k.handle(data.clustering))
k.clusters <- parSapply(cl, 1, function(x) elbow.k(data.clustering))
end.time <- Sys.time()
cat('Time to find k using Elbow method is',(end.time - start.time),'seconds with k value:', k.clusters)
Хорошо работает.
-
2Функции elbow и css взяты из пакета GMD: cran.r-project.org/web/packages/GMD/GMD.pdf
Великолепный ответ от Бена. Однако я удивлен тем, что метод распространения аффинности (AP) был предложен только для того, чтобы найти число кластеров для метода k -средства, где в общем случае AP делает лучшую кластеризацию данных. См. Научную статью, поддерживающую этот метод в Science:
Фрей, Брендан Дж. и Делберт Дуек. "Кластеризация путем передачи сообщений между точками данных". наука 315.5814 (2007): 972-976.
Итак, если вы не привязаны к k-значению, я предлагаю напрямую использовать AP, который будет группировать данные, не требуя знать количество кластеров:
library(apcluster)
apclus = apcluster(negDistMat(r=2), data)
show(apclus)
Если отрицательные эвклидовы расстояния не подходят, вы можете использовать другие меры сходства, предусмотренные в том же пакете. Например, для сходства, основанного на корреляциях Спирмена, это то, что вам нужно:
sim = corSimMat(data, method="spearman")
apclus = apcluster(s=sim)
Обратите внимание, что эти функции для сходства в пакете AP просто предоставляются для простоты. Фактически, функция apcluster() в R примет любую матрицу корреляций. То же самое с corSimMat() можно сделать с помощью этого:
sim = cor(data, method="spearman")
или
sim = cor(t(data), method="spearman")
в зависимости от того, что вы хотите сгруппировать на своей матрице (строки или столбцы).
Эти методы хороши, но при попытке найти k для гораздо больших наборов данных, они могут быть очень медленными в R.
Хорошее решение, которое я нашел, - это пакет "RWeka", который имеет эффективную реализацию алгоритма X-Means - расширенную версию K-Means, которая лучше масштабируется и определит оптимальное количество кластеров для вас.
Сначала вы должны убедиться, что Weka установлена в вашей системе и что XMeans установлен через инструмент менеджера пакетов Weka.
library(RWeka)
# Print a list of available options for the X-Means algorithm
WOW("XMeans")
# Create a Weka_control object which will specify our parameters
weka_ctrl <- Weka_control(
I = 1000, # max no. of overall iterations
M = 1000, # max no. of iterations in the kMeans loop
L = 20, # min no. of clusters
H = 150, # max no. of clusters
D = "weka.core.EuclideanDistance", # distance metric Euclidean
C = 0.4, # cutoff factor ???
S = 12 # random number seed (for reproducibility)
)
# Run the algorithm on your data, d
x_means <- XMeans(d, control = weka_ctrl)
# Assign cluster IDs to original data set
d$xmeans.cluster <- x_means$class_ids
Ответы замечательные. Если вы хотите дать возможность другому методу кластеризации, вы можете использовать иерархическую кластеризацию и посмотреть, как расщепляются данные.
> set.seed(2)
> x=matrix(rnorm(50*2), ncol=2)
> hc.complete = hclust(dist(x), method="complete")
> plot(hc.complete)
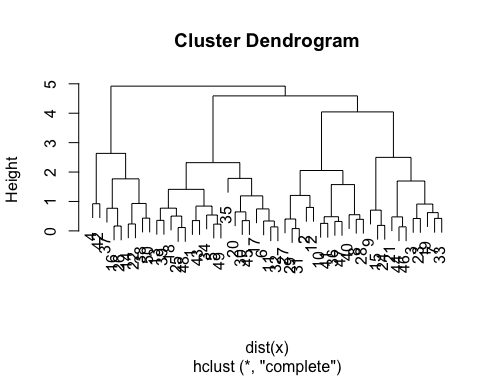
В зависимости от того, сколько классов вам нужно, вы можете вырезать свою дендрограмму как:
> cutree(hc.complete,k = 2)
[1] 1 1 1 2 1 1 1 1 1 1 1 1 1 2 1 2 1 1 1 1 1 2 1 1 1
[26] 2 1 1 1 1 1 1 1 1 1 1 2 2 1 1 1 2 1 1 1 1 1 1 1 2
Если вы наберете ?cutree, вы увидите определения. Если ваш набор данных имеет три класса, это будет просто cutree(hc.complete, k = 3). Эквивалент для cutree(hc.complete,k = 2) равен cutree(hc.complete,h = 4.9).
-
0Я предпочитаю опеку над полной.
Простым решением является библиотека factoextra. Вы можете изменить метод кластеризации и метод расчета лучшего количества групп. Например, если вы хотите узнать лучшее число кластеров для k-, значит:
Данные: mtcars
library(factoextra)
fviz_nbclust(mtcars, kmeans, method = "wss") +
geom_vline(xintercept = 3, linetype = 2)+
labs(subtitle = "Elbow method")
Наконец, мы получаем график вроде:
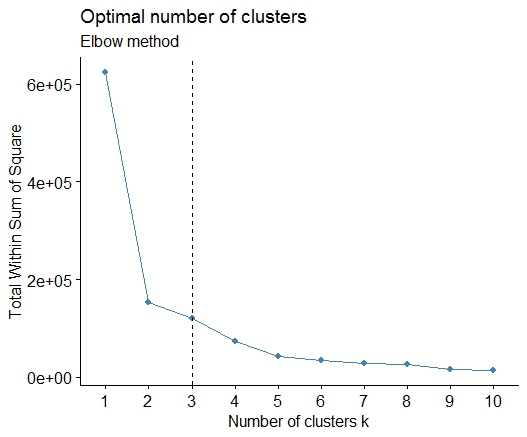
Ещё вопросы
- 1Ошибка, когда прямоугольная область интереса выходит за границы - opencv
- 0Странная проблема со смещенной вершиной в jquery
- 0Сохранение подключения MySQL на Express
- 0После указания аргумента placer в boost :: bind, почему он опускается при вызове?
- 0JQuery: добавить обработчик подтверждения с функциями привязки / включения и триггера
- 1Сборка приложения Flutter не выполняется, нужна помощь для устранения зависимостей
- 1Парсер DOM для чтения Xml, извлечения значений атрибутов и их хранения
- 1Панды, как добавить детали в CSV, прежде чем писать фрейм данных
- 1Ошибка: не найдено метаданных NgModule для 'undefined' в Angular2
- 0Как передать данные о значении в ссылку на действие
- 0Свежие данные MySQL через запрос с использованием Python
- 1Невозможно получить данные из базы данных
- 1Приложение для Android: передача Javascript Var в переменную Native Java
- 0Проблемы с Backbone.js и Require.js
- 0JQuery .post () возвращает HTML в таблицу
- 1Несколько ошибок при попытке запустить Spark с python 3
- 0Скрыть блок, который не соответствует высоте контейнера
- 0$ .getJson () предел ответа
- 0удалить элемент из локального хранилища
- 0Открытие функции, которая делает что-то через аргументы команды
- 1Получение строки с сайта
- 0Значение массива не работает
- 1Как игнорировать скрытые файлы при использовании os.stat () в Python?
- 1Изменение целевого фреймворка в приложении Xamarin.forms с Android 8.1 на Android 9 (для Xamarin.Essentials)
- 1Не удается разрешить метод updateUI ()
- 0Чтение проблем с двоичными данными
- 0Приложение Phonegap для Android - загрузка неверного значка данных в динамически генерируемый <li>
- 1Как программно получить имя универсального класса?
- 1Почему элементы CSS и Bootstrap исчезают с сервера экспресс-узла?
- 0Возникли проблемы с ориентацией на селектор (или что-то)
- 1Как написать этот тип значка при использовании текста в Android
- 0задержка добавления / удаления класса при наведении курсора мыши
- 1Обновление объекта, сохраненного в одном действии, из другого действия
- 1Linq Queryable отсутствует актерский состав?
- 1Показать страницу ошибки при сбое приложения из-за необработанного исключения
- 0Нет подходящей функции для вызова c ++
- 0Проблема отправки писем в php [дубликаты]
- 0Как я могу использовать Angularjs итерации строки JSON
- 0Нажатие кнопки не срабатывает, если div движется вниз
- 1Найти корень производной абсолютного значения комплексного числа в симпы
- 0Передача массива из JQuery в PHP через POST
- 0Не работает подпапка движка приложения Google - PHP
- 1Google Bubble Chart не определяет роли столбцов
- 0Ошибки codeigniter form_validation на flashdata не отображаются
- 1Как исправить ошибку при обновлении targetSdkVersion с версии 25 до 27?
- 1улучшения в коде
- 0Выберите строки, сгруппированные по столбцу, имеющему максимальный агрегат
- 0Невозможно выделить память для двумерного массива указателей c ++
- 1Определите, соответствует ли ElementFinder локатору
- 1Как отложить вызов в базу данных от gwt?

fpc. Это правда, тогда вам нужно установить два параметра ... но я обнаружил, чтоfpc::dbscanтогда выполняет довольно хорошую работу по автоматическому определениюfpc::dbscanколичества кластеров. Кроме того, он может на самом деле выводить один кластер, если это то, о чем вам говорят данные - некоторые из методов в превосходных ответах @ Ben не помогут вам определить, является ли k = 1 на самом деле лучшим.