Когда я должен использовать список против LinkedList
Когда лучше использовать List(Of T) vs a LinkedList(Of T)?
-
3Java q не должна сильно отличаться.nawfal
-
3@ drew-noakes, пожалуйста, подумайте об изменении принятого ответа. Нынешний неточный и крайне вводящий в заблуждение.Ben
13 ответов
Изменить
Прочтите комментарии к этому ответу. Люди утверждают, что я не делал надлежащие тесты. Я согласен, что это не должно быть приемлемым ответом. Как я был Я провела несколько тестов и почувствовала, как их разделять.
Оригинальный ответ...
Я нашел интересные результаты:
// Temporary class to show the example
class Temp
{
public decimal A, B, C, D;
public Temp(decimal a, decimal b, decimal c, decimal d)
{
A = a; B = b; C = c; D = d;
}
}
Связанный список (3,9 секунды)
LinkedList<Temp> list = new LinkedList<Temp>();
for (var i = 0; i < 12345678; i++)
{
var a = new Temp(i, i, i, i);
list.AddLast(a);
}
decimal sum = 0;
foreach (var item in list)
sum += item.A;
Список (2,4 секунды)
List<Temp> list = new List<Temp>(); // 2.4 seconds
for (var i = 0; i < 12345678; i++)
{
var a = new Temp(i, i, i, i);
list.Add(a);
}
decimal sum = 0;
foreach (var item in list)
sum += item.A;
Даже если вы только получаете доступ к данным, он значительно медленнее! Я говорю, никогда не используйте связанный список.
Вот еще одно сравнение, выполняющее множество вставок (мы планируем вставить элемент в середине списка)
Связанный список (51 секунда)
LinkedList<Temp> list = new LinkedList<Temp>();
for (var i = 0; i < 123456; i++)
{
var a = new Temp(i, i, i, i);
list.AddLast(a);
var curNode = list.First;
for (var k = 0; k < i/2; k++) // In order to insert a node at the middle of the list we need to find it
curNode = curNode.Next;
list.AddAfter(curNode, a); // Insert it after
}
decimal sum = 0;
foreach (var item in list)
sum += item.A;
Список (7.26 секунд)
List<Temp> list = new List<Temp>();
for (var i = 0; i < 123456; i++)
{
var a = new Temp(i, i, i, i);
list.Insert(i / 2, a);
}
decimal sum = 0;
foreach (var item in list)
sum += item.A;
Связанный список со ссылкой на место, где нужно вставить (0,04 секунды)
list.AddLast(new Temp(1,1,1,1));
var referenceNode = list.First;
for (var i = 0; i < 123456; i++)
{
var a = new Temp(i, i, i, i);
list.AddLast(a);
list.AddBefore(referenceNode, a);
}
decimal sum = 0;
foreach (var item in list)
sum += item.A;
Итак, только если вы планируете вставлять несколько элементов, а также, где-то есть ссылка, где вы планируете вставить элемент, а затем использовать связанный список. Просто потому, что вам нужно вставить множество элементов, это не ускоряет работу, поскольку поиск места, в который вы хотите вставить, требует времени.
-
94У LinkedList есть преимущество перед списком (это зависит от .net): поскольку список поддерживается внутренним массивом, он размещается в одном непрерывном блоке. Если размер выделенного блока превышает 85000 байт, он будет размещен в куче больших объектов, некомпактное поколение. В зависимости от размера это может привести к фрагментации кучи, легкой форме утечки памяти.
-
32Обратите внимание, что если вы много делаете предоплату (как вы это делаете в последнем примере) или удаляете первую запись, связанный список почти всегда будет значительно быстрее, так как не нужно выполнять поиск, перемещение или копирование. Список потребует перемещения всего на определенное место, чтобы разместить новый элемент, делая операцию O (N).
В большинстве случаев List<T> более полезен. LinkedList<T> будет иметь меньшую стоимость при добавлении/удалении элементов в середине списка, тогда как List<T> может только дешево добавить/удалить в конце списка.
LinkedList<T> работает только в том случае, если вы получаете доступ к последовательным данным (либо вперед, либо назад) - случайный доступ является относительно дорогостоящим, так как он должен каждый раз ходить по цепочке (следовательно, у него нет индексатора). Однако, поскольку List<T> по существу является просто массивом (с оберткой), то произвольный доступ в порядке.
List<T> также предлагает множество методов поддержки - Find, ToArray и т.д.; однако они также доступны для LinkedList<T> с .NET 3.5/С# 3.0 с помощью методов расширения - так что это менее важно.
-
3Одно из преимуществ List <> по сравнению с LinkedList <>, о котором я никогда не задумывался, касается того, как микропроцессоры реализуют кэширование памяти. Хотя я не совсем понимаю это, автор этой статьи блога много говорит о «местонахождении ссылки», которая делает обход массива намного быстрее, чем обход связанного списка, по крайней мере, если связанный список стал несколько фрагментированным в памяти , kjellkod.wordpress.com/2012/02/25/...
-
0@RenniePet List реализован с помощью динамического массива, а массивы являются смежными блоками памяти.
Мышление связанного списка в виде списка может немного ввести в заблуждение. Это больше похоже на цепочку. На самом деле, в .NET, LinkedList<T> даже не реализует IList<T>. В связанном списке нет реальной концепции индекса, хотя может показаться, что есть. Конечно, ни один из методов, предоставляемых в классе, не принимает индексы.
Связанные списки могут быть связаны по отдельности или дважды связаны. Это относится к тому, имеет ли каждый элемент в цепочке ссылку только на следующую (односвязную) или на оба предшествующих/следующих элемента (дважды связанную). LinkedList<T> имеет двойную связь.
Внутренне, List<T> поддерживается массивом. Это обеспечивает очень компактное представление в памяти. И наоборот, LinkedList<T> включает дополнительную память для хранения двунаправленных ссылок между последовательными элементами. Таким образом, размер памяти LinkedList<T> обычно будет больше, чем для List<T> (с оговоркой, что List<T> может иметь неиспользуемые внутренние элементы массива для повышения производительности во время операций добавления).
У них также разные характеристики:
Append
-
LinkedList<T>.AddLast(item)постоянное время -
List<T>.Add(item)амортизированное постоянное время, линейный наихудший случай
Prepend
-
LinkedList<T>.AddFirst(item)постоянное время -
List<T>.Insert(0, item)линейное время
Вставка
-
LinkedList<T>.AddBefore(node, item)постоянное время -
LinkedList<T>.AddAfter(node, item)постоянное время -
List<T>.Insert(index, item)линейное время
Удаление
-
LinkedList<T>.Remove(item)линейное время -
LinkedList<T>.Remove(node)постоянное время -
List<T>.Remove(item)линейное время -
List<T>.RemoveAt(index)линейное время
Count
-
LinkedList<T>.Countпостоянное время -
List<T>.Countпостоянное время
Содержит
-
LinkedList<T>.Contains(item)линейное время -
List<T>.Contains(item)линейное время
Очистить
-
LinkedList<T>.Clear()линейное время -
List<T>.Clear()линейное время
Как вы можете видеть, они в основном эквивалентны. На практике API LinkedList<T> является более громоздким в использовании, и детали его внутренних потребностей выходят в ваш код.
Однако, если вам нужно сделать много вложений/абстракций из списка, он предлагает постоянное время. List<T> предлагает линейное время, так как дополнительные элементы в списке должны быть перемешаны после вставки/удаления.
-
2Является ли количество связанных списков постоянным? Я думал, что это будет линейным?
-
9@ Iain, счетчик кэшируется в обоих классах списка.
Связанные списки обеспечивают очень быструю вставку или удаление члена списка. Каждый член в связанном списке содержит указатель на следующий член в списке, чтобы вставить элемент в позицию i:
- обновить указатель в элементе i-1, чтобы указать на новый элемент
- установите указатель в новом члене, чтобы указать член i
Недостатком связанного списка является то, что случайный доступ невозможен. Доступ к члену требует прохождения списка до тех пор, пока не будет найден нужный элемент.
-
6Я хотел бы добавить, что связанные списки имеют накладные расходы для каждого элемента, сохраненного выше, через LinkedListNode, который ссылается на предыдущий и следующий узел. Выгода от того, что это непрерывный блок памяти, не требуется для хранения списка, в отличие от списка на основе массива.
-
3Разве непрерывный блок памяти обычно не отрабатывается?
Разница между списком и LinkedList заключается в их основной реализации. Список представляет собой массив на основе массива (ArrayList). LinkedList - это коллекция node -interinter based (LinkedListNode). При использовании уровня API оба они почти одинаковы, поскольку оба реализуют один и тот же набор интерфейсов, таких как ICollection, IEnumerable и т.д.
Ключевое различие возникает, когда производительность имеет значение. Например, если вы реализуете список с тяжелой операцией "INSERT", LinkedList превосходит List. Поскольку LinkedList может сделать это в O (1) раз, но List может потребоваться расширить размер базового массива. Для получения дополнительной информации/подробностей вам может потребоваться ознакомиться с алгоритмической разницей между LinkedList и структурами данных массива. http://en.wikipedia.org/wiki/Linked_list и Array
Надеюсь на эту помощь,
-
4List <T> основан на массиве (T []), а не на ArrayList. Повторно вставьте: изменение размера массива не является проблемой (алгоритм удвоения означает, что большую часть времени ему не нужно это делать): проблема заключается в том, что он должен сначала скопировать все существующие данные, что занимает немного время.
-
2@Marc, «алгоритм удвоения» только делает его O (logN), но он все еще хуже, чем O (1)
Основным преимуществом связанных списков по массивам является то, что ссылки предоставляют нам возможность эффективно перестраивать элементы. Sedgewick, p. 91
-
1ИМО это должен быть ответ. LinkedList используются, когда важен гарантированный заказ.
-
1@RBaarda: я не согласен. Это зависит от уровня, о котором мы говорим. Алгоритмический уровень отличается от уровня реализации машины. Для рассмотрения скорости вам понадобится и последнее. Как уже указывалось, массивы реализованы как «один кусок» памяти, что является ограничением, поскольку это может привести к изменению размеров и реорганизации памяти, особенно с очень большими массивами. Подумав немного, особая собственная структура данных, связанный список массивов - это одна из идей, которая позволит лучше контролировать скорость линейного заполнения и доступ к очень большим структурам данных.
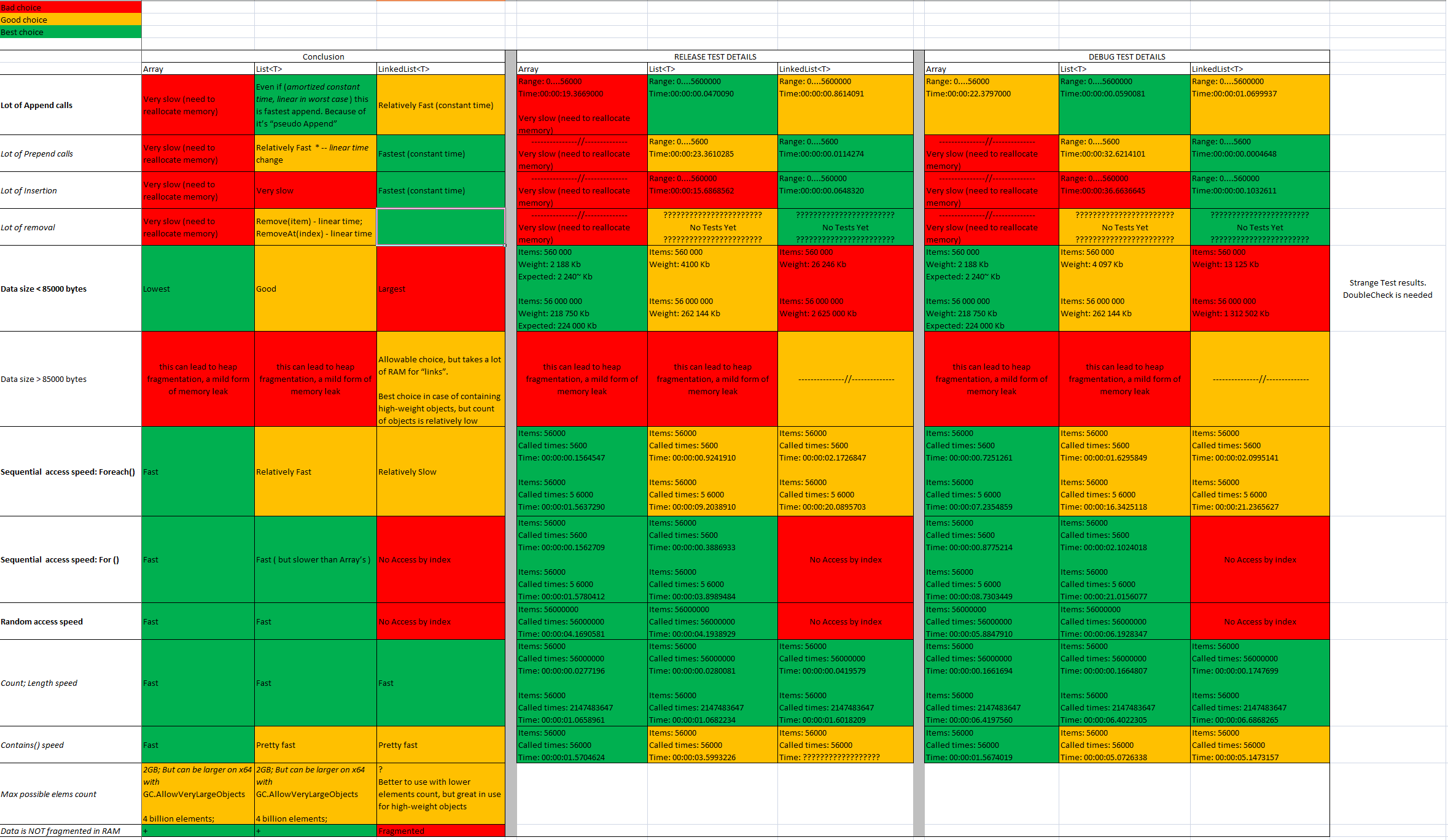
Мой предыдущий ответ был недостаточно точным. Как это было ужасно: D Но теперь я могу опубликовать гораздо более полезный и правильный ответ.
Я сделал несколько дополнительных тестов. Вы можете найти его источник по следующей ссылке и переустановить его в своей среде по своему усмотрению: https://github.com/ukushu/DataStructuresTestsAndOther.git
Короткие результаты:
-
Массив должен использовать:
- Так часто, насколько это возможно. Он быстро и занимает наименьший объем оперативной памяти для информации о том же объеме.
- Если вы знаете точное количество необходимых ячеек
- Если данные, сохраненные в массиве < 85000 b
- Если требуется высокая скорость произвольного доступа
-
Список должен использовать:
- Если необходимо добавить ячейки в конец списка (часто)
- Если необходимо добавить ячейки в начало/середину списка (NOT OFTEN)
- Если данные, сохраненные в массиве < 85000 b
- Если требуется высокая скорость произвольного доступа
-
LinkedList должен использовать:
- Если необходимо добавить ячейки в начало/середину/конец списка (часто)
- При необходимости только последовательный доступ (вперед/назад)
- Если вам нужно сохранить LARGE-элементы, но количество элементов будет низким.
- Лучше не использовать для большого количества элементов, так как он использует дополнительную память для ссылок.
Подробнее:
 Интересно знать:
Интересно знать:
-
Связанный список внутри не является списком в .NET.
LinkedList<T>. Он даже не реализуетIList<T>. И поэтому отсутствуют индексы и методы, связанные с индексами. -
LinkedList<T>представляет собой коллекцию node -interinter. В .NET это связано с двойной связью. Это означает, что предыдущие/следующие элементы имеют ссылку на текущий элемент. И данные фрагментированы - разные объекты списка могут быть расположены в разных местах ОЗУ. Кроме того, дляLinkedList<T>будет больше памяти, чем дляList<T>или массива. -
List<T>в .Net является альтернативой JavaArraList<T>. Это означает, что это оболочка массива. Таким образом, он выделяется в памяти как один непрерывный блок данных. Если выделенный размер данных превышает 85000 байт, он будет выделен как часть большой кучи объектов. В зависимости от размера это может привести к фрагментации кучи, легкой утечке памяти. Но в то же время, если размер < 85000 байт - это обеспечивает очень компактное представление с быстрым доступом в памяти. -
Единственный непрерывный блок предпочтительнее для производительности произвольного доступа и потребления памяти, но для коллекций, которые должны регулярно менять размер, структура, такая как массив, обычно должна быть скопирована в новое место, тогда как связанный список должен управлять только память для вновь вставленных/удаленных узлов.
-
1Вопрос: Под "данными, сохраненными в массиве <или> 85.000 байт" вы имеете в виду данные на массив / список ELEMENT, не так ли? Можно понять, что вы имеете в виду размер данных всего массива ..
-
0Элементы массива расположены последовательно в памяти. Так по массиву. Я знаю об ошибке в таблице, позже я это исправлю :) (надеюсь ....)
Общим для использования LinkedList является следующее:
Предположим, вы хотите удалить многие строки из списка строк большого размера, скажем, 100 000. Строки для удаления можно найти в HashSet dic, и, как считается, список строк содержит от 30 000 до 60 000 таких строк для удаления.
Тогда какой лучший тип списка для хранения 100 000 строк? Ответ: LinkedList. Если они хранятся в ArrayList, то итерация по ней и удаление совпадающих строк, которые будут занимать к миллиардам операций, тогда как требуется около 100 000 операций с использованием итератора и метода remove().
LinkedList<String> strings = readStrings();
HashSet<String> dic = readDic();
Iterator<String> iterator = strings.iterator();
while (iterator.hasNext()){
String string = iterator.next();
if (dic.contains(string))
iterator.remove();
}
-
4Вы можете просто использовать
RemoveAllчтобы удалить элементы изListне перемещая много элементов, или использоватьWhereиз LINQ, чтобы создать второй список. Однако использованиеLinkedListприводит к тому, что он потребляет значительно больше памяти, чем другие типы коллекций, а потеря локальности памяти означает, что итерация будет заметно медленнее, что делает его несколько хуже, чемList. -
0@ Служите, обратите внимание, что в ответе Тома используется Java. Я не уверен, что в Java
RemoveAllэквивалентRemoveAll.
Если вам нужен встроенный индексированный доступ, сортировка (и после этого двоичного поиска) и метод ToArray(), вы должны использовать List.
Это адаптировано из Tono Nam, принявшего ответ, исправляющий несколько неправильных измерений в нем.
Тест:
static void Main()
{
LinkedListPerformance.AddFirst_List(); // 12028 ms
LinkedListPerformance.AddFirst_LinkedList(); // 33 ms
LinkedListPerformance.AddLast_List(); // 33 ms
LinkedListPerformance.AddLast_LinkedList(); // 32 ms
LinkedListPerformance.Enumerate_List(); // 1.08 ms
LinkedListPerformance.Enumerate_LinkedList(); // 3.4 ms
//I tried below as fun exercise - not very meaningful, see code
//sort of equivalent to insertion when having the reference to middle node
LinkedListPerformance.AddMiddle_List(); // 5724 ms
LinkedListPerformance.AddMiddle_LinkedList1(); // 36 ms
LinkedListPerformance.AddMiddle_LinkedList2(); // 32 ms
LinkedListPerformance.AddMiddle_LinkedList3(); // 454 ms
Environment.Exit(-1);
}
И код:
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
namespace stackoverflow
{
static class LinkedListPerformance
{
class Temp
{
public decimal A, B, C, D;
public Temp(decimal a, decimal b, decimal c, decimal d)
{
A = a; B = b; C = c; D = d;
}
}
static readonly int start = 0;
static readonly int end = 123456;
static readonly IEnumerable<Temp> query = Enumerable.Range(start, end - start).Select(temp);
static Temp temp(int i)
{
return new Temp(i, i, i, i);
}
static void StopAndPrint(this Stopwatch watch)
{
watch.Stop();
Console.WriteLine(watch.Elapsed.TotalMilliseconds);
}
public static void AddFirst_List()
{
var list = new List<Temp>();
var watch = Stopwatch.StartNew();
for (var i = start; i < end; i++)
list.Insert(0, temp(i));
watch.StopAndPrint();
}
public static void AddFirst_LinkedList()
{
var list = new LinkedList<Temp>();
var watch = Stopwatch.StartNew();
for (int i = start; i < end; i++)
list.AddFirst(temp(i));
watch.StopAndPrint();
}
public static void AddLast_List()
{
var list = new List<Temp>();
var watch = Stopwatch.StartNew();
for (var i = start; i < end; i++)
list.Add(temp(i));
watch.StopAndPrint();
}
public static void AddLast_LinkedList()
{
var list = new LinkedList<Temp>();
var watch = Stopwatch.StartNew();
for (int i = start; i < end; i++)
list.AddLast(temp(i));
watch.StopAndPrint();
}
public static void Enumerate_List()
{
var list = new List<Temp>(query);
var watch = Stopwatch.StartNew();
foreach (var item in list)
{
}
watch.StopAndPrint();
}
public static void Enumerate_LinkedList()
{
var list = new LinkedList<Temp>(query);
var watch = Stopwatch.StartNew();
foreach (var item in list)
{
}
watch.StopAndPrint();
}
//for the fun of it, I tried to time inserting to the middle of
//linked list - this is by no means a realistic scenario! or may be
//these make sense if you assume you have the reference to middle node
//insertion to the middle of list
public static void AddMiddle_List()
{
var list = new List<Temp>();
var watch = Stopwatch.StartNew();
for (var i = start; i < end; i++)
list.Insert(list.Count / 2, temp(i));
watch.StopAndPrint();
}
//insertion in linked list in such a fashion that
//it has the same effect as inserting into the middle of list
public static void AddMiddle_LinkedList1()
{
var list = new LinkedList<Temp>();
var watch = Stopwatch.StartNew();
LinkedListNode<Temp> evenNode = null, oddNode = null;
for (int i = start; i < end; i++)
{
if (list.Count == 0)
oddNode = evenNode = list.AddLast(temp(i));
else
if (list.Count % 2 == 1)
oddNode = list.AddBefore(evenNode, temp(i));
else
evenNode = list.AddAfter(oddNode, temp(i));
}
watch.StopAndPrint();
}
//another hacky way
public static void AddMiddle_LinkedList2()
{
var list = new LinkedList<Temp>();
var watch = Stopwatch.StartNew();
for (var i = start + 1; i < end; i += 2)
list.AddLast(temp(i));
for (int i = end - 2; i >= 0; i -= 2)
list.AddLast(temp(i));
watch.StopAndPrint();
}
//OP original more sensible approach, but I tried to filter out
//the intermediate iteration cost in finding the middle node.
public static void AddMiddle_LinkedList3()
{
var list = new LinkedList<Temp>();
var watch = Stopwatch.StartNew();
for (var i = start; i < end; i++)
{
if (list.Count == 0)
list.AddLast(temp(i));
else
{
watch.Stop();
var curNode = list.First;
for (var j = 0; j < list.Count / 2; j++)
curNode = curNode.Next;
watch.Start();
list.AddBefore(curNode, temp(i));
}
}
watch.StopAndPrint();
}
}
}
Вы можете видеть, что результаты соответствуют теоретическим показателям, описанным в других документах. Совершенно ясно - LinkedList<T> получает большое время в случае вставок. Я не тестировал для удаления из середины списка, но результат должен быть таким же. Конечно, List<T> имеет другие области, где он лучше работает как O (1) произвольный доступ.
Я спросил аналогичный вопрос, связанный с производительностью коллекции LinkedList, и обнаружил Стивен Клири Реализация С# для Deque была решением. В отличие от коллекции Queue, Deque позволяет перемещать элементы взад и вперед спереди и сзади. Он похож на связанный список, но с улучшенной производительностью.
-
0
DequeчтоDeque«похож на связанный список, но с улучшенной производительностью» . Пожалуйста, уточните это утверждение:Deque- лучшая производительность, чемLinkedList, для вашего конкретного кода . Перейдя по вашей ссылке, я вижу, что через два дня вы узнали от Ивана Стоева, что это не неэффективность LinkedList, а неэффективность вашего кода. (И даже если бы это был неэффективный LinkedList, это не оправдало бы общее утверждение, что Deque более эффективен; только в определенных случаях.)
Здесь так много средних ответов...
В некоторых реализациях связанных списков используются базовые блоки предварительно выделенных узлов. Если они этого не делают, то постоянное время/линейное время менее важно, так как производительность памяти будет плохой, а производительность кэша еще хуже.
Используйте связанные списки, когда
1) Вам нужна безопасность потоков. Вы можете создавать улучшенные поточные альги. Затраты на блокировку будут доминировать в параллельном списке стилей.
2) Если у вас большая структура, похожая на очередь, и вы хотите удалить или добавить где угодно, кроме конца все время. > 100K-списки существуют, но не так распространены.
-
2Этот вопрос касался двух реализаций C #, а не связанных списков в целом.
-
0То же самое на каждом языке
Используйте LinkedList<>, когда
- Вы не знаете, сколько объектов проходит через шлюз. Например,
Token Stream. - Когда вы ТОЛЬКО хотите удалить \insert в конце.
Для всего остального лучше использовать List<>.
-
6Я не понимаю, почему пункт 2 имеет смысл. Связанные списки хороши, когда вы делаете много вставок / удалений по всему списку.
-
0Из-за того, что LinkedLists не основаны на индексах, вам действительно нужно сканировать весь список для вставки или удаления, что влечет за собой штраф O (n). List <>, с другой стороны, страдает от изменения размера массива, но все же, IMO, является лучшим вариантом по сравнению с LinkedLists.
Ещё вопросы
- 1Проблемы при построении временных рядов против пользовательских логинов?
- 0varchar m: d: YH: i: s для преобразования формата даты и времени в mysql
- 0Как просмотреть отдельно требуемый идентификатор
- 0Каков наилучший / рекомендуемый способ аутентификации пользователей, использующих отдых в Symfony?
- 0Заголовок PHP аутентифицируется, не принимая пользователя и пароль
- 1Как исправить «java.io.IOException: чтение не удалось, сокет может быть закрыт или истекло время ожидания» при попытке подключения к сопряженному устройству?
- 1Как передать переменные из одного JSP в другой, не делая их переменными сеанса?
- 1Пользовательская страница входа MarkLogic App Server cookie cookie с идентификатором GET
- 0Как сделать календарь всплывающим при нажатии на значок календаря?
- 1RadioButton выравнивает текст по левой стороне и кнопку вправо
- 1Как правильно изменить или удалить объект из области?
- 0Почему мой угловой пейджинг не работает?
- 1Переименование файлов с косой чертой в имени файла (python)
- 0Почему второй модуль не работает в angularjs?
- 0MySQL объединяет три таблицы
- 0Рисование wxBitmapButton поверх wxStaticBitmap
- 0Как можно передать идентификатор с одного маршрутизатора на другой в Node.js
- 0Обновление отдельных тегов span, начиная с x секунд
- 1NHibernate - наиболее лаконичный способ выбора нескольких столбцов с помощью QueryOver.
- 0Сортировать массив по указанным идентификаторам?
- 0Создание слияния типа, близкого к псевдокоду для домашней работы
- 0Многократное сканирование по ключу
- 0Различные результаты PHP между терминалом и браузером
- 1Изменить рекурсивный. Затем на асинхронный / ожидание
- 0Passport JS auth middleware проблема
- 1Как получить атрибут строки doc свойства?
- 0Как проверить, следует ли пользователь за другим, перед тем как подписаться или отписаться (прикрепить)
- 0HTML & Javascript - Показать / Скрыть форму с выпадающим списком или радио
- 1Xming: почему JFrame потерял фокус, когда установлен Undecorated (true)?
- 0Как использовать оператор управления (оператор if) во вложенной директиве ng-repeat?
- 0jQuery: установить Xml Node в элемент DOM
- 1значение строки запроса не извлекается
- 0Переписать URL в AngularJS Factory
- 0Динамический метатег с angularJS
- 1Java помощь относительно циклов
- 0Многопоточное приложение C ++ с использованием Matlab Engine
- 0Встроенный Boost-Spirit-Lex для придания токенам имени строки?
- 1Повторите задачу в течение срока с задержкой
- 1EditText - Cap слов без предложений?
- 1Цикл проектов в решении в MSBuild
- 0Стоимость mysql.connector.connect и connection.cursor
- 0Подключение к базе данных Sage 50 с использованием SQL
- 0Максимальная высота и максимальная ширина
- 0Глобальные переменные в Angular, хранящиеся в angularLocalStorage
- 0Как отредактировать значение 3 метки после нажатия на HREF с Javascript?
- 0сохранение базы данных резервных копий mysql с использованием php и пути mkdir
- 1Невозможно добавить изображение к кнопке с помощью getResource () (получить NullPointerException - создание проекта с помощью муравья)
- 0Как сравнить значение, содержащееся в переменной и строке без учета регистра в Smarty 2?
- 1получение покрытия кода через specflow
- 1Moq - Как шагнуть в реальный метод?
