В чем разница между re.search и re.match?
В чем разница между функциями search() и match() в Python re module?
Я прочитал документацию ( текущая документация), но я никогда не помню его. Я продолжаю искать и переучивать его. Я надеюсь, что кто-то ясно ответит на это примерами, чтобы (возможно) это застряло у меня в голове. Или, по крайней мере, у меня будет лучшее место, чтобы вернуться с моим вопросом, и для его изучения потребуется меньше времени.
8 ответов
re.match привязывается в начале строки. Это не имеет ничего общего с новыми строками, поэтому это не то же самое, что использовать ^ в шаблоне.
Как сообщает документация re.match:
Если на начало строки соответствует шаблону регулярных выражений, верните соответствующий экземпляр
MatchObject. ВернитеNone, если строка не соответствие шаблону; обратите внимание, что это отличная от совпадения с нулевой длиной.Примечание. Если вы хотите найти совпадение в любом месте в строке используйте
search()вместо этого.
re.search выполняет поиск по всей строке, поскольку в документации указано:
Сканировать строку, ища где регулярное выражение шаблон создает совпадение и возвращает соответствующий экземпляр
MatchObject. ВернитеNone, если в позиции строка соответствует шаблону; Обратите внимание, что это отличается от поиска совпадение нулевой длины в некоторый момент в строка.
Итак, если вам нужно совпадение в начале строки или для соответствия всей строке используйте match. Это быстрее. В противном случае используйте search.
В документации имеется конкретный раздел для match vs. search, который также охватывает многострочные строки:
Python предлагает два разных примитива операции, основанные на регулярных выражения:
matchпроверяет соответствие только в начале строки, аsearchпроверяет соответствие в любом месте в строке (это то, что Perl делает по умолчанию).Обратите внимание, что
matchможет отличаться отsearchдаже при использовании регулярного выражения начиная с'^':'^'соответствует только в начале строки или вMULTILINEтакже сразу после новой строки. "match" операция выполняется только в том случае, если шаблон совпадает со строкой startнезависимо от режима, или при запуске положение, заданное опционнымposаргумента, независимо от того, перед ним предшествует новая строка.
Теперь достаточно разговоров. Время, чтобы увидеть пример кода:
# example code:
string_with_newlines = """something
someotherthing"""
import re
print re.match('some', string_with_newlines) # matches
print re.match('someother',
string_with_newlines) # won't match
print re.match('^someother', string_with_newlines,
re.MULTILINE) # also won't match
print re.search('someother',
string_with_newlines) # finds something
print re.search('^someother', string_with_newlines,
re.MULTILINE) # also finds something
m = re.compile('thing$', re.MULTILINE)
print m.match(string_with_newlines) # no match
print m.match(string_with_newlines, pos=4) # matches
print m.search(string_with_newlines,
re.MULTILINE) # also matches
-
0Как насчет строк, содержащих переводы строки?Daryl Spitzer
-
0даже со строками, содержащими символы новой строки, match () совпадает только в НАЧАЛЕ строки.nosklo
search → найти что-нибудь в строке и вернуть объект соответствия.
match → найти что-то в начале строки и вернуть объект соответствия.
re.search поиск es для шаблона по всей строке, тогда как re.match не ищет шаблон; если это не так, у него нет другого выбора, кроме match в начале строки.
-
4Почему совпадение в начале, но не до конца строки (
fullmatchвfullmatch3.4)?
Разница заключается в том, что re.match() вводит в заблуждение любого, кто привык к сопоставлению регулярных выражений Perl, grep или sed, а re.search() - нет.: -)
Более трезвый, Как замечает Джон Д. Кук, re.match() "ведет себя так, как если бы каждый шаблон имел" добавленный". Другими словами, re.match('pattern') равно re.search('^pattern'). Таким образом, он фиксирует левую сторону шаблона. Но он также не привязывает правую сторону шаблона: это все еще требует завершения $.
Откровенно говоря, я сказал, что re.match() должен быть устаревшим. Мне было бы интересно узнать причины, по которым его следует сохранить.
-
3"ведет себя так, как будто каждый шаблон имеет ^ предваряющий." Истинно, только если вы не используете многострочный параметр. Правильное утверждение "... имеет \ A в начале"
вы можете ссылаться на приведенный ниже пример, чтобы понять работу re.match и re.search
a = "123abc"
t = re.match("[a-z]+",a)
t = re.search("[a-z]+",a)
re.match не вернет none, но re.search вернет abc.
-
3Просто хотел бы добавить, что поиск вернет объект _sre.SRE_Match (или None, если не найден). Чтобы получить 'abc', вам нужно вызвать t.group ()
Соответствие выполняется намного быстрее, чем поиск, поэтому вместо выполнения regex.search("word") вы можете выполнить regex.match((. *?) word (. *?)) и получить массу производительности, если работаете с миллионами образцы.
Этот комментарий @ivan_bilan под принятым ответом выше заставил меня задуматься о том, действительно ли такой хак ускоряет что-либо, поэтому давайте выясним, сколько тонн производительности вы действительно получите.
Я подготовил следующий набор тестов:
import random
import re
import string
import time
LENGTH = 10
LIST_SIZE = 1000000
def generate_word():
word = [random.choice(string.ascii_lowercase) for _ in range(LENGTH)]
word = ''.join(word)
return word
wordlist = [generate_word() for _ in range(LIST_SIZE)]
start = time.time()
[re.search('python', word) for word in wordlist]
print('search:', time.time() - start)
start = time.time()
[re.match('(.*?)python(.*?)', word) for word in wordlist]
print('match:', time.time() - start)
Я сделал 10 измерений (1M, 2M,..., 10M слов), что дало мне следующий график:
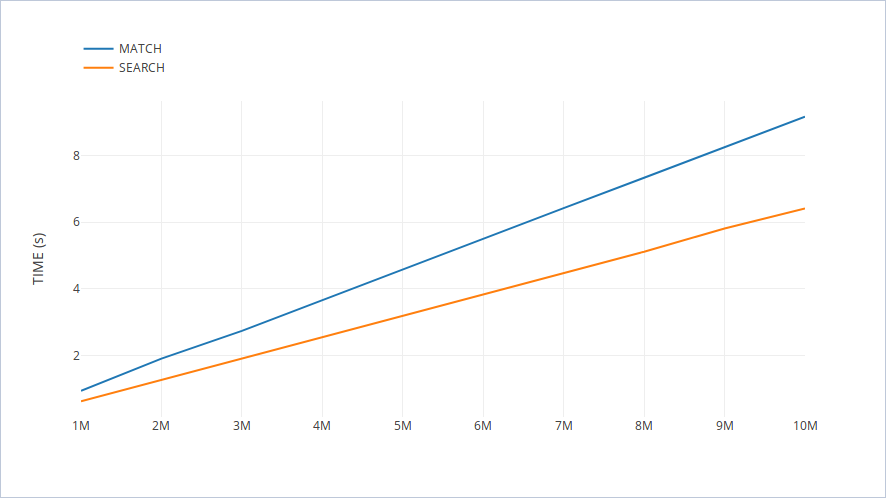
Получающиеся линии удивительно (фактически не так удивительно) прямые. И функция search (немного) быстрее, учитывая эту конкретную комбинацию шаблонов. Мораль этого теста: избегайте чрезмерной оптимизации вашего кода.
-
3+1 за фактическое исследование предположений, лежащих в основе заявления, которое должно быть принято за чистую монету - спасибо.
-
0Действительно, комментарий @ivan_bilan выглядит неправильно, но функция
matchвсе еще быстрее, чем функцияsearchесли сравнить то же регулярное выражение. Вы можете проверить свой скрипт, сравнивre.search('^python', word)сre.match('python', word)(илиre.match('^python', word)который такой же, но легче понять, если вы не читаете документацию и, кажется, не влияет на производительность)
re.match пытается сопоставить шаблон в начале строки. re.search пытается сопоставить шаблон по всей строке, пока не найдет совпадение.
Намного короче:
-
searchсканирует всю строку. -
matchДелает только начало строки.
После Ex говорит это:
>>> a = "123abc"
>>> re.match("[a-z]+",a)
None
>>> re.search("[a-z]+",a)
abc
Ещё вопросы
- 0Итоги с подгруппами
- 1Как установить ориентацию видов под наложением жестов на «нет»
- 1Отправка сообщений по ненадежной сети в JAVA
- 0Проблема установки ImageMagick для PHP на Windows
- 0Каков наилучший / рекомендуемый способ аутентификации пользователей, использующих отдых в Symfony?
- 1Как отключить быструю загрузку в новом «Android Device Manager» Xamarin?
- 0О выравнивании данных конкретной структуры
- 0Запретить запуск функций jQuery на определенной ширине экрана для системы меню / навигации
- 0Значение неинициализированного поля в классе
- 1документация sikuli 1.0.2 и ScreenRegion
- 0Ajax In QueryMethod Вызов в классическом Asp для отправки электронной почты
- 1Как добавить p5.dom в p5.js в режиме экземпляра
- 0Не удалось установить соединение с Pphmyadmin с помощью «hp_network_getaddresses: getaddrinfo fail»
- 0Angular UI-Router вложенные представления
- 0Как сократить тройной запрос ActiveRecord Joins с помощью отношения has_many?
- 0хранение глобальных переменных при уничтожении или выгрузке
- 0Игра встряхивания мыши Javascript не работает должным образом
- 1Код синхронизации для Promise All [дубликаты]
- 1Как получить значение первого столбца строки двойного щелчка DataGridView?
- 1Как я могу убедиться, что все пакеты были получены и сохранены в массиве?
- 1Перестановки отфильтрованы без повторяющихся символов
- 1Совпадение внутри строки, но игнорирование совпадений в скобках - Regex и JavaScript
- 1Создание новой даты из разницы / вычитание двух периодов (с отрицательным временем)
- 1Использование понимания вложенного списка для проверки и изменения всех столбцов фрейма данных
- 0Странные отступы вокруг создания текста, содержащие div слишком большой
- 1displayformatattribute для пользовательского формата строки
- 0ASP.NET MVC4 проверка подлинности телефонного промежутка
- 0Как привязать угловую директиву с помощью ng-repeat к Owl Carousel
- 0как отправить значение текстового поля по URL
- 1Заполните словарь несколькими понятиями
- 1Кэширование в памяти с ограничением по времени в python
- 0joomla - принудительно получить ключевое слово из определенного языка в JText
- 0Разработка SQL-заявления: как присоединиться к одной таблице
- 0Пользовательский валидатор не вызывает @service_container
- 1Google Charts Пользовательский шрифт отображается неправильно - Firefox
- 0Angularjs JSON разбор проблемы
- 1Расширение MVC - привязка модифицированного лямбда-выражения
- 0Завершение соединения MySQL
- 0Очистить разметку AngularJs
- 0Сортировать многомерный массив по значениям
- 1Как очистить анимацию добавления / удаления панели действий?
- 1Могу ли я реализовать трехслойную архитектуру при создании диаграммы классов UML?
- 0проверка формы с последующим отображением другой скрытой формы с помощью jquery
- 0У вас есть значение индекса копирования столбца при вставке?
- 0Запрос PDO Связывание таблиц и отображение результатов
- 0Как перенаправить пользователя на «домашнюю» страницу после проверки его данных для входа в базу данных?
- 0Можем ли мы создать индекс для столбца, содержащего значения NULL в MySQL 5.7?
- 0PHP - Explode / substr / Filename
- 1Разделить строку по тегам XML в Java
