Что такое группа без захвата? Что делает (? :)?
Как используется ?: и для чего это полезно?
-
33Этот вопрос был добавлен в FAQ по регулярным выражениям Stack Overflow в разделе «Группы».aliteralmind
15 ответов
Позвольте мне попытаться объяснить это на примере.
Рассмотрим следующий текст:
http://stackoverflow.com/
https://stackoverflow.com/questions/tagged/regex
Теперь, если я применил regex ниже над ним...
(https?|ftp)://([^/\r\n]+)(/[^\r\n]*)?
... Я бы получил следующий результат:
Match "http://stackoverflow.com/"
Group 1: "http"
Group 2: "stackoverflow.com"
Group 3: "/"
Match "https://stackoverflow.com/questions/tagged/regex"
Group 1: "https"
Group 2: "stackoverflow.com"
Group 3: "/questions/tagged/regex"
Но мне не нужен протокол - мне просто нужен хост и путь к URL. Итак, я изменяю регулярное выражение, чтобы включить группу, не связанную с захватом (?:).
(?:https?|ftp)://([^/\r\n]+)(/[^\r\n]*)?
Теперь мой результат выглядит следующим образом:
Match "http://stackoverflow.com/"
Group 1: "stackoverflow.com"
Group 2: "/"
Match "https://stackoverflow.com/questions/tagged/regex"
Group 1: "stackoverflow.com"
Group 2: "/questions/tagged/regex"
Видеть? Первая группа не была захвачена. Парсер использует его для соответствия тексту, но игнорирует его позже, в конечном результате.
РЕДАКТИРОВАТЬ:
В соответствии с просьбой позвольте мне также попытаться объяснить группы.
Ну, группы служат многим целям. Они могут помочь вам извлечь точную информацию из большего соответствия (которое также можно назвать), они позволяют вам переименовать предыдущую сопоставленную группу и могут использоваться для замещений. Попробуем несколько примеров, не так ли?
Хорошо, представьте, что у вас есть какой-то XML или HTML (имейте в виду, что регулярное выражение не может быть лучшим инструментом для работы, но это хорошо, как пример). Вы хотите проанализировать теги, чтобы вы могли сделать что-то вроде этого (я добавил места, чтобы было легче понять):
\<(?<TAG>.+?)\> [^<]*? \</\k<TAG>\>
or
\<(.+?)\> [^<]*? \</\1\>
Первое регулярное выражение имеет именованную группу (TAG), а вторая использует общую группу. Оба регулярных выражения делают то же самое: они используют значение из первой группы (имя тега) в соответствии с закрывающим тегом. Разница в том, что первая использует имя для соответствия значению, а вторая использует индекс группы (который начинается с 1).
Попробуем теперь несколько подстановок. Рассмотрим следующий текст:
Lorem ipsum dolor sit amet consectetuer feugiat fames malesuada pretium egestas.
Теперь позвольте использовать это немое регулярное выражение над ним:
\b(\S)(\S)(\S)(\S*)\b
Это регулярное выражение соответствует словам не менее 3 символов и использует группы для разделения первых трех букв. В результате получается следующее:
Match "Lorem"
Group 1: "L"
Group 2: "o"
Group 3: "r"
Group 4: "em"
Match "ipsum"
Group 1: "i"
Group 2: "p"
Group 3: "s"
Group 4: "um"
...
Match "consectetuer"
Group 1: "c"
Group 2: "o"
Group 3: "n"
Group 4: "sectetuer"
...
Итак, если мы применим строку подстановки...
$1_$3$2_$4
... над ним мы пытаемся использовать первую группу, добавить символ подчеркивания, использовать третью группу, затем вторую группу, добавить еще одно подчеркивание, а затем четвертую группу. Полученная строка будет похожа на приведенную ниже.
L_ro_em i_sp_um d_lo_or s_ti_ a_em_t c_no_sectetuer f_ue_giat f_ma_es m_la_esuada p_er_tium e_eg_stas.
Вы можете использовать именованные группы для замещений, используя ${name}.
Чтобы поиграть с регулярными выражениями, я рекомендую http://regex101.com/, где вы найдете подробные сведения о том, как работает регулярное выражение; он также предлагает несколько двигателей регулярных выражений на выбор.
-
1@ajsie: Традиционные (собирающие) группы наиболее полезны, если вы выполняете операцию замены результатов. Вот пример, где я собираю фамилии и имена, разделенные запятыми, а затем меняю их порядок (благодаря именованным группам) ... regexhero.net/tester/?id=16892996-64d4-4f10-860a-24f28dad7e30
-
0Могу ли я использовать это так? (: HTTP | FTP [?]): // ([^ / \ г \ п] +) (/ [^ \ г \ п] *)? Это так же, как (?: Http | ftp): // ([^ / \ r \ n] +) (/ [^ \ r \ n] *)? , пожалуйста, ответьте в ближайшее время
Вы можете использовать группы захвата для организации и анализа выражения. У группы, не связанной с захватом, есть первое преимущество, но у нее нет накладных расходов второго. Вы все же можете сказать, что группа, отличная от захвата, является необязательной.
Предположим, что вы хотите сопоставить числовой текст, но некоторые цифры могут быть записаны как 1, 2, 3, 4,... Если вы хотите захватить числовую часть, но не (необязательный) суффикс, вы можете использовать -захватывающая группа.
([0-9]+)(?:st|nd|rd|th)?
Это будет соответствовать числам в форме 1, 2, 3... или в форме 1-й, 2-й, 3-й,... но он будет только фиксировать числовую часть.
?: используется, когда вы хотите сгруппировать выражение, но вы не хотите сохранять его в качестве согласованной/захваченной части строки.
Примером может быть что-то, что соответствует IP-адресу:
/(?:\d{1,3}\.){3}\d{1,3}/
Обратите внимание: я не забочусь о сохранении первых 3 октетов, но группировка (?:...) позволяет мне сократить регулярное выражение, не налагая накладные расходы на захват и сохранение соответствия.
Это делает группу не захватывающей, что означает, что подстрока, соответствующая этой группе, не будет включена в список захватов. Пример в рубине, чтобы проиллюстрировать разницу:
"abc".match(/(.)(.)./).captures #=> ["a","b"]
"abc".match(/(?:.)(.)./).captures #=> ["b"]
ИСТОРИЧЕСКАЯ МОТИВАЦИЯ: Существование не захватывающих групп можно объяснить с помощью скобок. Рассмотрим выражения (a | b) c и a | bc из-за приоритета конкатенации над |, эти выражения представляют собой два разных языка ({ac, bc} и {a, bc} соответственно). Тем не менее, скобки также используются в качестве сопоставимой группы (как объясняют другие ответы...).
Если вы хотите иметь скобки, но не захватывать подвыражение, вы используете НЕЗАВИСИМЫЕ ГРУППЫ. В этом примере (?: A | b) c
-
2Мне было интересно, почему. Как я думаю, «почему» жизненно важно для запоминания этой информации.
Группы, которые захватывают, которые можно использовать позже в регулярном выражении, чтобы соответствовать ИЛИ, вы можете использовать их в замещающей части регулярного выражения. Создание не захватывающей группы просто освобождает эту группу от использования по любой из этих причин.
Не захватывающие группы великолепны, если вы пытаетесь захватить множество разных вещей, и есть группы, которые вы не хотите захватывать.
Это в значительной степени причина, по которой они существуют. Пока вы узнаете о группах, узнайте о Atomic Groups, они многое делают! Есть также группы поиска, но они немного сложнее и не используются так много.
Пример использования позже в регулярном выражении (обратная ссылка):
<([A-Z][A-Z0-9]*)\b[^>]*>.*?</\1> [Находит тэг xml (без поддержки ns)]
([A-Z][A-Z0-9]*) - группа захвата (в данном случае это тэг)
Далее в регулярном выражении \1, что означает, что он будет соответствовать только тому же тексту, который был в первой группе (группа ([A-Z][A-Z0-9]*)) (в этом случае он соответствует концевому тегу).
-
0Не могли бы вы привести простой пример того, как он будет использоваться позже, чтобы соответствовать ИЛИ?
-
0Я имею в виду, что вы можете использовать, чтобы соответствовать позже или вы можете использовать его в замене. Или в этом предложении было просто, чтобы показать вам, что есть две цели для группы захвата
Позвольте мне попробовать это на примере: -
Код (?:animal)(?:=)(\w+)(,)\1\2: - (?:animal)(?:=)(\w+)(,)\1\2
Строка поиска: -
Линия 1 - animal=cat,dog,cat,tiger,dog
Строка 2 - animal=cat,cat,dog,dog,tiger
Строка 3 - animal=dog,dog,cat,cat,tiger
(?:animal) → Не захваченная группа 1
(?:=) → Не взятая группа 2
(\w+) → Захваченная группа 1
(,) → Захваченная группа 2
\1 → результат захваченной группы 1, т.е. В строке 1 находится кошка, в строке 2 - кошка, в строке 3 - собака.
\2 → результат захваченной группы 2, т.е. Запятая (,)
Таким образом, в этом коде, давая \1 и\2, мы вспоминаем или повторяем результат захваченной группы 1 и 2 соответственно позже в коде.
В соответствии с порядком кода (?: Animal) должна быть группа 1, а (?: =) Должна быть группой 2 и продолжается.
но давая?: мы делаем группу соответствия не захваченной (которая не учитывается в согласованной группе, поэтому число группировки начинается с первой захваченной группы, а не без захвата), так что повторение результата совпадения -группа (?: animal) не может быть вызвана позже в коде.
Надеюсь, что это объясняет использование группы, не содержащей захвата.
{kind=link}
-
0отличное и простое объяснение!
Ну, я разработчик JavaScript и попытаюсь объяснить его значение, относящееся к JavaScript.
Рассмотрим сценарий, в котором вы хотите совместить cat is animal
когда вы хотите совместить кошку и животное, и оба должны иметь is между ними.
// this will ignore "is" as that is what we want
"cat is animal".match(/(cat)(?: is )(animal)/) ;
result ["cat is animal", "cat", "animal"]
// using lookahead pattern it will match only "cat" we can
// use lookahead but the problem is we can not give anything
// at the back of lookahead pattern
"cat is animal".match(/cat(?= is animal)/) ;
result ["cat"]
//so I gave another grouping parenthesis for animal
// in lookahead pattern to match animal as well
"cat is animal".match(/(cat)(?= is (animal))/) ;
result ["cat", "cat", "animal"]
// we got extra cat in above example so removing another grouping
"cat is animal".match(/cat(?= is (animal))/) ;
result ["cat", "animal"]
В сложных регулярных выражениях может возникнуть ситуация, когда вы хотите использовать большое количество групп, некоторые из которых существуют для соответствия повторениям, а некоторые из них предназначены для предоставления обратных ссылок. По умолчанию текст, соответствующий каждой группе, загружается в массив обратной ссылки. В тех случаях, когда у нас много групп, и только нужно иметь возможность ссылаться на некоторые из них из массива backreference, мы можем переопределить это поведение по умолчанию, чтобы сообщить регулярному выражению, что определенные группы существуют только для обработки повторений и их не нужно захватывать и хранить в массиве backreference.
tl; dr non-captureuring groups, как следует из названия, являются частями регулярного выражения, которые вы не хотите включать в совпадение и ?: это способ определить группу как не захватывающую.
Скажем, у вас есть адрес электронной почты [email protected]. Следующее регулярное выражение создаст две группы: часть id и часть @example.com. (\p{Alpha}*[az])(@example.com). Для простоты мы извлекаем все доменное имя, включая символ @.
Теперь скажем, вам нужна только идентификационная часть адреса. То, что вы хотите сделать, - захватить первую группу результата совпадения, окруженную () в регулярном выражении, и способ сделать это - использовать синтаксис группы без захвата, то есть ?:. Поэтому регулярное выражение (\p{Alpha}*[az])(?:@example.com) вернет только часть идентификатора электронной почты.
Одна интересная вещь, с которой я столкнулся, - это то, что у вас может быть группа захвата внутри группы, не связанной с захватом. Посмотрите ниже регулярное выражение для соответствия веб-URL:
var parse_url_regex = /^(?:([A-Za-z]+):)(\/{0,3})([0-9.\-A-Za-z]+)(?::(\d+))?(?:\/([^?#]*))?(?:\?([^#]*))?(?:#(.*))?$/;
Введите строку url:
var url = "http://www.ora.com:80/goodparts?q#fragment";
Первая группа в моем регулярном выражении (?:([A-Za-z]+):) - это не захватывающая группа, которая соответствует схеме протокола и символу двоеточия :, т.е. http:, но когда я работал под кодом, я видел первый индекс возвращенного массив содержал строку http, когда я думал, что http и двоеточие : оба не получат сообщения, поскольку они находятся внутри группы, не содержащей захвата.
console.debug(parse_url_regex.exec(url));
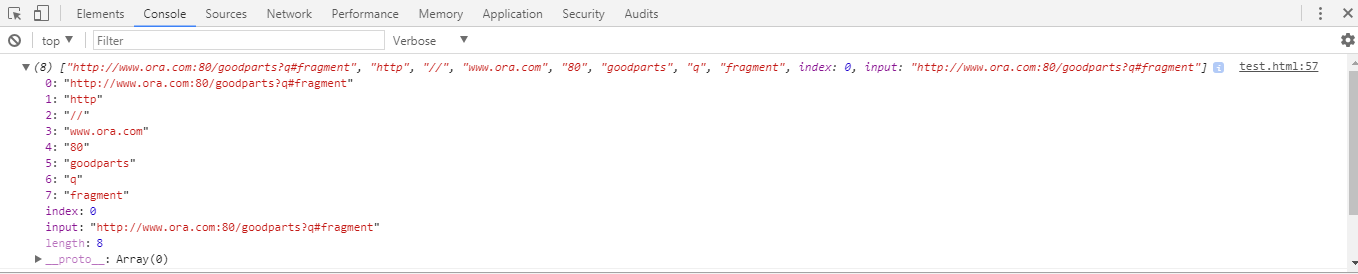
Я подумал, что если первая группа (?:([A-Za-z]+):) является не захваченной группой, то почему она возвращает строку http в выходном массиве.
Итак, если вы заметили, что внутри группы, не содержащей захвата, есть вложенная группа ([A-Za-z]+). Эта вложенная группа ([A-Za-z]+) является группой захвата (не имея ?: в начале) сама по себе внутри группы, не содержащей захвата (?:([A-Za-z]+):). Поэтому текст http по-прежнему захватывается, но символ двоеточия :, который находится внутри группы не захвата, но вне группы захвата не получает сообщения в выходном массиве.
Я не могу комментировать верхние ответы, чтобы сказать это: я хотел бы добавить явный пункт, который подразумевается только в верхних ответах:
Не захватывающая группа (?...)
не удаляет любые символы из исходного полного соответствия, только он визуально визуализирует регулярное выражение для программиста.
Чтобы получить доступ к определенной части регулярного выражения без определенных посторонних символов, вам всегда нужно использовать .group(<index>)
-
2Вы предоставили самый важный совет, который отсутствовал в остальных ответах. Я перепробовал все примеры в них и использовал отборные ругательства, так как не получил желаемого результата. Только ваши сообщения показали мне, где я ошибся.
-
0Рад слышать это!
Думаю, я дам вам ответ, Не используйте переменные захвата, не проверяя, что совпадение выполнено успешно.
Перехватчики захвата, $1 и т.д. недействительны, если совпадение не выполнено, и они также не очищаются.
#!/usr/bin/perl
use warnings;
use strict;
$_ = "bronto saurus burger";
if (/(?:bronto)? saurus (steak|burger)/)
{
print "Fred wants a $1";
}
else
{
print "Fred dont wants a $1 $2";
}
В приведенном выше примере, Чтобы избежать захвата bronto в $1, используется (?:). Если шаблон сопоставляется, то $1 фиксируется как следующий сгруппированный шаблон. Таким образом, выход будет выглядеть следующим образом:
Fred wants a burger
Полезно, если вы не хотите, чтобы совпадения сохранялись.
Это очень просто, мы можем понять на простом примере даты, предположим, что если дата упоминается как 1 января 2019 года или 2 мая 2019 года или любая другая дата, и мы просто хотим преобразовать ее в формат дд/мм/гггг, нам не нужен месяц имя, которое в этом случае будет январь или февраль, поэтому для захвата числовой части, но не суффикса (необязательно), вы можете использовать группу без захвата.
поэтому регулярное выражение будет
([0-9]+)(?:January|February)?
Это так просто.
Откройте Google DevTools, а затем вкладку Консоль и введите следующее:
"Peace".match(/(\w)(\w)(\w)/)
Запустите его, и вы увидите:
["Pea", "P", "e", "a", index: 0, input: "Peace", groups: undefined]
Механизм JavaScript RegExp захватывает три группы, элементы с индексами 1,2,3. Теперь используйте нефиксирующую метку, чтобы увидеть результат.
"Peace".match(/(?:\w)(\w)(\w)/)
Результат:
["Pea", "e", "a", index: 0, input: "Peace", groups: undefined]
Это очевидно, что не захватывает группу.
Ещё вопросы
- 0$ обновить метод PUT в Angular?
- 0Обработка списка в C ++: инициализация min первым значением списка
- 1Вставить HTML в столбец Helper WebGrid
- 0PHP массив не работает правильно
- 1Найти тип изображения из потока памяти
- 0Как извлечь информацию из одного файла и разделить информацию на четыре других файла?
- 0AngularJS выпадающий - автоматический выбор не работает
- 1Использование foreach с движком представления ASP.NET внутри ASP: Repeater не работает
- 0Отображение определенного содержимого веб-сайта в веб-просмотр
- 1Есть ли какой-либо тип списка, который будет содержать информацию о пользователе во второй вкладке?
- 0JQuery несколько событий и несколько селекторов
- 0Вложенные элементы div не расположены должным образом
- 0преобразование из двоичной строки в int с использованием strtoll?
- 1Группировать массив объектов javascript на основе значения в свой собственный массив объектов
- 1Получать хеш-строку разных приложений каждый раз | API SMS Retriever
- 0Как добавить текст с пробелами для метки с помощью jquery?
- 0динамическая настройка высоты div, чтобы нижний колонтитул был внизу, если содержимое не заполняет окно
- 0JavaScript внутри PHP не работает
- 0MySQL объединяет 2 таблицы, и результат должен быть в IN Third_table
- 0Агрегация не работает в Mongoose с Match и Group
- 0Связывание проблем с libharu
- 1OWIN - Selfhosting WebApi без определенного порта
- 1Проблема с определением размеров JTextFields
- 1Регулярные выражения для добавления классов в HTML-теги
- 1Правильно установить приоритеты между правилами и терминалами в грамматике для жаворонка
- 0JQGrid: local - jqGrid.trigger («reloadGrid») заставляет исчезать отформатированные данные
- 0Google Places хранит результаты в Mysql с PHP
- 0Как изменить опцию выбора выпадающего списка при onclick ()?
- 1Выдать URL при нажатии кнопки, когда она работает в фоновом режиме
- 0Подсветка активных кнопок в HTML
- 0jQuery Добавить элемент span в элементе абзаца, который добавляется в DOM
- 0jQuery bind и click click evnts не работают в IE9
- 0Является ли состояние, отображаемое в дампе сбоя приложения, точным в Windows при получении из диспетчера задач?
- 0MySQL 5.7 изменяет блокировку оператора DDL таблицы, но должна допускать одновременный DML
- 0как скрыть пустую строку в MySql Workbench
- 0html5 видео плеер не работает в PhoneGap Android 2.2?
- 1Lightinject - Обнаружена рекурсивная зависимость
- 0Ошибка нижнего индекса вектора вне диапазона
- 0Система вкладок для div
- 1Нажмите: как применить действие ко всем командам и подкомандам, но разрешить команде отказаться (часть duex)?
- 0Пагинация в Yii без базы данных
- 1Восстанавливаемое веб-задание Azure (не удалять из очереди)
- 0Мышление по-угловому
- 1«Неизвестный слой: лямбда» в tenorflowjs в браузере
- 0MySQL поиск дубликатов имен файлов с разными расширениями
- 1Как создать несколько элементов в разных местах, используя методы DOM
- 1Привязка функции обратного вызова при использовании Async Waterfall
- 0Цикл по соединениям с базой данных
- 0Получить innerHTML из динамически добавленного тега скрипта
- 0Как передать статус `контроллеров` в шаблонную функцию` directive`?
