Как избежать цепочек «если»?
Предполагая, что у меня есть этот псевдокод:
bool conditionA = executeStepA();
if (conditionA){
bool conditionB = executeStepB();
if (conditionB){
bool conditionC = executeStepC();
if (conditionC){
...
}
}
}
executeThisFunctionInAnyCase();
Функции executeStepX должны выполняться тогда и только тогда, когда предыдущее выполняется.
В любом случае функцию executeThisFunctionInAnyCase следует вызывать в конце.
Я новичок в программировании, поэтому извините за самый простой вопрос: есть ли способ (например, в C/С++), чтобы избежать этой длинной цепочки if, производящей такую "пирамиду кода", за счет четкость кода?
Я знаю, что если бы мы могли пропустить вызов функции executeThisFunctionInAnyCase, код можно было бы упростить как:
bool conditionA = executeStepA();
if (!conditionA) return;
bool conditionB = executeStepB();
if (!conditionB) return;
bool conditionC = executeStepC();
if (!conditionC) return;
Но ограничение - вызов функции executeThisFunctionInAnyCase.
Может ли оператор break использоваться каким-то образом?
51 ответ
Вы можете использовать && (логика AND):
if (executeStepA() && executeStepB() && executeStepC()){
...
}
executeThisFunctionInAnyCase();
это удовлетворит оба ваших требования:
-
executeStep<X>()должен оцениваться только в том случае, если предыдущий преуспел (это называется оценка короткого замыкания) -
executeThisFunctionInAnyCase()будет выполняться в любом случае
-
0Извините, я отредактировал приведенный выше код, чтобы получить больше информации, начиная с созданной мной программы. Я скучаю по этой информации
-
1@ user3253359 Я откатил это редактирование. Смотрите ниже ваш вопрос относительно причины.
Просто используйте дополнительную функцию, чтобы заставить вашу вторую версию работать:
void foo()
{
bool conditionA = executeStepA();
if (!conditionA) return;
bool conditionB = executeStepB();
if (!conditionB) return;
bool conditionC = executeStepC();
if (!conditionC) return;
}
void bar()
{
foo();
executeThisFunctionInAnyCase();
}
Использование глубоко вложенных ifs (ваш первый вариант) или желание вырваться из "части функции" обычно означает, что вам нужна дополнительная функция.
-
51+1 наконец кто-то выложил вменяемый ответ. Это самый правильный, безопасный и читаемый способ, на мой взгляд.
-
31+1 Это хорошая иллюстрация «Принципа единой ответственности». Функция
fooпроходит через последовательность связанных условий и действий. Функциональнаяbarчетко отделена от решений. Если бы мы увидели детали условий и действий, может оказаться, чтоfooвсе еще делает слишком много, но сейчас это хорошее решение.
В этом случае программисты старой школы C используют goto. Это единственное использование goto, которое действительно поощряется Linux styleguide, оно называется централизованным выходом функции:
int foo() {
int result = /*some error code*/;
if(!executeStepA()) goto cleanup;
if(!executeStepB()) goto cleanup;
if(!executeStepC()) goto cleanup;
result = 0;
cleanup:
executeThisFunctionInAnyCase();
return result;
}
Некоторые люди работают с использованием goto, обертывая тело в цикл и ломая его, но фактически оба подхода делают то же самое. Подход goto лучше, если вам нужна другая очистка, только если executeStepA() был успешным:
int foo() {
int result = /*some error code*/;
if(!executeStepA()) goto cleanupPart;
if(!executeStepB()) goto cleanup;
if(!executeStepC()) goto cleanup;
result = 0;
cleanup:
innerCleanup();
cleanupPart:
executeThisFunctionInAnyCase();
return result;
}
При использовании петлевого подхода в этом случае вы получите два уровня циклов.
-
107+1. Многие люди видят
gotoи сразу думают: «Это ужасный код», но он действительно имеет свое применение. -
46За исключением того, что это на самом деле довольно грязный код с точки зрения обслуживания. Особенно, когда есть несколько меток, где код также становится сложнее для чтения. Для этого есть более элегантные способы: использовать функции.
Это обычная ситуация, и есть много общих способов борьбы с ней. Вот моя попытка канонического ответа. Прошу прокомментировать, если я пропустил что-нибудь, и я сохраню это сообщение в актуальном состоянии.
Это стрелка
То, что вы обсуждаете, называется anti-pattern. Он называется стрелкой, потому что цепочка вложенных ifs формирует кодовые блоки, которые расширяются дальше и дальше вправо, а затем назад влево, образуя визуальную стрелку, которая "указывает" на правую сторону панели редактора кода.
Сгладить стрелку с помощью Guard
Некоторые общие способы избежать стрелки обсуждаются здесь. Наиболее распространенным методом является использование шаблона guard, в котором код сначала обрабатывает потоки исключений, а затем обрабатывает основной поток, например. вместо
if (ok)
{
DoSomething();
}
else
{
_log.Error("oops");
return;
}
... вы бы использовали....
if (!ok)
{
_log.Error("oops");
return;
}
DoSomething(); //notice how this is already farther to the left than the example above
Когда есть длинная серия охранников, это значительно выравнивает код, поскольку все охранники появляются полностью влево, а ваши ifs не вложены. Кроме того, вы визуально соединяете логическое условие со своей связанной ошибкой, что значительно облегчает рассказ о том, что происходит:
Стрелка:
ok = DoSomething1();
if (ok)
{
ok = DoSomething2();
if (ok)
{
ok = DoSomething3();
if (!ok)
{
_log.Error("oops"); //Tip of the Arrow
return;
}
}
else
{
_log.Error("oops");
return;
}
}
else
{
_log.Error("oops");
return;
}
Guard:
ok = DoSomething1();
if (!ok)
{
_log.Error("oops");
return;
}
ok = DoSomething2();
if (!ok)
{
_log.Error("oops");
return;
}
ok = DoSomething3();
if (!ok)
{
_log.Error("oops");
return;
}
ok = DoSomething4();
if (!ok)
{
_log.Error("oops");
return;
}
Это объективно и количественно легче читать, потому что
- Символы {и} для данного логического блока ближе друг к другу
- Количество ментального контекста, необходимого для понимания конкретной линии, меньше
- Вся логика, связанная с условием if, скорее всего, будет на одной странице
- Необходимость кодера для прокрутки дорожки страницы/глаз значительно уменьшается
Как добавить общий код в конец
Проблема с шаблоном охраны заключается в том, что он полагается на то, что называется "оппортунистическим возвратом" или "оппортунистическим выходом". Другими словами, он разбивает шаблон, что каждая функция должна иметь ровно одну точку выхода. Это проблема по двум причинам:
- Это раздражает некоторых людей, например. люди, которые научились программировать на Паскале, узнали, что одна функция = одна точка выхода.
- Он не предоставляет раздел кода, который выполняется при выходе, независимо от того, что, которое является предметом под рукой.
Ниже я предоставил некоторые опции для работы с этим ограничением либо с помощью языковых функций, либо вообще без проблем.
Вариант 1. Вы не можете этого сделать: используйте finally
К сожалению, как разработчик С++, вы не можете этого сделать. Но это ответ номер один для языков, содержащих ключевое слово finally, так как это именно то, для чего он нужен.
try
{
if (!ok)
{
_log.Error("oops");
return;
}
DoSomething(); //notice how this is already farther to the left than the example above
}
finally
{
DoSomethingNoMatterWhat();
}
Вариант 2. Избегайте проблемы: реструктурируйте свои функции
Вы можете избежать проблемы, разбив код на две функции. Это решение имеет преимущество для работы на любом языке, и, кроме того, оно может уменьшить циклическую сложность, что является проверенным способом снижения скорости вашего дефекта и улучшает специфику любого автоматизированные модульные тесты.
Вот пример:
void OuterFunction()
{
DoSomethingIfPossible();
DoSomethingNoMatterWhat();
}
void DoSomethingIfPossible()
{
if (!ok)
{
_log.Error("Oops");
return;
}
DoSomething();
}
Вариант 3. Тональный трюк: используйте фальшивый цикл
Другим распространенным трюком, который я вижу, является использование while (true) и break, как показано в других ответах.
while(true)
{
if (!ok) break;
DoSomething();
break; //important
}
DoSomethingNoMatterWhat();
Хотя это менее "честно", чем при использовании goto, он менее подвержен ошибкам при рефакторинге, поскольку он четко отмечает границы логической области. Наивный кодер, который вырезает и вставляет ваши метки или ваши инструкции goto, может вызвать серьезные проблемы! (И, откровенно говоря, картина настолько распространена, что я думаю, что она четко передает намерение, и поэтому не является "нечестным" вообще).
Существуют и другие варианты этих вариантов. Например, можно использовать switch вместо while. Любая языковая конструкция с ключевым словом break, вероятно, будет работать.
Вариант 4. Использовать жизненный цикл объекта
Другой подход использует жизненный цикл объекта. Используйте объект контекста, чтобы переносить ваши параметры (что-то, что наш наивный пример недооценивает) и избавиться от него, когда вы закончите.
class MyContext
{
~MyContext()
{
DoSomethingNoMatterWhat();
}
}
void MainMethod()
{
MyContext myContext;
ok = DoSomething(myContext);
if (!ok)
{
_log.Error("Oops");
return;
}
ok = DoSomethingElse(myContext);
if (!ok)
{
_log.Error("Oops");
return;
}
ok = DoSomethingMore(myContext);
if (!ok)
{
_log.Error("Oops");
}
//DoSomethingNoMatterWhat will be called when myContext goes out of scope
}
Примечание. Обязательно ознакомьтесь с жизненным циклом объекта на выбранном вами языке. Для этого вам нужна какая-то детерминированная сборка мусора, т.е. Вы должны знать, когда будет вызван деструктор. На некоторых языках вам нужно будет использовать Dispose вместо деструктора.
Вариант 4.1. Использовать жизненный цикл объекта (шаблон обертки)
Если вы собираетесь использовать объектно-ориентированный подход, можете сделать это правильно. Эта опция использует класс для "обертывания" ресурсов, требующих очистки, а также других операций.
class MyWrapper
{
bool DoSomething() {...};
bool DoSomethingElse() {...}
void ~MyWapper()
{
DoSomethingNoMatterWhat();
}
}
void MainMethod()
{
bool ok = myWrapper.DoSomething();
if (!ok)
_log.Error("Oops");
return;
}
ok = myWrapper.DoSomethingElse();
if (!ok)
_log.Error("Oops");
return;
}
}
//DoSomethingNoMatterWhat will be called when myWrapper is destroyed
Опять же, убедитесь, что вы понимаете жизненный цикл вашего объекта.
Вариант 5. Уловка языка: используйте оценку короткого замыкания
Другим методом является использование оценки короткого замыкания.
if (DoSomething1() && DoSomething2() && DoSomething3())
{
DoSomething4();
}
DoSomethingNoMatterWhat();
Это решение использует преимущества способа && оператор работает. Когда левая сторона && оценивает значение false, правая сторона никогда не оценивается.
Этот трюк наиболее полезен, когда требуется компактный код и когда код вряд ли увидит много обслуживания, например, вы реализуете хорошо известный алгоритм. Для более общего кодирования структура этого кода слишком хрупкая; даже незначительное изменение логики может вызвать полную перезапись.
-
2См. Также programmers.stackexchange.com/q/122485/11110 .
-
12В заключение? С ++ не имеет окончательного предложения. Объект с деструктором используется в ситуациях, когда вы думаете, что вам нужно предложение finally.
Просто сделай
if( executeStepA() && executeStepB() && executeStepC() )
{
// ...
}
executeThisFunctionInAnyCase();
Это просто.
Из-за трех изменений, каждый из которых коренным образом изменил вопрос (четыре, если пересчитать версию до версии №1), я включаю пример кода, на который я отвечаю:
bool conditionA = executeStepA();
if (conditionA){
bool conditionB = executeStepB();
if (conditionB){
bool conditionC = executeStepC();
if (conditionC){
...
}
}
}
executeThisFunctionInAnyCase();
-
14Я ответил на это (более кратко) в ответ на первую версию вопроса, и он получил 20 голосов, прежде чем был удален Биллом Ящерицей, после некоторого комментария и редактирования Темными Гонками на Орбите.
-
1@ Cheersandhth-Alf: я не могу поверить, что он был удален модом. Это очень плохо. (+1)
Там хороший метод, который не требует дополнительной функции-обертки с операторами return (метод, предписанный Itjax). Он использует псевдо-цикл do while(0). while (0) гарантирует, что он фактически не является циклом, но выполняется только один раз. Однако синтаксис цикла позволяет использовать оператор break.
void foo()
{
// ...
do {
if (!executeStepA())
break;
if (!executeStepB())
break;
if (!executeStepC())
break;
}
while (0);
// ...
}
-
0Продолжайте работать также :)
-
0это очень хорошее наблюдение ... довольно противоречащее стандартному использованию "продолжить" .... :)
Фактически существует способ отложить действия в С++: использование деструктора объекта.
Предполагая, что у вас есть доступ к С++ 11:
class Defer {
public:
Defer(std::function<void()> f): f_(std::move(f)) {}
~Defer() { if (f_) { f_(); } }
void cancel() { f_ = std::function<void()>(); }
private:
Defer(Defer const&) = delete;
Defer& operator=(Defer const&) = delete;
std::function<void()> f_;
}; // class Defer
И затем с помощью этой утилиты:
int foo() {
Defer const defer{&executeThisFunctionInAnyCase}; // or a lambda
// ...
if (!executeA()) { return 1; }
// ...
if (!executeB()) { return 2; }
// ...
if (!executeC()) { return 3; }
// ...
return 4;
} // foo
-
1Мне нравится этот, не знал, как это сделать. Кстати, моя собственная или уродливая? Можешь сказать мне?
-
0@Mayerz: красота в глазах смотрящего :) Основная проблема с вами заключается в том, что она не имеет дело с выполнением некоторого произвольного кода между вызовами
executeA,executeB, ... Это, как говорится, обычный интерфейс (такой как Ваш) может быть очень полезным, чтобы избежать ошибок копирования-вставки (таких какgoto fail;Apple ...)
Вы также можете сделать это:
bool isOk = true;
std::vector<bool (*)(void)> funcs; //vector of function ptr
funcs.push_back(&executeStepA);
funcs.push_back(&executeStepB);
funcs.push_back(&executeStepC);
//...
//this will stop at the first false return
for (auto it = funcs.begin(); it != funcs.end() && isOk; ++it)
isOk = (*it)();
if (isOk)
//doSomeStuff
executeThisFunctionInAnyCase();
Таким образом, у вас есть минимальный линейный размер роста, +1 строка за звонок, и это легко поддается.
EDIT: (Спасибо @Unda) Не большой поклонник, потому что вы теряете видимость IMO:
bool isOk = true;
auto funcs { //using c++11 initializer_list
&executeStepA,
&executeStepB,
&executeStepC
};
for (auto it = funcs.begin(); it != funcs.end() && isOk; ++it)
isOk = (*it)();
if (isOk)
//doSomeStuff
executeThisFunctionInAnyCase();
-
0Я пропустил предлагаемое редактирование случайно, вы можете переделать или прокомментировать?
-
1Речь шла о случайных вызовах функций внутри push_back (), но вы все равно это исправили :)
Будет ли это работать? Я думаю, что это эквивалентно вашему коду.
bool condition = true; // using only one boolean variable
if (condition) condition = executeStepA();
if (condition) condition = executeStepB();
if (condition) condition = executeStepC();
...
executeThisFunctionInAnyCase();
-
3Я обычно вызываю переменную
okкогда использую такую же переменную, как эта. -
1Мне было бы очень интересно узнать, почему отрицательные голоса. Что здесь не так?
Предполагая, что желаемый код выглядит так, как я его сейчас вижу:
bool conditionA = executeStepA();
if (conditionA){
bool conditionB = executeStepB();
if (conditionB){
bool conditionC = executeStepC();
if (conditionC){
...
}
}
}
executeThisFunctionInAnyCase();
Я бы сказал, что правильный подход, в котором он прост, чтобы читать и проще поддерживать, имел бы меньше уровней отступов, которые (в настоящее время) являются заявленной целью вопроса.
// Pre-declare the variables for the conditions
bool conditionA = false;
bool conditionB = false;
bool conditionC = false;
// Execute each step only if the pre-conditions are met
conditionA = executeStepA();
if (conditionA)
conditionB = executeStepB();
if (conditionB)
conditionC = executeStepC();
if (conditionC) {
...
}
// Unconditionally execute the 'cleanup' part.
executeThisFunctionInAnyCase();
Это позволяет избежать необходимости goto s, исключений, фиктивных while циклов или других сложных конструкций и просто переходит к простой задаче.
-
0При использовании циклов обычно допустимо использовать
returnиbreakчтобы выпрыгнуть из цикла без необходимости введения дополнительных переменных «flag». В этом случае использование goto будет также безобидным - помните, что вы торгуете дополнительной сложностью goto для дополнительной изменчивой переменной сложности. -
2@hugomg Переменные были в оригинальном вопросе. Здесь нет никакой дополнительной сложности. По этому вопросу были сделаны предположения (например, что переменные нужны в отредактированном коде), поэтому они были сохранены. Если они не нужны, тогда код можно упростить, но, учитывая неполный характер вопроса, нет другого предположения, которое можно было бы сделать обоснованно.
Вы можете поместить все условия if, отформатированные так, как вы хотите, в своей собственной функции, при возврате выполните функцию executeThisFunctionInAnyCase().
В базовом примере в OP проверка состояния и его выполнение можно отделить как таковое,
void InitialSteps()
{
bool conditionA = executeStepA();
if (!conditionA)
return;
bool conditionB = executeStepB();
if (!conditionB)
return;
bool conditionC = executeStepC();
if (!conditionC)
return;
}
И затем вызывается как таковой,
InitialSteps();
executeThisFunctionInAnyCase();
Если доступны доступные lambdas С++ 11 (в OP не было тега С++ 11, но они все еще могут быть опцией), тогда мы можем отказаться от отдельной функции и обернуть ее в лямбда.
// Capture by reference (variable access may be required)
auto initialSteps = [&]() {
// any additional code
bool conditionA = executeStepA();
if (!conditionA)
return;
// any additional code
bool conditionB = executeStepB();
if (!conditionB)
return;
// any additional code
bool conditionC = executeStepC();
if (!conditionC)
return;
};
initialSteps();
executeThisFunctionInAnyCase();
Можно ли каким-либо образом разбить оператор?
Возможно, это не самое лучшее решение, но вы можете поместить свои операторы в цикл do .. while (0) и использовать операторы break вместо return.
-
2Это был не я, кто проголосовал против него, но это было бы злоупотреблением циклической конструкцией для чего-то, где эффект - это то, что требуется в настоящее время, но неизбежно приведет к боли. Вероятно, для следующего разработчика, который должен поддерживать его через 2 года после того, как вы перешли к другому проекту.
-
3@ClickRick с использованием
do .. while (0)для определений макросов также использует циклы, но считается, что все в порядке.
Если вам не нравятся goto и не нравятся циклы do { } while (0); и, как использование С++, вы также можете использовать временную лямбду, чтобы иметь тот же эффект.
[&]() { // create a capture all lambda
if (!executeStepA()) { return; }
if (!executeStepB()) { return; }
if (!executeStepC()) { return; }
}(); // and immediately call it
executeThisFunctionInAnyCase();
-
0@ClickRick всегда трудно угодить всем. По моему мнению, не существует такой вещи, как C / C ++, которую вы обычно кодируете в одном из них, и использование другого не одобряется.
Вы просто делаете это.
coverConditions();
executeThisFunctionInAnyCase();
function coverConditions()
{
bool conditionA = executeStepA();
if (!conditionA) return;
bool conditionB = executeStepB();
if (!conditionB) return;
bool conditionC = executeStepC();
if (!conditionC) return;
}
99 раз 100, это единственный способ сделать это.
Никогда, никогда, никогда не пытайтесь сделать что-то "сложное" в компьютерном коде.
Кстати, я уверен, что следующее фактическое решение , которое вы имели в виду...
Оператор continue критичен в алгоритмическом программировании. (То есть, утверждение goto имеет решающее значение в алгоритмическом программировании.)
На многих языках программирования вы можете сделать это:
-(void)_testKode
{
NSLog(@"code a");
NSLog(@"code b");
NSLog(@"code c\n");
int x = 69;
{
if ( x == 13 )
{
NSLog(@"code d---\n");
continue;
}
if ( x == 69 )
{
NSLog(@"code e---\n");
continue;
}
if ( x == 13 )
{
NSLog(@"code f---\n");
continue;
}
}
NSLog(@"code g");
}
(Обратите внимание, прежде всего: голые блоки, подобные этому примеру, являются важной и важной частью написания красивого кода, особенно если вы имеете дело с алгоритмическим программированием.)
Опять же, что именно то, что у вас было в голове, правильно? И это прекрасный способ написать это, так что у вас есть хорошие инстинкты.
Тем не менее, трагически, в текущей версии objective-c (кроме того, я не знаю о Swift, извините), существует понятная функция, где он проверяет, является ли охватывающий блок циклом.

Вот как вы обойдете это...
-(void)_testKode
{
NSLog(@"code a");
NSLog(@"code b");
NSLog(@"code c\n");
int x = 69;
do{
if ( x == 13 )
{
NSLog(@"code d---\n");
continue;
}
if ( x == 69 )
{
NSLog(@"code e---\n");
continue;
}
if ( x == 13 )
{
NSLog(@"code f---\n");
continue;
}
}while(false);
NSLog(@"code g");
}
Так что не забывайте, что..
do {} while (false);
просто означает "сделать этот блок один раз".
т.е. нет совершенно никакой разницы между написанием do{}while(false); и просто записью {}.
Теперь это работает отлично, как вы хотели... здесь вывод...
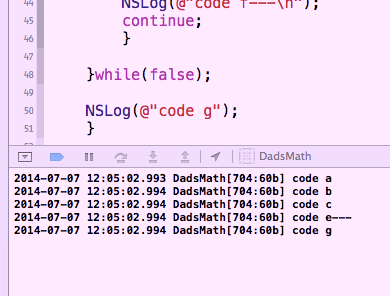
Итак, возможно, что вы видите алгоритм в своей голове. Вы всегда должны пытаться написать, что у вас в голове. (В частности, если вы не трезвы, потому что, когда симпатичный выходит!:))
В "алгоритмических" проектах, где это происходит много, в objective-c у нас всегда есть макрос вроде...
#define RUNONCE while(false)
... так что вы можете это сделать...
-(void)_testKode
{
NSLog(@"code a");
int x = 69;
do{
if ( x == 13 )
{
NSLog(@"code d---\n");
continue;
}
if ( x == 69 )
{
NSLog(@"code e---\n");
continue;
}
if ( x == 13 )
{
NSLog(@"code f---\n");
continue;
}
}RUNONCE
NSLog(@"code g");
}
Есть две точки:
a, хотя и глупо, что objective-c проверяет тип блока, в котором находится оператор continue, и он беспокоится о "борьбе с этим". Так что это жесткое решение.
b, возникает вопрос, должен ли вы отступать, в примере, что этот блок? Я теряю сон над такими вопросами, поэтому не могу советовать.
Надеюсь, что это поможет.
-
0Вы пропустили второй лучший ответ .
-
0Вы положили награду, чтобы получить больше представителей? :)
Цепочки IF/ELSE в вашем коде не являются проблемой языка, а дизайном вашей программы. Если вы можете повторно использовать или перезаписать свою программу, я хотел бы предложить вам посмотреть в шаблонах проектирования (http://sourcemaking.com/design_patterns), чтобы найти лучшее решение.
Обычно, когда вы видите много IF и еще в своем коде, это возможность реализовать шаблон разработки стратегии (http://sourcemaking.com/design_patterns/strategy/c-sharp-dot-net) или, может быть, сочетание других паттернов.
Я уверен, что есть альтернативы для написания длинного списка if/else, но я сомневаюсь, что они изменят что-либо, кроме того, что цепочка будет выглядеть вам симпатично (Тем не менее, красота в глазах смотрящего все еще также относится к коду:-)). Вы должны быть обеспокоены такими вещами, как (через 6 месяцев, когда у меня появилось новое условие, и я ничего не помню об этом коде, могу ли я легко добавить его? Или что, если цепочка изменится, как быстро и безошибочно я его реализую)
-
2Совершенно верно. ОП нуждается в новых абстракциях.
Уже много хороших ответов, но большинство из них, похоже, компромиссны с некоторыми (правда, очень мало) гибкостью. Общий подход, который не требует этого компромисса, заключается в добавлении переменной состояния/сохранения. Цена, конечно, одна дополнительная ценность для отслеживания:
bool ok = true;
bool conditionA = executeStepA();
// ... possibly edit conditionA, or just ok &= executeStepA();
ok &= conditionA;
if (ok) {
bool conditionB = executeStepB();
// ... possibly do more stuff
ok &= conditionB;
}
if (ok) {
bool conditionC = executeStepC();
ok &= conditionC;
}
if (ok && additionalCondition) {
// ...
}
executeThisFunctionInAnyCase();
// can now also:
return ok;
-
0Почему
ok &= conditionX;а не простоok = conditionX;? -
0@ user3253359 Во многих случаях, да, вы можете сделать это. Это концептуальная демонстрация; в рабочем коде мы постараемся максимально упростить его
Пусть ваши функции выполнения выдают исключение, если они не работают, а не возвращают false. Тогда ваш код вызова может выглядеть так:
try {
executeStepA();
executeStepB();
executeStepC();
}
catch (...)
Конечно, я предполагаю, что в вашем исходном примере шаг выполнения вернет false только в случае ошибки, возникающей внутри шага?
-
3использование исключения для управления потоком часто считается плохой практикой и вонючим кодом
Если ваш код так же прост, как ваш пример, и ваш язык поддерживает оценки короткого замыкания, вы можете попробовать следующее:
StepA() && StepB() && StepC() && StepD();
DoAlways();
Если вы передаете аргументы своим функциям и возвращаете другие результаты, чтобы ваш код не мог быть написан ранее, многие другие ответы лучше подходят для проблемы.
-
0Фактически я отредактировал свой вопрос, чтобы лучше объяснить тему, но он был отклонен, чтобы не сделать недействительными большинство ответов. : \
-
0Я новый пользователь в SO и начинающий программист. 2 вопроса: есть ли риск, что другой вопрос, такой как тот, который вы сказали, будет помечен как дублированный из-за ЭТОГО вопроса? Еще один момент: как мог пользователь / программист новичка SO выбрать лучший ответ среди всех (почти, наверное, хорошо)?
Для С++ 11 и выше хорошим подходом может быть реализация системы выхода области, подобной D scope (exit) механизм.
Один из возможных способов его реализации - использовать lambdas С++ 11 и некоторые вспомогательные макросы:
template<typename F> struct ScopeExit
{
ScopeExit(F f) : fn(f) { }
~ScopeExit()
{
fn();
}
F fn;
};
template<typename F> ScopeExit<F> MakeScopeExit(F f) { return ScopeExit<F>(f); };
#define STR_APPEND2_HELPER(x, y) x##y
#define STR_APPEND2(x, y) STR_APPEND2_HELPER(x, y)
#define SCOPE_EXIT(code)\
auto STR_APPEND2(scope_exit_, __LINE__) = MakeScopeExit([&](){ code })
Это позволит вам вернуться к предыдущей функции и гарантировать, что любой код очистки, который вы определяете, всегда выполняется при выходе из области:
SCOPE_EXIT(
delete pointerA;
delete pointerB;
close(fileC); );
if (!executeStepA())
return;
if (!executeStepB())
return;
if (!executeStepC())
return;
Макросы действительно просто украшают. MakeScopeExit() можно использовать напрямую.
-
0Для этой работы нет необходимости в макросах. И
[=]обычно не подходит для лямбды с ограниченным диапазоном. -
0Да, макросы просто для украшения и могут быть выброшены. Но разве вы не сказали бы, что захват по стоимости - это самый безопасный «общий» подход?
В С++ (вопрос отмечен как C и С++), если вы не можете изменять функции для использования исключений, вы все равно можете использовать механизм исключения, если вы пишете небольшую вспомогательную функцию, например
struct function_failed {};
void attempt(bool retval)
{
if (!retval)
throw function_failed(); // or a more specific exception class
}
Затем ваш код мог бы читать следующее:
try
{
attempt(executeStepA());
attempt(executeStepB());
attempt(executeStepC());
}
catch (function_failed)
{
// -- this block intentionally left empty --
}
executeThisFunctionInAnyCase();
Если вы используете фантастический синтаксис, вместо него вы можете заставить его работать с явным приложением:
struct function_failed {};
struct attempt
{
attempt(bool retval)
{
if (!retval)
throw function_failed();
}
};
Затем вы можете написать свой код как
try
{
(attempt) executeStepA();
(attempt) executeStepB();
(attempt) executeStepC();
}
catch (function_failed)
{
// -- this block intentionally left empty --
}
executeThisFunctionInAnyCase();
-
0Преобразование проверок значений в исключения не обязательно является хорошим способом, есть значительные накладные расходы, связанные с раскручиванием исключений.
-
4-1 Использование исключений для нормального потока в C ++, как это - плохая практика программирования. В C ++ исключения должны быть зарезервированы для исключительных обстоятельств.
Почему никто не дает простейшего решения?: D
Если все ваши функции имеют одну и ту же подпись, вы можете сделать это так (для языка C):
bool (*step[])() = {
&executeStepA,
&executeStepB,
&executeStepC,
...
};
for (int i = 0; i < numberOfSteps; i++) {
bool condition = step[i]();
if (!condition) {
break;
}
}
executeThisFunctionInAnyCase();
Для чистого решения на С++ вы должны создать класс интерфейса, который содержит метод execute и обертывает ваши шаги в объектах.
Затем решение выше будет выглядеть так:
Step *steps[] = {
stepA,
stepB,
stepC,
...
};
for (int i = 0; i < numberOfSteps; i++) {
Step *step = steps[i];
if (!step->execute()) {
break;
}
}
executeThisFunctionInAnyCase();
Это выглядит как конечный автомат, что удобно, потому что вы можете легко реализовать его с помощью шаблона состояния.
В Java это будет выглядеть примерно так:
interface StepState{
public StepState performStep();
}
Реализация будет работать следующим образом:
class StepA implements StepState{
public StepState performStep()
{
performAction();
if(condition) return new StepB()
else return null;
}
}
И так далее. Затем вы можете заменить большое условие if:
Step toDo = new StepA();
while(toDo != null)
toDo = toDo.performStep();
executeThisFunctionInAnyCase();
Как упоминал Ромик, вы можете применить шаблон дизайна для этого, но я бы использовал шаблон Decorator, а не Strategy, так как вы хотите цеплять вызовы. Если код прост, то я бы пошел с одним из хорошо структурированных ответов, чтобы предотвратить вложенность. Однако, если он сложный или требует динамической цепочки, то шаблон Decorator является хорошим выбором. Вот диаграмма классов yUML:
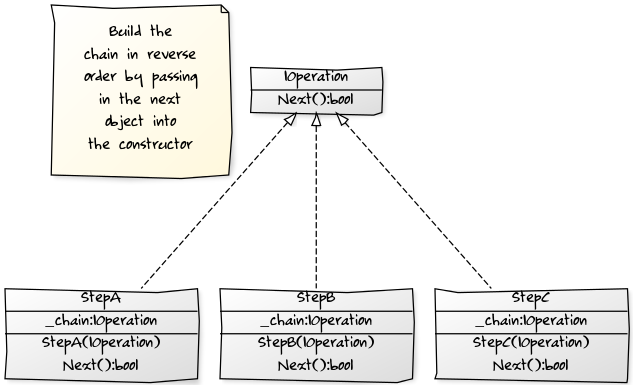
Вот пример LinqPad Программа С#:
void Main()
{
IOperation step = new StepC();
step = new StepB(step);
step = new StepA(step);
step.Next();
}
public interface IOperation
{
bool Next();
}
public class StepA : IOperation
{
private IOperation _chain;
public StepA(IOperation chain=null)
{
_chain = chain;
}
public bool Next()
{
bool localResult = false;
//do work
//...
// set localResult to success of this work
// just for this example, hard coding to true
localResult = true;
Console.WriteLine("Step A success={0}", localResult);
//then call next in chain and return
return (localResult && _chain != null)
? _chain.Next()
: true;
}
}
public class StepB : IOperation
{
private IOperation _chain;
public StepB(IOperation chain=null)
{
_chain = chain;
}
public bool Next()
{
bool localResult = false;
//do work
//...
// set localResult to success of this work
// just for this example, hard coding to false,
// to show breaking out of the chain
localResult = false;
Console.WriteLine("Step B success={0}", localResult);
//then call next in chain and return
return (localResult && _chain != null)
? _chain.Next()
: true;
}
}
public class StepC : IOperation
{
private IOperation _chain;
public StepC(IOperation chain=null)
{
_chain = chain;
}
public bool Next()
{
bool localResult = false;
//do work
//...
// set localResult to success of this work
// just for this example, hard coding to true
localResult = true;
Console.WriteLine("Step C success={0}", localResult);
//then call next in chain and return
return (localResult && _chain != null)
? _chain.Next()
: true;
}
}
Лучшая книга для чтения по шаблонам дизайна, IMHO, Головка первых шаблонов дизайна.
-
0Какая польза от этого по сравнению с ответом Джеффри?
-
0гораздо более устойчивы к изменениям, когда требования меняются, таким подходом проще управлять без особых знаний предметной области. Особенно, если учесть, насколько глубокими и длинными могут быть некоторые разделы вложенных ifs. Все это может стать очень хрупким и, следовательно, с большим риском работать. Не поймите меня неправильно, некоторые сценарии оптимизации могут привести к тому, что вы перестанете это делать и вернетесь к ifs, но в 99% случаев это нормально. Но дело в том, что когда вы переходите на этот уровень, вас не волнует ремонтопригодность, вам нужна производительность.
Предполагая, что вам не нужны отдельные переменные условия, инвертируя тесты и используя else-falthrough, поскольку путь "ok" позволит вам получить более вертикальный набор операторов if/else:
bool failed = false;
// keep going if we don't fail
if (failed = !executeStepA()) {}
else if (failed = !executeStepB()) {}
else if (failed = !executeStepC()) {}
else if (failed = !executeStepD()) {}
runThisFunctionInAnyCase();
Опустить неудачную переменную делает код слишком скрытым IMO.
Объявление переменных внутри прекрасно, не беспокойтесь о = vs ==.
// keep going if we don't fail
if (bool failA = !executeStepA()) {}
else if (bool failB = !executeStepB()) {}
else if (bool failC = !executeStepC()) {}
else if (bool failD = !executeStepD()) {}
else {
// success !
}
runThisFunctionInAnyCase();
Это неясно, но компактно:
// keep going if we don't fail
if (!executeStepA()) {}
else if (!executeStepB()) {}
else if (!executeStepC()) {}
else if (!executeStepD()) {}
else { /* success */ }
runThisFunctionInAnyCase();
Чтобы улучшить ответ Mathieu С++ 11 и избежать затрат времени выполнения, вызванных использованием std::function, я бы предложил использовать следующие
template<typename functor>
class deferred final
{
public:
template<typename functor2>
explicit deferred(functor2&& f) : f(std::forward<functor2>(f)) {}
~deferred() { this->f(); }
private:
functor f;
};
template<typename functor>
auto defer(functor&& f) -> deferred<typename std::decay<functor>::type>
{
return deferred<typename std::decay<functor>::type>(std::forward<functor>(f));
}
Этот простой класс шаблонов будет принимать любой функтор, который можно вызывать без каких-либо параметров, и делает это без каких-либо распределений динамической памяти и поэтому лучше соответствует цели абстракции С++ без лишних накладных расходов. Дополнительный шаблон функции предназначен для упрощения использования путем вычитания параметра шаблона (который недоступен для параметров шаблона класса)
Пример использования:
auto guard = defer(executeThisFunctionInAnyCase);
bool conditionA = executeStepA();
if (!conditionA) return;
bool conditionB = executeStepB();
if (!conditionB) return;
bool conditionC = executeStepC();
if (!conditionC) return;
Так же, как Матье отвечает, это решение полностью безопасно для всех, и executeThisFunctionInAnyCase будет вызываться во всех случаях. Если сам executeThisFunctionInAnyCase бросает, деструкторы неявно помечены noexcept, и поэтому вызывается вызов std::terminate вместо того, чтобы вызывать исключение во время разматывания стека.
-
0+1 Я искал этот ответ, чтобы мне не пришлось его публиковать. Вы должны использовать
functorсовершенный вперед» вdeferredконструкторе, не нужно форсироватьmove. -
0@Yakk изменил конструктор на конструктор пересылки
Несколько ответов были намечены на шаблон, который я видел и использовал много раз, особенно в сетевом программировании. В сетевых стеках часто бывает длинная последовательность запросов, любая из которых может завершиться неудачей и остановит процесс.
Общая картина заключалась в использовании do { } while (false);
Я использовал макрос для while(false), чтобы сделать его do { } once;. Общий шаблон:
do
{
bool conditionA = executeStepA();
if (! conditionA) break;
bool conditionB = executeStepB();
if (! conditionB) break;
// etc.
} while (false);
Этот шаблон был относительно прост для чтения и позволял использовать объекты, которые должным образом разрушали бы, а также избегали множественных возвратов, что упрощало бы отладку и отладку.
Другой подход - цикл do - while, хотя он упоминался ранее, и не было примера этого, который бы показал, как это выглядит:
do
{
if (!executeStepA()) break;
if (!executeStepB()) break;
if (!executeStepC()) break;
...
break; // skip the do-while condition :)
}
while (0);
executeThisFunctionInAnyCase();
(Ну, уже есть ответ с циклом while, но цикл do - while не избыточно проверяет значение true (в начале), а вместо этого в конце xD (это может быть пропущено, хотя)).суб >
-
0Привет, Заффи - в этом ответе подробно объясняется подход do {} while (false). stackoverflow.com/a/24588605/294884 Два других ответа также упоминали об этом.
-
0Это увлекательный вопрос, будет ли элегантнее использовать CONTINUE или BREAK в этой ситуации!
интересным способом является работа с исключениями.
try
{
executeStepA();//function throws an exception on error
......
}
catch(...)
{
//some error handling
}
finally
{
executeThisFunctionInAnyCase();
}
Если вы напишете такой код, вы пойдете как-то не в том направлении. Я не буду рассматривать это как "проблему", чтобы иметь такой код, но иметь такую грязную "архитектуру".
Совет: обсудите эти случаи с опытным разработчиком, которому вы доверяете; -)
-
0Я думаю, что эта идея не может заменить каждую цепочку if. Во всяком случае, во многих случаях это очень хороший подход!
Кажется, что вы хотите выполнить весь свой вызов из одного блока.
Как и предлагали другие, вы должны использовать либо цикл while, и оставить с помощью break или новую функцию, которую вы можете оставить с помощью return (может быть чище).
Я лично изгоняю goto, даже для выхода функции. Их сложнее обнаружить при отладке.
Элегантной альтернативой, которая должна работать для вашего рабочего процесса, является создание массива функций и итерация на этом.
const int STEP_ARRAY_COUNT = 3;
bool (*stepsArray[])() = {
executeStepA, executeStepB, executeStepC
};
for (int i=0; i<STEP_ARRAY_COUNT; ++i) {
if (!stepsArray[i]()) {
break;
}
}
executeThisFunctionInAnyCase();
-
0К счастью, отладчик замечает их для вас. Если вы отлаживаете код, а не пошагово просматриваете код, вы делаете это неправильно.
-
0Я не понимаю, что вы имеете в виду, и почему я не могу использовать одноступенчатый?
Альтернативным решением будет определение идиомы с помощью макросов.
#define block for(int block = 0; !block; block++)
Теперь "block" может быть выведен с помощью break так же, как for(;;) и while(). Пример:
int main(void) {
block {
if (conditionA) {
// Do stuff A...
break;
}
if (conditionB) {
// Do stuff B...
break;
}
if (conditionC) {
// Do stuff C...
break;
}
else {
// Do default stuff...
}
} /* End of "block" statement */
/* ---> The "break" sentences jump here */
return 0;
}
Несмотря на конструкцию "for (;;)", оператор "block" выполняется только один раз.
Эти "блоки" могут быть выведены с предложениями break.
Следовательно, избегаются цепочки предложений if else if else if....
В лучшем случае, последний else может висеть в конце "блока", чтобы обрабатывать случаи "по умолчанию".
Этот метод призван избежать типичного и уродливого метода do { ... } while(0).
В макросе block определяется переменная, также называемая block, определенная таким образом, что выполняется ровно 1 итерация for. В соответствии с правилами подстановки для макросов идентификатор block внутри определения макроса block не рекурсивно заменен, поэтому block становится идентификатором, недоступным программисту, но внутренне хорошо работает для управления "скрытым" for(;;).
Более того: эти "блоки" могут быть вложенными, поскольку скрытая переменная int block будет иметь разные области действия.
-
0Мне лично нравится программировать таким образом. Вы можете часто использовать макросы для создания эффективных, хорошо контролируемых структур, которые не существуют в языке.
Простое решение использует логическую переменную condition, и ее можно повторно использовать снова и снова, чтобы проверить все результаты шагов, выполняемых в последовательности:
bool cond = executeStepA();
if(cond) cond = executeStepB();
if(cond) cond = executeStepC();
if(cond) cond = executeStepD();
executeThisFunctionInAnyCase();
Не нужно было делать это заранее: bool cond = true;... а затем следует if (cond) cond = executeStepA(); Переменная cond может быть сразу назначена на результат executeStepA(), поэтому сделать код еще короче и проще читать.
Еще один необычный, но забавный подход - это (некоторые могут подумать, что это хороший кандидат для IOCCC, но все же):
!executeStepA() ? 0 :
!executeStepB() ? 0 :
!executeStepC() ? 0 :
!executeStepD() ? 0 : 1 ;
executeThisFunctionInAnyCase();
Результат точно такой же, как если бы мы сделали то, что выложили OP, т.е.:
if(executeStepA()){
if(executeStepB()){
if(executeStepC()){
if(executeStepD()){
}
}
}
}
executeThisFunctionInAnyCase();
-
0Это дублирует ответ Крумии .
-
0На самом деле, этот подход использует на 1 строку кода меньше для того же результата.
Просто боковое примечание; когда область if всегда вызывает return (или перерыв в цикле), тогда не используйте оператор else. Это может сэкономить вам много отступов в целом.
Вот трюк, который я использовал несколько раз, как в C-whatever, так и в Java:
do {
if (!condition1) break;
doSomething();
if (!condition2) break;
doSomethingElse()
if (!condition3) break;
doSomethingAgain();
if (!condition4) break;
doYetAnotherThing();
} while(FALSE); // Or until(TRUE) or whatever your language likes
Я предпочитаю его для вложенных ifs для его ясности, особенно когда они правильно отформатированы с четкими комментариями для каждого условия.
-
0В Java я бы просто решил это с помощью return и
finallyблока.
Поскольку у вас также есть [... блок кода...] между исполнениями, я предполагаю, что у вас есть выделение памяти или инициализация объекта. Таким образом, вы должны заботиться о том, чтобы очистить все, что вы уже инициализировали при выходе, а также очистить его, если вы встретите проблему, и любая из функций вернет false.
В этом случае лучшее, что у меня было в моем опыте (когда я работал с CryptoAPI), создавало небольшие классы, в конструкторе вы инициализировали свои данные, в деструкторе вы не инициализировали его. Каждый следующий класс функций должен быть дочерним по отношению к предыдущему классу функций. Если что-то пошло не так - выбросьте исключение.
class CondA
{
public:
CondA() {
if (!executeStepA())
throw int(1);
[Initialize data]
}
~CondA() {
[Clean data]
}
A* _a;
};
class CondB : public CondA
{
public:
CondB() {
if (!executeStepB())
throw int(2);
[Initialize data]
}
~CondB() {
[Clean data]
}
B* _b;
};
class CondC : public CondB
{
public:
CondC() {
if (!executeStepC())
throw int(3);
[Initialize data]
}
~CondC() {
[Clean data]
}
C* _c;
};
И тогда в вашем коде вам просто нужно позвонить:
shared_ptr<CondC> C(nullptr);
try{
C = make_shared<CondC>();
}
catch(int& e)
{
//do something
}
if (C != nullptr)
{
C->a;//work with
C->b;//work with
C->c;//work with
}
executeThisFunctionInAnyCase();
Я думаю, это лучшее решение, если каждый вызов ConditionX инициализирует что-то, выделяет память и т.д. Лучше всего убедиться, что все будет очищено.
Очень просто.
if ((bool conditionA = executeStepA()) &&
(bool conditionB = executeStepB()) &&
(bool conditionC = executeStepC())) {
...
}
executeThisFunctionInAnyCase();
Это также сохранит логические переменные conditionA, conditionB и conditionC.
[&]{
bool conditionA = executeStepA();
if (!conditionA) return; // break
bool conditionB = executeStepB();
if (!conditionB) return; // break
bool conditionC = executeStepC();
if (!conditionC) return; // break
}();
executeThisFunctionInAnyCase();
Мы создаем анонимную лямбда-функцию с неявным контрольным захватом и запускаем ее. Код внутри него запускается немедленно.
Когда он хочет остановиться, он просто return s.
Затем, после запуска, запустите executeThisFunctionInAnyCase.
return в пределах лямбда есть break до конца блока. Любой другой вид управления потоком работает.
Исключения остаются в силе - если вы хотите их поймать, сделайте это явно. Будьте осторожны при запуске executeThisFunctionInAnyCase, если выбраны исключения - вы вообще не хотите запускать executeThisFunctionInAnyCase, если он может генерировать исключение в обработчике исключений, поскольку это приводит к беспорядку (какой беспорядок будет зависеть от языка).
Хорошим свойством таких встроенных функций, основанных на захвате, можно реорганизовать существующий код на место. Если ваша функция становится очень длинной, ее можно разбить на составные части.
Вариант этого, который работает на других языках, это:
bool working = executeStepA();
working = working && executeStepB();
working = working && executeStepC();
executeThisFunctionInAnyCase();
где вы пишете отдельные строки, каждый из которых имеет короткое замыкание. Код может быть введен между этими строками, что дает вам несколько "в любом случае", или вы можете сделать if(working) { /* code */ } между шагами выполнения, чтобы включить код, который должен запускаться тогда и только тогда, когда вы еще не вышли из него.
Хорошее решение этой проблемы должно быть устойчивым перед добавлением нового управления потоком.
В С++ лучшее решение объединяет быстрый класс scope_guard:
#ifndef SCOPE_GUARD_H_INCLUDED_
#define SCOPE_GUARD_H_INCLUDED_
template<typename F>
struct scope_guard_t {
F f;
~scope_guard_t() { f(); }
};
template<typename F>
scope_guard_t<F> scope_guard( F&& f ) { return {std::forward<F>(f)}; }
#endif
то в рассматриваемом коде:
auto scope = scope_guard( executeThisFunctionInAnyCase );
bool conditionA = executeStepA();
if (!conditionA) return;
bool conditionB = executeStepB();
if (!conditionB) return;
bool conditionC = executeStepC();
if (!conditionC) return;
а деструктор scope automaticlaly работает executeThisFunctionInAnyCase. Вы можете вводить все больше и больше "в конце области действия" (давая каждому другое имя) всякий раз, когда вы создаете ресурс, не относящийся к RAII, который нуждается в очистке. Он также может принимать lambdas, поэтому вы можете манипулировать локальными переменными.
Защитники области Fancier могут поддерживать прерывание вызова в деструкторе (с защитой bool), блокировать/разрешать копирование и перемещение, а также поддерживать "переносимые" защитные маски с типом, которые могут быть возвращены из внутренних контекстов.
После прочтения всех ответов я хочу предложить один новый подход, который может быть вполне понятным и читаемым в правильных обстоятельствах: шаблон состояния.
Если вы упаковываете все методы (executeStepX) в Object-класс, он может иметь атрибут getState()
class ExecutionChain
{
public:
enum State
{
Start,
Step1Done,
Step2Done,
Step3Done,
Step4Done,
FinalDone,
};
State getState() const;
void executeStep1();
void executeStep2();
void executeStep3();
void executeStep4();
void executeFinalStep();
private:
State _state;
};
Это позволит вам сгладить ваш код выполнения:
void execute
{
ExecutionChain chain;
chain.executeStep1();
if ( chain.getState() == Step1Done )
{
chain.executeStep2();
}
if ( chain.getState() == Step2Done )
{
chain.executeStep3();
}
if ( chain.getState() == Step3Done )
{
chain.executeStep4();
}
chain.executeFinalStep();
}
Таким образом, он легко читается, легко отлаживается, у вас есть четкое управление потоком, а также может вставлять новые более сложные типы поведения (например, выполнять специальный шаг только в том случае, если выполняется хотя бы Step2)...
Моя проблема с другими подходами, такими как ok = execute(); и if (execute()) - это то, что ваш код должен быть четким и читаемым, как блок-схема того, что происходит. На блок-схеме вы должны выполнить два шага: 1. выполнить 2. решение на основе результата
Таким образом, вы не должны скрывать свои важные методы тяжелой атлетики внутри if-утверждений или подобных, они должны стоять сами по себе!
Как сказал @Jefffrey, вы можете использовать условную функцию короткого замыкания почти на каждом языке, мне лично не нравятся условные утверждения с более чем 2-мя условиями (более одного && или ||), а только вопрос стиль. Этот код делает то же самое (и, вероятно, будет компилировать то же самое), и он выглядит немного чище для меня. Вам не нужны фигурные скобки, перерывы, возвращения, функции, lambdas (только С++ 11), объекты и т.д., Если каждая функция в executeStepX() возвращает значение, которое может быть добавлено к true, если следующий оператор должен быть выполнен или false в противном случае.
if (executeStepA())
if (executeStepB())
if (executeStepC())
//...
if (executeStepN()); // <-- note the ';'
executeThisFunctionInAnyCase();
Каждый раз, когда какая-либо из функций возвращает false, ни одна из следующих функций не вызывается.
Мне понравился ответ @Mayerz, так как вы можете изменять функции, которые должны быть вызваны (и их порядок) во время выполнения. Этот тип выглядит как шаблон наблюдателя, где у вас есть группа подписчиков (функций, объектов и т.д.), Которые вызываются и выполняются всякий раз, когда заданный произвольный условие выполнено. Во многих случаях это может быть чрезмерным, поэтому используйте его мудро :)
Вы можете использовать "оператор switch"
switch(x)
{
case 1:
//code fires if x == 1
break;
case 2:
//code fires if x == 2
break;
...
default:
//code fires if x does not match any case
}
эквивалентно:
if (x==1)
{
//code fires if x == 1
}
else if (x==2)
{
//code fires if x == 2
}
...
else
{
//code fires if x does not match any of the if above
}
Однако я бы сказал, что не нужно избегать if-else-цепей. Одно из ограничений операторов switch заключается в том, что они проверяют только точное соответствие; то есть вы не можете проверить "случай x < 3" --- на С++, который выдает ошибку, а на C он может работать, но ведет себя непредсказуемыми способами, что хуже, чем выброс ошибки, потому что ваша программа будет неисправна в неожиданных пути.
-
0Это никак не связано с первоначальным вопросом.
В некоторых особых ситуациях виртуальное дерево наследования и вызовы виртуальных методов могут обрабатывать вашу логику дерева решений.
objectp -> DoTheRightStep();
Я встречал ситуации, когда это работало как волшебная палочка. Конечно, это имеет смысл, если ваш ConditionX можно последовательно преобразовать в условия "Object Is A".
Почему использование ООП? в псевдокоде:
abstract class Abstraction():
function executeStepA(){...};
function executeStepB(){...};
function executeStepC(){...};
function executeThisFunctionInAnyCase(){....}
abstract function execute():
class A(Abstraction){
function execute(){
executeStepA();
executeStepB();
executeStepC();
}
}
class B(Abstraction){
function execute(){
executeStepA();
executeStepB();
}
}
class C(Abstraction){
function execute(){
executeStepA();
}
}
таким образом ваш if dissapear
item.execute();
item.executeThisFunctionInAnyCase();
Как правило, ifs можно избежать с помощью ООП.
Хорошо, 50+ ответов пока, и никто не упомянул, что я обычно делаю в этой ситуации! (т.е. операция, состоящая из нескольких этапов, но было бы излишним использовать конечный автомат или таблицу указателей функций):
if ( !executeStepA() )
{
// error handling for "A" failing
}
else if ( !executeStepB() )
{
// error handling for "B" failing
}
else if ( !executeStepC() )
{
// error handling for "C" failing
}
else
{
// all steps succeeded!
}
executeThisFunctionInAnyCase();
Преимущества:
- В итоге нет огромного уровня отступа
- Код обработки ошибок (необязательно) находится в строках сразу после вызова неудавшейся функции
Недостатки:
- Может оказаться уродливым, если у вас есть шаг, который не просто завернут в один вызов функции
- Получает уродливость, если требуется какой-либо поток, кроме "выполнить шаги по порядку, прервать, если не удастся"
-
0Проблема этого подхода заключается в том, что различные условия A, B и C могут быть совершенно не связаны, что затрудняет понимание кода. Длинные операторы if ... else if желательно использовать только тогда, когда условия связаны друг с другом.
-
0Не согласен, нет необходимости связывать какие-либо шаги, чтобы эта структура работала. Единственная общая черта - это необходимость пропустить цепочку if ... else в случае сбоя.
Уже упоминались фальшивые циклы, но в ответах, которые были даны до сих пор, я не видел следующий трюк: вы можете использовать do { /* ... */ } while( evaulates_to_zero() ); для реализации двунаправленного раннего выключателя. Использование break завершает цикл, не анализируя оператор условия, тогда как a continue будет вызывать утверждение условия.
Вы можете использовать это, если у вас есть два типа финализации, где один путь должен выполнять немного больше работы, чем другой:
#include <stdio.h>
#include <ctype.h>
int finalize(char ch)
{
fprintf(stdout, "read a character: %c\n", (char)toupper(ch));
return 0;
}
int main(int argc, char *argv[])
{
int ch;
do {
ch = fgetc(stdin);
if( isdigit(ch) ) {
fprintf(stderr, "read a digit (%c): aborting!\n", (char)ch);
break;
}
if( isalpha(ch) ) {
continue;
}
fprintf(stdout, "thank you\n");
} while( finalize(ch) );
return 0;
}
Выполнение этого дает следующий протокол сеанса:
dw@narfi ~/misc/test/fakeloopbreak $ ./fakeloopbreak
-
thank you
read a character: -
dw@narfi ~/misc/test/fakeloopbreak $ ./fakeloopbreak
a
read a character: A
dw@narfi ~/misc/test/fakeloopbreak $ ./fakeloopbreak
1
read a digit (1): aborting!
-
0Daten, что случилось. Вы сделали отличное замечание, что можете использовать разрыв против продолжения, в зависимости от того, хотите ли вы мелочи в конце. {Тем не менее, это ужасное программирование для игры в гольф без места в реальном мире! Совершенно невероятно, чтобы вы делали это в обычном коде, чтобы заставить самолеты летать или что-то еще. ;-)
-
0@JoeBlow: Может быть, не самолеты, но вы можете найти сотни таких конструкций в прошивке устройства, которое в долгосрочной перспективе может оказаться в медицинских изделиях (пока оно нацелено на медицинские исследования). Обычно они являются частью транзакций конфигурации оборудования, где для успешного завершения транзакции не требуется откат, в то время как прерывание транзакции требует очистки, а обнаружение сбоя оборудования должно перевести устройство в отказоустойчивое состояние без чрезмерного разрушения. состояние конфигурации, так что проблема может быть отлажена / записана для диагностики с помощью кода паники.
Как избежать цепей "если"?
Я еще не нашел ответа, используя рекурсию. (Прекрати мне, если ты это слышал;)
Я также не нашел поддержки для определения того, какое из if-clauses терпит неудачу (думаю, многопоточность)... (однажды я столкнулся с 40 глубокой цепочкой во встроенной системе.) В рамках поддержки отладки я использовал BitSet.
// here I use 26 bits in a result bitset - you can use as many bits as you need
typedef std::bitset<26> BitSet26;
Мой метод рекурсии требует некоторой поддержки... для выполнения выбора шага:
int executeStep(int i, bool& retVal)
{
int nxt = 0;
switch (i)
{
case 'A': { retVal = executeStepA(); nxt = 'B'; } break;
case 'B': { retVal = executeStepB(); nxt = 'C'; } break;
case 'C': { retVal = executeStepC(); nxt = 'D'; } break;
case 'D': { retVal = executeStepD(); nxt = 'I'; } break;
// ...
case 'I': { retVal = executeStepI(); nxt = 'J'; } break;
case 'J': { retVal = executeStepJ(); nxt = 'R'; } break;
// ...
case 'R': { retVal = executeStepR(); nxt = 'S'; } break;
case 'S': { retVal = executeStepS(); nxt = 'Z'; } break;
// ...
case 'Z': { retVal = executeStepZ(); nxt = 0; } break;
default: { retVal = false; nxt = 0; } break;
}
return(nxt);
}
Я думаю, что приведенное выше достаточно просто, но на практике у меня не было всех методов executeStepN() и часто устанавливался код, содержащийся в соответствующем предложении switch.
Запуск последовательности может выглядеть так:
BitSet26 b (0); // clear all bits
int retVal = tRecurse(b, 'A'); // launch the sequence,
// starting with step 'A'
executeThisFunctionInAnyCase();
Выполняет рекурсию через последовательность без цепочки if. Когда шаг возвращает false, рекурсия завершается. Уникальный retVal (код ошибки) может быть легко передан в конце tRecurse(), но я хотел показать использование битового шаблона для доставки информации о пропуске/сбое.
И рекурсия выглядит так:
int tRecurse(BitSet26& b, int i)
{
int retVal = 0;
bool result = false;
int nxt = executeStep(i, result);
if (result) // if (previous step return true)
{
b[i-'A'] = 1; // map 'A' to 0 index
retVal = tRecurse(b, nxt); // recurse
} // else done, b initialized to 0
return(retVal);
}
Нет задействованных цепей. Хорошо, я признаю это, мне нравится рекурсия.
Вот пример, который запускает рекурсию и выводит результаты:
int foo(void)
{
BitSet26 b;
int retVal = tRecurse(b, 'A'); // launch the sequence, starting with step A
executeThisFunctionInAnyCase();
#ifndef ndbg
{
// development diagnostics
std::cout << "BitSet26: " << b.to_string() << std::endl;
std::string c = "ZYXWVUTSRQPONMLKJIHGFEDCBA";
std::cout << " ";
for (int i=0; i < 26; i++)
{
char kar = c[i];
if(!b[kar-'A']) kar = ' ';
std::cout << kar;
}
std::cout << " : PASS" << std::endl << " ";
for (int i=0; i < 26; i++)
{
char kar = static_cast<char>(tolower(c[i]));
if(b[kar-'A']) kar = ' ';
std::cout << kar;
}
std::cout << " : Failed (or incomplete)" << std::endl;
}
#endif
return(retVal);
}
Пользовательский вывод - это диагностика разработки, поэтому не обращайте внимания на беспорядочный.
Вместо этого подумайте, как ваша обработка ошибок может решить восстановление на основе найденных битовых шаблонов.
Быстрый пример: только 8 шагов выполнения, которые преуспевают, и 9-й, "Z" завершается с ошибкой. Я полагаю, что я должен был использовать только 9 бит в битете... ах.
./dumy104
A
B
C
D
...
I
J
...
R
S
...
Z
executeThisFunctionInAnyCase()
BitSet26: 00000001100000001100001111
SR JI DCBA : PASS
zyxwvut qponmlk hgfe : Failed (Z) (or incomplete)
FINI
ОБНОВЛЕНИЕ 2014 07 30
Забыл упомянуть о ключевой идее:
Вы слышали о том, как использовать петлю в качестве метода оптимизации?
Здесь я использовал рекурсию, чтобы перевернуть цепочку if-then в цикл. И, конечно, рекурсия - это не единственный способ написать цикл.
while(executeStepA() && executeStepB() && executeStepC() && 0);
executeThisFunctionInAnyCase();
executeThisFunctionInAnyCase() должен выполняться в любом случае, даже если другие функции не завершены.
Оператор while:
while(executeStepA() && executeStepB() && executeStepC() && 0)
выполнит все функции, а не будет зацикливаться на как на своеобразное ложное утверждение. Это также можно сделать, чтобы повторить попытку в определенное время, прежде чем уйти.
-
0Теперь это умно.
-
0Где я работаю, «умный» - это оскорбление, только на один шаг менее серьезный, чем «хрупкий» или «хрупкий». Я согласен, этот код "умный".
Учитывая функцию:
string trySomething ()
{
if (condition_1)
{
do_1();
..
if (condition_k)
{
do_K();
return doSomething();
}
else
{
return "Error k";
}
..
}
else
{
return "Error 1";
}
}
Мы можем избавиться от синтаксического вложения, изменив процесс проверки:
string trySomething ()
{
if (!condition_1)
{
return "Error 1";
}
do_1();
..
if (!condition_k)
{
return "Error k";
}
do_K();
return doSomething ();
}
-
0-1, есть комментарии?
-
0Возможно, потому что это почти дубликат ответа, который говорит, что «это стрелка».
не делать. Иногда вам нужна сложность. Фокус в том, как вы это делаете. Наличие "того, что вы делаете, когда условие существует", может занимать какую-то определенную комнату, делая дерево выражений if больше, чем оно есть на самом деле. Поэтому вместо того, чтобы делать что-либо, если условие задано, просто установите переменную в определенное значение для этого случая (перечисление или число, например 10,014). После дерева if затем укажите оператор case и для этого конкретного значения, сделайте то, что вы было бы сделано в дереве if. Это облегчит дерево. если x1 если x2 если x3 Переменная1 = 100016; ENDIF ENDIF конец, если дело переменная = 100016 делаете дело 100016 вещи...
Как просто перемещать условный материал в другое, как в:
if (!(conditionA = executeStepA()){}
else if (!(conditionB = executeStepB()){}
else if (!(conditionC = executeStepC()){}
else if (!(conditionD = executeStepD()){}
Это устраняет проблему с отступом.
-
0Это просто не отступ, а "решение" очевидной проблемы сложности.
-
2И это ужасно трудно читать - цель очень неясна.
Условия могут быть упрощены, если условия перемещаются под отдельными шагами, здесь псевдо-код С#,
идея состоит в том, чтобы использовать хореографию вместо центральной оркестровки.
void Main()
{
Request request = new Request();
Response response = null;
// enlist all the processors
var processors = new List<IProcessor>() {new StepA() };
var factory = new ProcessorFactory(processors);
// execute as a choreography rather as a central orchestration.
var processor = factory.Get(request, response);
while (processor != null)
{
processor.Handle(request, out response);
processor = factory.Get(request, response);
}
// final result...
//response
}
public class Request
{
}
public class Response
{
}
public interface IProcessor
{
bool CanProcess(Request request, Response response);
bool Handle(Request request, out Response response);
}
public interface IProcessorFactory
{
IProcessor Get(Request request, Response response);
}
public class ProcessorFactory : IProcessorFactory
{
private readonly IEnumerable<IProcessor> processors;
public ProcessorFactory(IEnumerable<IProcessor> processors)
{
this.processors = processors;
}
public IProcessor Get(Request request, Response response)
{
// this is an iterator
var matchingProcessors = processors.Where(x => x.CanProcess(request, response)).ToArray();
if (!matchingProcessors.Any())
{
return null;
}
return matchingProcessors[0];
}
}
// Individual request processors, you will have many of these...
public class StepA: IProcessor
{
public bool CanProcess(Request request, Response response)
{
// Validate wether this can be processed -- if condition here
return false;
}
public bool Handle(Request request, out Response response)
{
response = null;
return false;
}
}
-
0В чем причина нег? ответ неверный или полностью отличается от исходного вопроса? или кому-то просто не нравится?
По моему мнению, указатели на функции - лучший способ пройти через это.
Этот подход был упомянут раньше, но я хотел бы еще глубже проникнуть в плюсы использования такого подхода в отношении типа кода со стрелкой.
По моему опыту, подобные цепочки происходят в части инициализации определенного действия программы. Программа должна быть уверена, что перед началом попытки все будет персик.
Часто во многих функциях do stuff некоторые вещи могут быть выделены или право собственности может быть изменено. Если вы потерпите неудачу, вы захотите обратить вспять процесс.
Скажем, у вас есть следующие 3 функции:
bool loadResources()
{
return attemptToLoadResources();
}
bool getGlobalMutex()
{
return attemptToGetGlobalMutex();
}
bool startInfernalMachine()
{
return attemptToStartInfernalMachine();
}
Прототипом для всех функций будет:
typdef bool (*initializerFunc)(void);
Итак, как упоминалось выше, вы добавите в вектор, используя push_back указатели, и просто запустите их в порядке. Однако, если ваша программа выходит из строя в startInfernalMachine, вам нужно будет вручную вернуть мьютексы и выгрузить ресурсы. Если вы сделаете это в своей функции RunAllways, у вас будет время баада.
Но подождите! функторы довольно удивительны (иногда), и вы можете просто изменить прототип следующим образом:
typdef bool (*initializerFunc)(bool);
Почему? Ну, теперь новые функции будут выглядеть примерно так:
bool loadResources(bool bLoad)
{
if (bLoad)
return attemptToLoadResources();
else
return attemptToUnloadResources();
}
bool getGlobalMutex(bool bGet)
{
if (bGet)
return attemptToGetGlobalMutex();
else
return releaseGlobalMutex();
}
...
Итак, теперь весь код будет выглядеть примерно так:
vector<initializerFunc> funcs;
funcs.push_back(&loadResources);
funcs.push_back(&getGlobalMutex);
funcs.push_back(&startInfernalMachine);
// yeah, i know, i don't use iterators
int lastIdx;
for (int i=0;i<funcs.size();i++)
{
if (funcs[i](true))
lastIdx=i;
else
break;
}
// time to check if everything is peachy
if (lastIdx!=funcs.size()-1)
{
// sad face, undo
for (int i=lastIdx;i>=0;i++)
funcs[i](false);
}
Итак, это определенно шаг вперед, чтобы автозапустить ваш проект и пройти этот этап. Однако реализация немного неудобна, так как вам придется использовать этот механизм pushback снова и снова. Если у вас есть только одно такое место, скажите, что все в порядке, но если у вас есть 10 мест, с oscilating количество функций... не так весело.
К счастью, есть еще один механизм, который позволит вам сделать еще лучшую абстракцию: вариативные функции. В конце концов, существует множество функций, которые нужно тщательно изучить. Вариадическая функция будет выглядеть примерно так:
bool variadicInitialization(int nFuncs,...)
{
bool rez;
int lastIdx;
initializerFunccur;
vector<initializerFunc> reverse;
va_list vl;
va_start(vl,nFuncs);
for (int i=0;i<nFuncs;i++)
{
cur = va_arg(vl,initializerFunc);
reverse.push_back(cur);
rez= cur(true);
if (rez)
lastIdx=i;
if (!rez)
break;
}
va_end(vl);
if (!rez)
{
for (int i=lastIdx;i>=0;i--)
{
reverse[i](false);
}
}
return rez;
}
И теперь ваш код будет уменьшен (в любом месте приложения):
bool success = variadicInitialization(&loadResources,&getGlobalMutex,&startInfernalMachine);
doSomethingAllways();
Таким образом, вы можете делать все эти неприятные списки, используя только один вызов функции, и быть уверенным, что когда функция выйдет, у вас не будет никаких остатков от инициализаций.
Ваши товарищи по команде будут очень благодарны за создание 100 строк кода всего за 1.
НО ЖДИТЕ! Там еще! Одна из главных черт кода стрелочного типа заключается в том, что вам нужно иметь конкретный заказ! И этот конкретный порядок должен быть одинаковым во всем приложении (правило многопоточности тупика № 1: всегда принимать мьютексы в одном и том же порядке по всему приложению) Что, если один из новичков просто выполняет функции в произвольном порядке? Хуже того, что, если вас попросят разоблачить это на Java или С#? (да, кросс-платформа - это боль)
К счастью, для этого есть подход. В пунктах пули это то, что я хотел бы предложить:
-
создать перечисление, начиная с первого ресурса до последнего
-
определить пару, которая берет значение из перечисления и связывает его с указателем функции
-
поместите эти пары в вектор (я знаю, я просто определил использование карты:), но я всегда иду вектор для небольших чисел)
-
измените переменный макрос, указав указатели на целые числа (которые легко отображаются в java или С#;)))
-
в вариационной функции, сортируйте эти целые числа
-
при запуске запустите функцию, назначенную этому целому.
В конце ваш код обеспечит следующее:
-
одна строка кода для инициализации, независимо от того, сколько вещей должно быть в порядке
-
выполнение порядка вызова: вы не можете вызвать startInfernalMachine перед loadResources, если вы (архитектор) не решили разрешить это
-
полная очистка, если что-то не удается на этом пути (учитывая, что вы сделали деинициализацию должным образом)
-
изменение порядка инициализации во всем приложении означает только изменение порядка в перечислении
Что касается вашего текущего примера кода, по существу вопрос № 2,
[...block of code...]
bool conditionA = executeStepA();
if (conditionA){
[...block of code...]
bool conditionB = executeStepB();
if (conditionB){
[...block of code...]
bool conditionC = executeStepC();
if (conditionC){
...other checks again...
}
}
}
executeThisFunctionInAnyCase();
За исключением сохранения результатов функции в переменных, это типичный код C.
Если логическая функция выводит сигнал из строя, тогда С++ путь будет использовать исключения и кодировать это как
struct Finals{ ~Finals() { executeThisFunctionInAnyCase(); } };
Finals finals;
// [...block of code...]
executeStepA();
// [...block of code...]
executeStepB();
// [...block of code...]
executeStepC();
//...other checks again...
Однако детали могут сильно варьироваться в зависимости от реальной проблемы.
Когда мне нужны такие общие окончательные действия, вместо определения пользовательского struct на месте, я часто использую общий класс scope guard. Защитные маски были изобретенные Петром Маргинеем для С++ 98, а затем использовали временный трюк расширения срока службы. В С++ 11 общий класс защиты объектов может быть реализован тривиально на основе кода клиента, снабжающего лямбда-выражением.
В конце вопроса вы предлагаете хороший способ, а именно: с помощью инструкции break:
for( ;; ) // As a block one can 'break' out of.
{
// [...block of code...]
if( !executeStepA() ) { break; }
// [...block of code...]
if( !executeStepB() ) { break; }
// [...block of code...]
if( !executeStepC() ) { break; }
//...other checks again...
break;
}
executeThisFunctionInAnyCase();
В качестве альтернативы для C реорганизуйте код в блоке как отдельную функцию и используйте return вместо break. Это более ясное и более общее, поскольку оно поддерживает вложенные циклы или переключатели. Однако вы спросили о break.
По сравнению с подходом на основе исключений на основе С++, это зависит от программиста, помнящего о проверке каждого результата функции, и делает правильную вещь, оба из которых автоматизированы на С++.
-
0В случае, если кому-то интересно,
for(;;)используется, несмотря на указание общего цикла, поскольку Visual C ++ имеет привычку выдавать глупые предупреждения для константных выражений, используемых в качестве условий. -
18-1. Это гораздо страшнее, чем формулировка Гото. Он имеет тот же эффект, что и формулировка goto, с одним большим отличием: формулировка goto является честной. Это нечестно. Там нет зацикливания. Цикл существует по единственной причине избегания перехода.
Ещё вопросы
- 1SPS / PPS VUI не используется Android MediaCodec NDK
- 2Игнорирование видимого устройства GPU с вычислительной возможностью 3.0. Минимальная требуемая способность Cuda составляет 3,5
- 0Мусор в результате загрузки (Indy, Delphi 2009)
- 1Как выровнять два текста по горизонтали с фоном, используя любой макет в Android?
- 1Параметры TextView в LinearLayout не работают программно
- 1Как Eclipse запускает карту, сокращая работу?
- 0Результаты поиска Google Search на странице - HTML
- 0Как передать данные о значении в ссылку на действие
- 0Данные не вставлены в таблицу MySQL (MariaDB)
- 1Регулярное выражение для сопоставления целых чисел
- 0prettyCheckable останавливает проверку jquery от работы в флажках
- 0код внутри #ifdef включен во время выполнения или во время самой компиляции?
- 0Qt 5.3 QTreeView кликабельные данные заголовка
- 1Mastercard Обходной путь для сторонних cookie-файлов отключенных пользователей
- 0C ++ инициализирует неизвестный размер 2DimArray в конструкторе
- 0Как перемещаться по пунктам / деталям в списке JqeuryMobile
- 1Сортировка по сумме значений в списке для словаря Python
- 0Открывать новую страницу, когда пользователь нажимает на любой элемент из ion-item
- 0Может ли PHP использовать переменные до их определения?
- 0показать отслеживаемый объект в видео с помощью OpenGL
- 0Начальная точка Директивы угловой группировки
- 0Цвет чередующихся строк для каждого нового элемента dom, добавленного в angularjs
- 1После перевода реселлервью перестает слушать сенсорные события
- 1Правка текста переходит к следующим правкам текста после достижения максимальной длины текста правки.
- 1Получение значения на основе идентификатора из Enums в Javascript
- 0Как заставить оператор switch вернуться в меню?
- 1Java не может получить доступ к защищенной переменной во внутреннем классе
- 1Чистая Java-альтернатива GIMP с * live * плагином?
- 0Извлечь из таблицы на основе значения префикса
- 0Протрите все таблицы в схеме - sequelize nodejs
- 0Ошибки включения Android NDK с помощью cURL
- 1GoogleSignInClient.signOut вылетает с: «Вызовите connect () и дождитесь вызова onConnected ()»
- 0Как получить выходные данные консоли в командной строке?
- 1Android XML динамически устанавливает высоту полей
- 0Эффективный способ перенаправления страниц с использованием угловых JS
- 0получить все узлы из многоуровневого хэша в Perl
- 1Произведите рандомизацию начальной точки воспроизведения в html5 Audio on toggle
- 1Android NSD: почему тип сервиса не совпадает
- 1Асинхронная операция findOne () внутри цикла forEach
- 1Связывание кода начальной загрузки с файлом .aspx.cs
- 1Как расширить несколько миксинов в одном элементе Polymer?
- 1Добавьте вывод в раздел «СБОЙ» теста, не захватывая стандартный вывод
- 1На Vis.js, шкала времени, обновление отображения данных об изменениях
- 0SQL-запрос, дающий противоречивые результаты
- 1Как изменить статус релиза продукта на альфа / бета приложение для Android в Google Play
- 0Выберите Distinct, добавляя кортежи вместе в SQL
- 0Перенаправление с .htaccess и его паролем защищены
- 0Упорядочение двух таблиц по одной дате с PHP, MYSQL (PDO)
- 1Передать данные в pug с помощью pug-html-loader (не может прочитать свойство undefined)
- 0jQuery inArray не работает

ifзаявление:if( execA() && execB() && ... )