Обработка изображений: Улучшение алгоритма для распознавания Coca-Cola Can
Одним из самых интересных проектов, над которыми я работал в последние пару лет, был проект обработка изображений. Цель состояла в том, чтобы разработать систему, чтобы иметь возможность распознавать "сильные" банки Coca-Cola (обратите внимание, что я подчеркиваю слово "банки", вы увидите, почему через минуту). Вы можете увидеть образец ниже, с возможностью распознавания в зеленом прямоугольнике с масштабом и вращением.

Некоторые ограничения для проекта:
- Фон может быть очень шумным.
- Банк может иметь любой масштаб или поворот или даже ориентацию (в разумных пределах).
- Изображение может иметь некоторую степень нечеткости (контуры могут быть не совсем прямыми).
- В изображении могут быть бутылки Coca-Cola, и алгоритм должен только обнаруживать банку!
- Яркость изображения может сильно различаться (поэтому вы не можете "слишком много" полагаться на распознавание цвета).
- Ящик может быть частично скрыт по бокам или посередине и, возможно, частично скрыт за бутылкой.
- На изображении вообще ничего не может быть, и в этом случае вам нечего было найти и написать сообщение об этом.
Итак, у вас могут получиться такие сложные вещи (которые в этом случае полностью завершили мой алгоритм):

Я сделал этот проект некоторое время назад, и мне было очень весело, и у меня была достойная реализация. Вот некоторые подробности о моей реализации:
Язык: выполнен на С++ с использованием библиотеки OpenCV.
Предварительная обработка. Для предварительной обработки изображения, то есть преобразования изображения в более необработанную форму для предоставления алгоритма, я использовал 2 метода:
- Изменение цветового домена от RGB до HSV и фильтрация на основе "красного" оттенка, насыщение выше определенного порога, чтобы избежать оранжевого цвета и фильтрацию низкого значения, чтобы избежать темных тонов. Конечным результатом было двоичное черно-белое изображение, в котором все белые пиксели будут представлять пиксели, соответствующие этому пороговому значению. Очевидно, в изображении все еще много дерьма, но это уменьшает количество измерений, с которыми вы должны работать.

- Фильтрация шума с использованием медианной фильтрации (с учетом среднего значения пикселей всех соседей и замены пикселя на это значение) для уменьшения шума.
- Используя Canny Edge Filter > , чтобы получить контуры всех элементов после двух шагов прецедента.

Алгоритм. Сам алгоритм, который я выбрал для этой задачи, был взят из этой удивительной книги по извлечению функции и вызвал Обобщенное преобразование Hough (довольно отличается от обычного преобразования Hough). В основном он говорит несколько вещей:
- Вы можете описать объект в пространстве, не зная его аналитического уравнения (что здесь и есть).
- Он устойчив к деформациям изображения, таким как масштабирование и вращение, поскольку он будет в основном проверять ваше изображение для каждой комбинации масштабного коэффициента и коэффициента поворота.
- Он использует базовую модель (шаблон), которую алгоритм будет "учиться".
- Каждый пиксель, оставшийся на контурном изображении, будет голосовать за другой пиксель, который предположительно будет центром (в терминах силы тяжести) вашего объекта, основываясь на том, что он узнал из модели.
В конце концов, вы получаете тепловую карту голосов, например, здесь все пиксели контура банки будут голосовать за свой гравитационный центр, поэтому у вас будет много голосов в одном пикселе соответствующий центру, и увидит пик в тепловой карте, как показано ниже:
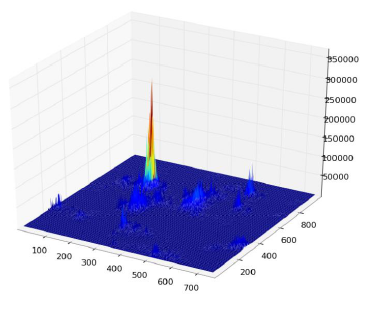
Как только вы это сделаете, простая эвристика на основе порога даст вам местоположение центрального пикселя, из которого вы можете получить масштаб и поворот, а затем нарисуйте свой маленький прямоугольник вокруг него (конечная шкала и коэффициент вращения, очевидно, будут относительно исходного шаблона). Теоретически хотя бы...
Результаты. Теперь, когда этот подход работал в основных случаях, в некоторых областях он был крайне недостаточным:
- очень медленно! Я недостаточно подчеркиваю это. Для обработки 30 тестовых изображений потребовался почти полный день, потому что у меня был очень высокий коэффициент масштабирования для вращения и перевода, поскольку некоторые из банок были очень маленькими.
- Это было полностью потеряно, когда бутылки были на изображении, и почему-то почти всегда находили бутылку вместо банки (возможно, потому, что бутылки были больше, таким образом, было больше пикселей, тем самым было больше голосов).
- Нечеткие изображения тоже не были хорошими, поскольку голоса попадали в пиксель в случайных местах вокруг центра, что заканчивалось очень шумной тепловой картой.
- В-дисперсии в переводе и ротации было достигнуто, но не в ориентации, а это означало, что не может быть распознана возможность, которая не была непосредственно связана с объективом камеры.
Можете ли вы помочь мне улучшить свой определенный алгоритм, используя исключительно функции OpenCV, чтобы решить упомянутые проблемы четыре конкретных?
Я надеюсь, что некоторые люди также узнают что-то из этого, ведь я думаю, что не только люди, которые задают вопросы, должны учиться.:)
-
36Можно было бы сказать, что этот вопрос более уместен на dsp.stackexchange.com или stats.stackexchange.com, и вам, безусловно, следует рассмотреть возможность повторного запроса и на этих сайтах.ely
-
45Первое, что нужно сделать здесь, это проанализировать, почему происходят разные случаи сбоев. Например, выделите примеры мест, где выигрывают бутылки, где изображения нечеткие и т. Д., И проведите некоторый статистический анализ, чтобы узнать разницу между их представлениями Хафа и теми, которые вы хотели бы обнаружить. Некоторые отличные места, чтобы узнать об альтернативных подходах здесь и здесьely
26 ответов
Альтернативный подход состоял бы в том, чтобы извлечь функции (ключевые точки), используя масштабно-инвариантное преобразование функции (SIFT) или Ускоренные надежные функции (SURF).
Он реализован в OpenCV 2.3.1.
Вы можете найти хороший пример кода, используя функции Features2D + Homography, чтобы найти известный объект
Оба алгоритма инвариантны к масштабированию и вращению. Поскольку они работают с функциями, вы также можете обрабатывать occlusion (если видны достаточно ключевых точек).
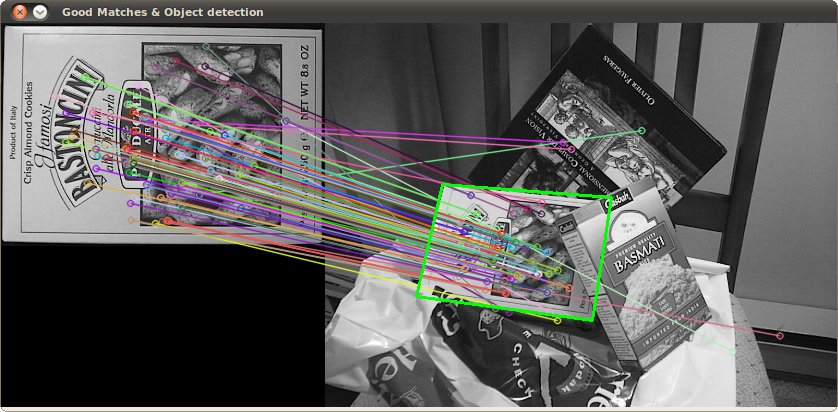
Источник изображения: пример учебника
Для SIFT обработка занимает несколько сотен мс, SURF бит быстрее, но не подходит для приложений реального времени. ORB использует FAST, который слабее относительно инвариантности вращения.
Оригинальные документы
-
2Звучит интересно. Этот алгоритм также обрабатывает неизменность ориентации (то есть, если банка не направлена непосредственно на объектив камеры)? Это один из главных моментов, когда мой алгоритм не удался.
-
0@linker, вы можете сделать несколько снимков 3D-объекта, вращая (вокруг объектов по оси Y). Поскольку изображения могут выглядеть по-разному с передней и задней стороны, вы попытаетесь найти наиболее близкое совпадение и оценить его ориентацию в тех случаях, когда логотип отсутствует. не полностью виден
Чтобы ускорить процесс, я бы воспользовался тем, что вас не просят найти произвольный образ/объект, но, в частности, логотип Coca-Cola. Это важно, потому что этот логотип очень свойственен, и он должен иметь характерную, масштабно-инвариантную сигнатуру в частотной области, особенно в красном канале RGB. Другими словами, чередующийся рисунок красно-белого-красного цвета, встречаемый горизонтальной линией развертки (обученный на горизонтально выровненном логотипе), будет иметь отличительный "ритм", проходящий через центральную ось логотипа. Этот ритм будет "ускоряться" или "замедляться" в разных масштабах и ориентациях, но будет оставаться пропорционально эквивалентным. Вы могли бы определить/определить несколько десятков таких строк сканирования, как по горизонтали, так и по вертикали через логотип и еще несколько по диагонали, по шаблону звездообразования. Назовите эти "строки сканирования подписи".

Поиск этой сигнатуры в целевом изображении - это простой вопрос сканирования изображения в горизонтальных полосах. Ищите высокочастотную в красном канале (указывающую переход от красной области к белой), и после того, как она найдена, посмотрите, следует ли за ней один из частотных ритмов, определенных на тренировке. Как только совпадение будет найдено, вы мгновенно узнаете ориентацию и местоположение линии сканирования в логотипе (если вы будете отслеживать эти вещи во время обучения), поэтому определение границ логотипа оттуда тривиально.
Я был бы удивлен, если бы это был не линейно-эффективный алгоритм, а почти так. Очевидно, это не касается дискриминации на бутылочной бутылке, но, по крайней мере, у вас будут свои логотипы.
(Обновление: для распознавания бутылки я хотел бы найти кокс (коричневую жидкость), прилегающий к логотипу, то есть внутри бутылки. Или, в случае пустой бутылки, я бы искал кепку, которая будет всегда имеют одинаковую основную форму, размер и расстояние от логотипа и обычно будут белого или красного цвета. Найдите сплошную цветовую форму, в которой должна быть крышка, относительно логотипа. Конечно, без надежной защиты, но ваша цель здесь должно быть, чтобы быстро найти быстрые.)
(Прошло несколько лет с момента обработки изображений, поэтому я придерживался этого предложения на высоком уровне и концептуально. Я думаю, что это может слегка приблизиться к тому, как может работать человеческий глаз - или, по крайней мере, как мой мозг!)
-
19Это отличное предложение, мне особенно нравится тот факт, что этот алгоритм должен быть довольно быстрым, даже если он, вероятно, будет содержать много ложных негативов. Одна из моих скрытых целей - использовать это обнаружение в режиме реального времени для робототехники, так что это может быть хорошим компромиссом!
-
37Да, часто забывают (в области, характеризующейся точностью), что алгоритмы аппроксимации необходимы для большинства задач моделирования в реальном времени. (Я основал свой тезис на этой концепции.) Сохраните ваши алгоритмы, требующие много времени, для ограниченных регионов (чтобы исключить ложные срабатывания). И помните: в робототехнике вы обычно не ограничены одним изображением. Предполагая, что мобильный робот, быстрый алгоритм может искать десятки изображений с разных ракурсов за меньшее время, чем сложные алгоритмы тратят на одно, значительно уменьшая количество ложных негативов.
Интересная проблема: когда я взглянул на изображение бутылки, я подумал, что это тоже может быть. Но, как человек, я сделал, чтобы сказать разницу, что я тогда заметил, что это тоже бутылка...
Итак, чтобы разделить банки и бутылки, как насчет просто сканирования бутылок в первую очередь? Если вы его найдете, замаскируйте ярлык, прежде чем искать банки.
Не слишком сложно реализовать, если вы уже делаете банки. Реальный недостаток - это удвоение времени обработки. (Но, думая заранее о реальных приложениях, вы все равно захотите делать бутылки; -)
-
5Да, я тоже об этом думал, но у меня не было много времени, чтобы сделать это. Как бы вы узнали бутылку, поскольку ее основная часть будет выглядеть как чешуйчатая банка? Я тоже думал о том, чтобы найти красную пробку и посмотреть, совпадает ли она с бутылочным центром, но это не очень надежно.
-
38Если параллельно «кока-коле» есть красная крышка (или кольцо), то это, скорее всего, бутылка.
Разве не сложно даже людям различать бутылку и банку во втором изображении (при условии, что прозрачная область бутылки скрыта)?
Они почти одинаковы, за исключением очень маленькой области (т.е. Ширина в верхней части банки немного маленькая, в то время как обертка бутылки имеет одинаковую ширину, но незначительное изменение справа?)
Первое, что пришло мне в голову, - проверить красную бутылку. Но это все еще проблема, если нет вершины для бутылки или если она частично скрыта (как упоминалось выше).
Во-вторых, я думал о прозрачности бутылки. В OpenCV есть несколько работ по поиску прозрачных объектов в изображении. Проверьте приведенные ниже ссылки.
Особенно посмотрите на это, чтобы увидеть, как точно они обнаруживают стекло:
См. Их результат внедрения:

Они говорят, что это реализация статьи "Геодезическая активная контурная основа для поиска стекла" К. МакГенри и Дж. Понсе, CVPR 2006.
Это может быть полезно в вашем случае немного, но проблема снова возникает, если бутылка заполнена.
Поэтому я думаю, что здесь вы можете сначала искать прозрачное тело бутылок или красную область, связанную с двумя прозрачными объектами в боковом направлении, которая, очевидно, является бутылкой. (При работе в идеале изображение выглядит следующим образом.)

Теперь вы можете удалить желтую область, то есть метку бутылки и запустить свой алгоритм, чтобы найти банку.
Во всяком случае, это решение также имеет разные проблемы, как в других решениях.
- Он работает, только если ваша бутылка пуста. В этом случае вам придется искать красную область между двумя черными цветами (если жидкость Coca Cola черная).
- Другая проблема, если прозрачная часть покрыта.
Но, в любом случае, если на фотографиях нет упомянутых выше проблем, похоже, это лучше.
-
0+1 Я думал об этом и был на моем пути для реализации этого подхода. Тем не менее, @linker должен поделиться своим набором изображений, чтобы мы могли попытаться сделать более образованные догадки.
-
0да .. я тоже думаю, что было бы хорошо, если бы было больше изображений.
Мне действительно нравится Darren Cook's и stacker ответы на эту проблему. Я был посреди того, чтобы бросить мои мысли в комментарии к ним, но я считаю, что мой подход слишком ответиен, чтобы не уйти отсюда.
Вкратце, вы определили алгоритм, чтобы определить, что логотип Coca-Cola присутствует в определенном месте в космосе. Теперь вы пытаетесь определить для произвольных ориентаций и произвольных коэффициентов масштабирования эвристику, подходящую для различения банок Coca-Cola из других объектов, включая: бутылки, рекламные щиты, рекламные объявления и атрибуты Coca-Cola, связанные с этим знаковым логотипом. Вы не вызывали многие из этих дополнительных случаев в своем заявлении о проблеме, но я чувствую, что они жизненно важны для успеха вашего алгоритма.
Секрет здесь заключается в определении того, какие визуальные функции могут содержать или, через отрицательное пространство, какие функции присутствуют для других продуктов Coke, которые не присутствуют в банках. С этой целью текущий верхний ответ набросает базовый подход для выбора "can" тогда и только тогда, когда "бутылка" не идентифицируется ни наличием бутылки колпачок, жидкость или другие подобные визуальные эвристики.
Проблема в том, что это ломается. Например, бутылка могла быть пуста и отсутствовала наличие колпачка, что приводило к ложному положительному результату. Или это может быть частичная бутылка с дополнительными функциями, искаженными, снова приводя к ложному обнаружению. Излишне говорить, что это не изящно и не эффективно для наших целей.
С этой целью наиболее правильные критерии выбора для банок выглядят следующим образом:
- Является ли форма силуэта объекта, как вы набросали в своем вопросе, правильно? Если это так, +1.
- Если мы предполагаем наличие естественного или искусственного света, мы обнаруживаем хром-план для бутылки, который означает, что это сделано из алюминия? Если это так, +1.
- Определим ли мы, что зеркальные свойства объекта относительно наших источников света (иллюстративная видеосвязь на обнаружение источника света)? Если это так, +1.
- Можем ли мы определить любые другие свойства объекта, которые идентифицируют его как банку, включая, но не ограничиваясь этим, топологическое искажение логотипа, ориентацию объекта, сопоставление объекта (например, на плоскую поверхность, подобную таблице или в контексте других банок), и наличие выталкивающей вкладки? Если да, то для каждого +1.
Ваша классификация может выглядеть следующим образом:
- Для каждого совпадения кандидатов, если обнаружено присутствие логотипа Coca Cola, нарисуйте серая рамка.
- Для каждого совпадения над +2 нарисуйте красную рамку.
Это визуально подчеркивает пользователю то, что было обнаружено, подчеркивая слабые положительные результаты, которые могут быть правильно обнаружены как искаженные банки.
Обнаружение каждого свойства имеет очень разную временную и пространственную сложность, и для каждого подхода быстрый проход через http://dsp.stackexchange.com более чем разумен для определения наиболее правильный и эффективный алгоритм для ваших целей. Мое намерение здесь состоит в том, чтобы чисто и просто подчеркнуть, что обнаружение, если что-то может быть, путем аннулирования небольшой части пространства обнаружения кандидата, не является самым надежным или эффективным решением этой проблемы, и в идеале вы должны предпринять соответствующие действия соответственно.
И привет, поздравляю публикацию Hacker News! В целом, это довольно потрясающий вопрос, достойный публичности, которую он получил.:)
-
2Это интересный подход, который, по крайней мере, стоит попробовать, мне очень нравятся ваши рассуждения о проблеме
-
0Это своего рода то, о чем я думал: не исключайте конкретные виды ложных срабатываний. Правило в том, что делает колу. Но мне интересно: что ты делаешь со сплющенной банкой? Я имею в виду, если вы наступите на колу, это все равно будет кола. Но он больше не будет иметь такую же форму. Или это проблема AI-Complete?
Глядя на форму
Возьмите гусак в форме красной части банки/бутылки. Обратите внимание на то, как консервная банка слегка сужается на самом верху, а этикетка бутылки - прямо. Вы можете различать эти два, сравнивая ширину красной части по ее длине.
Глядя на основные моменты
Одним из способов различения бутылок и банок является материал. Бутылка изготовлена из пластика, тогда как банда изготовлена из алюминиевого металла. В достаточно хорошо освещенных ситуациях просмотр зеркальности будет одним из способов сказать этикетку с этикеткой на этикетке.
Насколько я могу судить, так это то, как человек скажет разницу между двумя типами этикеток. Если условия освещения плохие, неизбежно будет какая-то неопределенность в том, чтобы различать два в любом случае. В этом случае вы должны были бы обнаружить присутствие прозрачной/полупрозрачной бутылки.
-
0Мне нравится идея, но, похоже, вам нужны действительно хорошие условия освещения. На примере изображения, где есть и банка, и бутылка, например, это довольно сложно различить.
-
0В вашем примере, обратите внимание, что зеркальность пластиковой этикетки гораздо более размыта, чем очень яркие пятна на банке? Вот как ты можешь сказать.
Пожалуйста, взгляните на Zdenek Kalal Отслеживание хищников. Это требует некоторой подготовки, но она может активно изучать, как отслеживаемый объект смотрит на разные ориентации и масштабы и делает это в реальном времени!
Исходный код доступен на его сайте. Он находится в MATLAB, но, возможно, есть реализация Java, уже сделанная членом сообщества. Я успешно выполнил повторную реализацию трекерной части TLD в С#. Если я правильно помню, TLD использует Ferns в качестве детектора ключевой точки. Вместо этого я использую SURF или SIFT (уже предложенный @stacker), чтобы повторно захватить объект, если он был потерян трекером. Обратная связь с трекером позволяет легко создавать со временем динамический список шаблонов sift/surf, которые со временем позволяют повторно захватить объект с очень высокой точностью.
Если вы заинтересованы в моей реализации С# трекера, не стесняйтесь спрашивать.
-
0Спасибо за ссылку, которая выглядит интересно. Что касается обучения, каков размер тренировочного набора, который был бы разумным для достижения разумных результатов? Если у вас есть реализация, даже в C #, это было бы очень полезно!
-
0Исследуя TLD, я обнаружил, что другой пользователь ищет реализацию C # - есть ли причина не размещать вашу работу на Github? stackoverflow.com/questions/29436719/...
Если вы не ограничены только камерой, которая не была в одном из ваших ограничений, возможно, вы можете перейти к использованию датчика дальности, такого как Xbox Kinect. С помощью этого вы можете выполнить согласованную сегментацию изображения на основе глубины и цвета. Это позволяет быстрее разделять объекты на изображении. Затем вы можете использовать сопоставление ICP или аналогичные методы, чтобы даже соответствовать форме, а не просто ее контуру или цвет, и учитывая, что она является цилиндрической, это может быть допустимым вариантом для любой ориентации, если у вас есть предыдущее 3D-сканирование цели. Эти методы часто бывают довольно быстрыми, особенно когда они используются для такой конкретной цели, которая должна решить вашу проблему скорости.
Также я мог бы предложить, не обязательно для точности или скорости, но для удовольствия вы могли бы использовать обученную нейронную сеть на своем сегментированном изображении с оттенком, чтобы идентифицировать форму банки. Они очень быстрые и часто могут быть точными до 80/90%. Тренировка будет немного долгим процессом, хотя вам придется вручную идентифицировать банку в каждом изображении.
-
3На самом деле я не объяснил это в посте, но для этого задания мне дали набор из примерно 30 изображений, и мне пришлось создать алгоритм, который бы соответствовал всем им в различных ситуациях, как описано. Конечно, некоторые изображения были проведены для проверки алгоритма в конце. Но мне нравится идея датчиков Kinect, и я хотел бы прочитать больше на эту тему!
-
0Каков примерно размер тренировочного набора с нейронной сетью для получения удовлетворительных результатов? Что хорошо в этом методе, так это то, что мне нужен только один шаблон, чтобы соответствовать почти всем.
Я бы обнаружил красные прямоугольники: RGB → HSV, фильтр red → двоичное изображение, закрыть (расширение затем размывается, называемое imclose в matlab)
Затем просмотрите прямоугольники от самых больших до самых маленьких. Прямоугольники, которые имеют меньшие прямоугольники в известном положении/масштабе, могут быть удалены (при условии, что пропорции бутылки постоянны, меньший прямоугольник будет крышкой для бутылок).
Это оставит вас с красными прямоугольниками, тогда вам нужно каким-то образом обнаружить логотипы, чтобы узнать, красные ли они прямоугольники или кокс. Как OCR, но с известным логотипом?
-
2Как это обсуждалось на DSP за короткое время, когда он был перемещен, некоторые бутылки могут не иметь пробок;) или пробка может быть частично скрыта.
Это может быть очень наивная идея (или может вообще не работать), но размеры всех кокса могут быть исправлены. Так может быть, если одно и то же изображение содержит как банку, так и бутылку, тогда вы можете рассказать их отдельно по соображениям размера (бутылки будут больше). Теперь из-за недостающей глубины (т.е. 3D-сопоставление для двумерного отображения) возможно, что бутылка может казаться сжатой и не существует разницы в размерах. Вы можете восстановить некоторую информацию о глубине с помощью стереоизображения, а затем восстановить исходный размер.
-
3На самом деле нет: нет никаких ограничений по размеру или ориентации (или ориентации, но я на самом деле не справился с этим), поэтому вы можете иметь бутылку очень далеко на заднем плане, и банку на переднем плане, и банка будет намного больше чем бутылка.
-
0Я также проверил, что отношение ширины к высоте очень похоже на бутылку и может, так что это тоже не вариант.
Хм, я на самом деле думаю, что нахожусь на чем-то (это похоже на самый интересный вопрос, когда-либо), поэтому было бы позором не продолжать пытаться найти "идеальный" ответ, хотя приемлемый был найден)...
Как только вы найдете логотип, ваши проблемы будут выполнены наполовину. Тогда вам нужно только выяснить различия между тем, что вокруг логотип. Кроме того, мы хотим сделать как можно меньше. Я думаю, что это на самом деле эта легкая часть...
Что вокруг логотипа? Для банки можно увидеть металл, который, несмотря на эффекты освещения, не меняет своего основного цвета. Пока мы знаем угол метки, мы можем сказать, что прямо над ним, поэтому мы смотрим на разницу между ними:

Здесь, что выше и ниже логотипа полностью темное, непротиворечивое по цвету. Относительно легко в этом отношении.

Здесь, что выше и ниже, является светлым, но все же последовательным по цвету. Это все-серебро, и все-серебристый металл на самом деле кажется довольно редкими, а также серебряными цветами в целом. Кроме того, он в тонкой скользкой и достаточно близко к красному, который уже был идентифицирован, чтобы вы могли проследить его форму на всю длину, чтобы рассчитать процент от того, что можно считать металлическим кольцом банки. На самом деле, вам нужна лишь небольшая часть того, что можно найти в любом месте, чтобы сказать, что это часть его, но вам все равно нужно найти баланс, который гарантирует ему не просто пустую бутылку с чем-то металлическим за ней.

И, наконец, сложный. Но не так сложно, как только мы пойдем только по тому, что мы можем видеть непосредственно над (и ниже) красной оберткой. Его прозрачность, что означает, что она покажет все, что стоит за ней. Это хорошо, потому что вещи, которые стоят за ним, вряд ли будут такими же последовательными по цвету, как серебряный круговой металл банки. За этим может быть много разных вещей, которые говорят нам, что это пустая (или наполненная прозрачной жидкостью) бутылка или постоянный цвет, который может означать, что он заполнен жидкостью или что бутылка просто перед сплошной цвет. Мы работаем с тем, что ближе всего к вершине и дну, и шансы на правильные цвета в правильном месте относительно тонкие. Мы знаем, что это бутылка, потому что у нее нет такого ключевого визуального элемента банки, который относительно упрощен по сравнению с тем, что может быть за бутылкой.
(последний из них был лучшим, что я мог найти в пустой большой бутылке с кокой-колой - интересно, что кепка и кольцо желтые, что указывает на то, что покраснение шапки, вероятно, не следует полагаться)
В редких случаях, когда подобный оттенок серебра стоит за бутылкой, даже после абстракции пластика, или бутылка каким-то образом заполнена тем же оттенком серебристой жидкости, мы можем отбросить то, что мы можем приблизительно оценить как форма серебра - как я уже упоминал, круглая и следует за формой банки. Но даже если мне не хватает знаний в обработке изображений, это звучит медленно. Еще лучше, почему бы не вывести это за однократную проверку сторон логотипа, чтобы убедиться, что там нет ничего такого же серебряного цвета? Ах, но что, если там есть такой же оттенок серебра за банкой? Затем мы действительно должны уделять больше внимания формам, снова глядя на верхнюю и нижнюю часть банки.
В зависимости от того, насколько безупречно это все должно быть, это может быть очень медленным, но я полагаю, что моя основная концепция - сначала проверить самые простые и самые близкие вещи. Идите по цветовым различиям вокруг уже подобранной формы (которая, кажется, самая тривиальная часть этого в любом случае), прежде чем приступить к разработке формы других элементов. Для его перечня:
- Найдите основную привлекательность (красный фон логотипа и, возможно, логотип для ориентации, хотя в случае отказа банки можно сосредоточиться только на красном).
- Проверьте форму и ориентацию, еще раз через очень своеобразную покраснение.
- Проверьте цвета вокруг формы (так как это быстро и безболезненно)
- Наконец, при необходимости проверьте форму этих цветов вокруг главной притяжения для правильной округлости.
В случае, если вы не можете этого сделать, это, вероятно, означает, что верхняя и нижняя части банки покрыты, и единственно возможными вещами, которые человек мог бы использовать для надежного проведения различия между банкой и бутылкой, является окклюзии и отражения банки, что было бы тяжелой биткой . Тем не менее, чтобы идти еще дальше, вы можете следить за углом банки/бутылки, чтобы проверить больше признаков, подобных бутылочке, используя полупрозрачные методы сканирования, упомянутые в других ответах.
Интересные дополнительные ночные кошмары могут включать в себя удобную сидячую за бутылкой на таком расстоянии, что металл его просто так выглядит, как показано выше и ниже метки, который все равно будет терпеть неудачу, пока вы сканируете по всей длине красной этикетки - на самом деле это больше проблема, потому что вы не обнаруживаете банку, где могли бы быть, а не считаете, что вы на самом деле обнаруживаете бутылку, в том числе банку, случайно. В этом случае стекло будет наполовину пустым!
Как отказ от ответственности, у меня нет опыта и никогда не думал об обработке изображений за пределами этого вопроса, но это так интересно, что я подумал об этом довольно глубоко, и, прочитав все остальные ответы, я считаю это возможно, самый простой и наиболее эффективный способ сделать это. Лично я просто рад, что мне не нужно думать о программировании этого!
ИЗМЕНИТЬ
 Кроме того, посмотрите на этот рисунок, который я сделал в MS Paint... Это абсолютно ужасно и довольно неполно, но, основываясь только на форме и цветах, вы можете догадаться, что это будет. По сути, это единственные вещи, которые нужно искать для сканирования. Когда вы смотрите на эту очень своеобразную форму и сочетание цветов настолько близко, что еще может быть? Бит, который я не рисовал, на белом фоне, должен считаться "чем-то непоследовательным". Если бы у него был прозрачный фон, он мог бы переходить практически на любое другое изображение, и вы все равно могли бы его видеть.
Кроме того, посмотрите на этот рисунок, который я сделал в MS Paint... Это абсолютно ужасно и довольно неполно, но, основываясь только на форме и цветах, вы можете догадаться, что это будет. По сути, это единственные вещи, которые нужно искать для сканирования. Когда вы смотрите на эту очень своеобразную форму и сочетание цветов настолько близко, что еще может быть? Бит, который я не рисовал, на белом фоне, должен считаться "чем-то непоследовательным". Если бы у него был прозрачный фон, он мог бы переходить практически на любое другое изображение, и вы все равно могли бы его видеть.
-
10Конкретный оттенок красного является в основном субъективным и сильно зависит от освещения и баланса белого. Вы можете быть удивлены тем, насколько они могут измениться. Рассмотрим, к примеру, эту иллюзию шахматной доски .
Я не знаю OpenCV, но, глядя на проблему логически, я думаю, что вы можете различать бутылку и можете, изменив изображение, которое вы ищете, например, Coca Cola. Вы должны включить до верхней части банки, так как в случае может быть серебряная подкладка наверху кока-колы, а в случае бутылки такой серебряной подкладки не будет.
Но очевидно, что этот алгоритм потерпит неудачу в тех случаях, когда вершина can скрыта, но в этом случае даже человек не сможет отличить два (если видна только часть кока-колы бутылки/банки)
-
1У меня была такая же мысль, но я думаю, что серебряная подкладка на верхней части банки резко меняется в зависимости от угла банки на изображении. Это может быть прямая линия или круг. Может быть, он мог использовать оба в качестве ссылки?
Мне нравится вызов и я хочу дать ответ, который решает проблему, я думаю.
- Извлечь функции (ключевые точки, дескрипторы, такие как SIFT, SURF) логотипа
- Совместите точки с образцом модели логотипа (используя Matcher, например Brute Force)
- Оцените координаты твердого тела (проблема PnP - SolvePnP)
- Оцените положение крышки в соответствии с жестким корпусом
- Сделайте обратную проекцию и вычислите положение пикселя изображения (ROI) крышки бутылки (я предполагаю, что у вас есть внутренние параметры камеры)
- Проверьте, существует ли кепка или нет. Если есть, то это бутылка
Обнаружение крышки - еще одна проблема. Это может быть сложным или простым. Если бы я был вами, я бы просто проверил цветную гистограмму в ROI для простого решения.
Пожалуйста, дайте отзыв, если я ошибаюсь. Благодарю.
Существует множество цветовых дескрипторов, используемых для распознавания объектов, в приведенной ниже статье сравниваются многие из них. Они особенно эффективны в сочетании с SIFT или SURF. Только SURF или SIFT не очень полезны для изображения кока-колы, потому что они не распознают множество точек интереса, вам нужна информация о цвете, чтобы помочь. Я использую BIC (Border/Interior Pixel Classi fiation) с SURF в проекте, и он отлично работал для распознавания объектов.
Цветовые дескрипторы для поиска веб-изображений: сравнительное исследование
-
1Ссылка не работает.
Мне нравится ваш вопрос, независимо от того, не зависит от него: P
Интересный в стороне; Я только что закончил тему в своей области, где мы рассмотрели робототехнику и компьютерное зрение. Наш проект на семестр был невероятно похож на тот, который вы описываете.
Нам пришлось разработать робот, который использовал Xbox Kinect для обнаружения коксовых бутылок и банок на любой ориентации в различных условиях освещения и окружающей среды. Наше решение включало использование полосового фильтра на канале Hue в сочетании с преобразованием окружности hough. Мы смогли немного ограничить окружающую среду (мы могли бы выбрать, где и как расположить робота и датчик Kinect), иначе мы собирались использовать преобразования SIFT или SURF.
Вы можете прочитать о нашем подходе на моем сообщении в блоге по теме:)
-
2Интересный проект, но он относится только к вашей очень конкретной настройке.
Вам нужна программа, которая изучает и улучшает точность классификации органически из опыта.
Я предлагаю глубокое обучение, с глубоким обучением это становится тривиальной проблемой.
Вы можете перенастроить начальную модель v3 на Tensorflow:
Как перенести начальный конечный уровень для новых категорий.
В этом случае вы будете обучать сверточную нейронную сеть, чтобы классифицировать объект, как может кока-кола или нет.
-
2Хот-дог или не хот-дог?
Глубокое обучение
Соберите по меньшей мере несколько сотен изображений, содержащих банки колы, аннотируйте ограничивающий прямоугольник вокруг них как положительные классы, включая бутылки колы и другие продукты колы, обозначающие их отрицательные классы, а также случайные объекты.
Если вы не собираете очень большой набор данных, выполните трюк использования глубоких функций обучения для небольшого набора данных. Идеально использовать комбинацию векторных машин поддержки (SVM) с глубокими нейронными сетями.
После того, как вы загрузите изображения в ранее обученную модель глубокого обучения (например, GoogleNet), вместо использования уровня принятия решений (окончательного) уровня нейронной сети для использования классификаций используйте данные предыдущего уровня (ов) как функции для обучения вашего классификатора.
OpenCV и Google Net: http://docs.opencv.org/trunk/d5/de7/tutorial_dnn_googlenet.html
OpenCV и SVM: http://docs.opencv.org/2.4/doc/tutorials/ml/introduction_to_svm/introduction_to_svm.html
Я несколько лет опаздываю, отвечая на этот вопрос. Поскольку в последние 5 лет современное искусство подтолкнуло CNN к своим пределам, я бы не стал использовать OpenCV для выполнения этой задачи сейчас! (Я знаю, что вам особенно нужны функции OpenCv в вопросе). Я считаю, что алгоритмы обнаружения объектов, такие как Faster-RCNN, YOLO, SSD и т.д., будут иметь эту проблему со значительным запасом по сравнению с функциями OpenCV. Если бы я решил решить эту проблему сейчас (через 6 лет!!), я бы определенно использовал Faster-RCNN.
В качестве альтернативы всем этим приятным решениям вы можете обучить свой собственный классификатор и сделать ваше приложение устойчивым к ошибкам. В качестве примера вы можете использовать Haar Training, предоставляя большое количество положительных и отрицательных изображений вашей цели.
Полезно извлекать только банки и их можно комбинировать с обнаружением прозрачных объектов.
Ответы на этой странице действительно равны:
-
"использовать SIFT"
-
"использовать Kinect"
Если вас не интересует фактическая информатика распознавания образов, и вы просто хотите "использовать" что-то (например, SIFT или Kinect),
сегодня повсеместно просто использовать общедоступные системы распознавания образов.
По состоянию на 2017 год и в течение многих лет распознавание изображений широко и тривиально доступно.
Вы больше не сядете и (попробуете) добиться распознавания образов с нуля, чем сядете и начнете собирать и отображать карты, или что вы начнете рендеринг HTML с нуля или напишите базу данных SQL с нуля.
Вы просто используете тензометр Google (они достигли точки построения чипов, ради всего прочего, быстрее обрабатывать тензорный поток), Clarifai, Bluemix или что-то еще.
AWS только что выпустила хороший для распознавания изображений (2018).
Например, для использования любой из этих служб это несколько строк кода....
func isItACokeCan() {
jds.headers = ["Accept-Language":"en"]
let h = JustOf<HTTP> ...use your favorite http library
let u: String =
"https://gateway-a.watsonplatform.net/visual-recognition/api/v3/classify"
+ "?api_key= ... your API key ..."
+ "&version=2016-05-20"
+ "&classifier_ids= ... your Classifier name ..."
h.post( u,
files: ["x.jpeg": .data("x.jpeg", liveImageData!, "image/jpeg")]
) { r in
if r.ok { DispatchQueue.main.async { self.processResult(r.json) } }
else { DispatchQueue.main.async { self.doResults("network woe?") } }
}
}
func processResult(_ rr: Any?){
let json = JSON(rr!)
print("\(json)")
}
Это буквально даст вам лучшее, существующее, кокс-распознавание на Земле, в настоящее время достигнутое.
По состоянию на 2018 год вы больше не можете сидеть и "писать лучше распознавания кокса, чем Bluemix", чем вы могли бы "сесть и написать лучшую программу Go, чем AlphaGo".
Системы, такие как Siri, Google Maps, BAAS, основные усилия по обработке изображений - и, очевидно, поиск в тексте google - меняют игру.
Обратите внимание на невероятную разницу только после того, как этот вопрос был задан шесть лет назад.
Во что бы то ни стало , если вы попали в фактическую компьютерную науку распознавания образов, перейдите к ней.
Но этот QA, по-видимому, является скорее обзором технологий.
Так как ответы здесь говорят "использовать библиотеку SIFT" - вы действительно этого не сделали. (Опять же - не более, чем вы по какой-то причине трудолюбиво программируете веб-сервер или базу данных SQL с нуля!)
Вы просто подключаетесь к хорошо известным, вездесущим системам распознавания образов "BAAS" - это строка кода.
Существует пакет компьютерного зрения под названием HALCON от MVTec, чьи демонстрации могут дать вам хорошие алгоритмические идеи. Существует множество примеров, похожих на вашу проблему, которые вы можете запустить в демонстрационном режиме, а затем посмотреть на операторов в коде и посмотреть, как их реализовать из существующих операторов OpenCV.
Я использовал этот пакет, чтобы быстро прототипировать сложные алгоритмы для таких проблем, а затем найти, как их реализовать, используя существующие функции OpenCV. В частности, для вашего случая вы можете попытаться реализовать в OpenCV функциональность, встроенную в оператор find_scaled_shape_model. Некоторые операторы указывают на научную статью о реализации алгоритма, которая может помочь выяснить, как сделать что-то подобное в OpenCV. Надеюсь, это поможет...
Вы всегда можете обучить каскадный классификатор HAAR, поддерживаемый opencv. Вы можете использовать в качестве положительных образцов бутылки, банки и т.д., Также обнаруживая объекты коки с разными этикетками!
ЗДЕСЬ вы можете воспользоваться некоторыми полезными ссылками, которые помогут вам в обучении.
Возможно, слишком много лет поздно, но тем не менее теория, чтобы попробовать.
Отношение ограничивающего прямоугольника красной области логотипа к общему размеру бутылки/банки отличается. В случае Can, должно быть 1:1, тогда как будет отличаться от бутылки (с крышкой или без нее). Это должно облегчить различие между ними.
Обновление: Горизонтальная кривизна области логотипа будет отличаться между Can и Bottle из-за их соответствующей разницы в размерах. Это может быть особенно полезно, если вашему роботу необходимо забрать банку/бутылку, и вы решите захват соответственно.
Первыми вещами, которые я бы искал, являются цветные - например, RED, при обнаружении эффекта "красных глаз" на изображении - существует определенный диапазон цветов для обнаружения, некоторые характеристики об этом, учитывая окружающие области и такие, как расстояние, отличное от другого глаз, если он действительно виден на изображении.
1: Первая характеристика - цвет, а красный - очень доминирующий. После обнаружения Coca Cola Red есть несколько объектов, представляющих интерес 1A: Насколько велика эта красная область (достаточно ли количества, чтобы определить истинную возможность или нет - 10 пикселей, вероятно, недостаточно), 1B: содержит ли он цвет ярлыка - "Coca-Cola" или волна. 1B1: достаточно ли рассмотреть высокую вероятность того, что это метка.
Пункт 1 - это вид короткого вырезания - предварительный процесс, если этот сотовый объект существует в изображении - двигайтесь дальше.
Итак, если это так, то я смогу использовать этот сегмент своего изображения и начну искать более масштабное изображение из области, о которой идет речь, - в основном посмотрите на окружающий регион/края...
2: Учитывая указанную выше ID области изображения в 1 - проверьте окружающие точки [края] рассматриваемого предмета. A: Есть ли что-то сверху или снизу - серебро? B: Бутылка может казаться прозрачной, но также может быть стеклянный стол - так есть стеклянный стол/полка или прозрачная область - если так, то есть несколько возможных вариантов. Бутылка MIGHT имеет красную крышку, она может и не быть, но должна иметь либо форму винтов/винтов для бутылок, либо колпачок. C: Даже если это не удается A и B, оно все еще может быть частично. Это более сложно, если это частично, потому что частичная бутылка/частичная может выглядеть одинаково, поэтому некоторая дополнительная обработка измерения края красной области до края. Маленькая бутылка может быть похожа по размеру.
3: После вышеупомянутого анализа, когда я посмотрю на надпись и логотип волны - потому что я могу ориентировать мой поиск некоторых букв в словах. Поскольку у вас может не быть всего текста из-за отсутствия все банки могут выровняться в определенных точках в тексте (на расстоянии), чтобы я мог найти эту вероятность и знать, какие буквы должны существовать в этой точке волны на расстоянии х.
Если вы заинтересованы в том, чтобы быть в реальном времени, то вам нужно добавить фильтр предварительной обработки, чтобы определить, что сканируется с помощью тяжелых вещей. Хороший быстрый, очень реальном времени, фильтр предварительной обработки, который позволит вам сканировать вещи, которые, скорее всего, будут кока-колой, может не выглядеть, чем прежде, чем перейти к более случайным вещам, это примерно так: поиск изображения для самых больших патчей цвета, которые являются определенным допуском от sqrt(pow(red,2) + pow(blue,2) + pow(green,2)) вашей кока-колы. Начните с очень строгой цветоустойчивости и проведите свой путь до более мягких цветовых допусков. Затем, когда ваш робот исчерпал выделенное время для обработки текущего кадра, он использует найденные в настоящее время бутылки для ваших целей. Обратите внимание, что вам нужно будет настроить цвета RGB в sqrt(pow(red,2) + pow(blue,2) + pow(green,2)), чтобы получить их в порядке.
Кроме того, это gona кажется действительно тупым, но вы обязательно включили оптимизацию компилятора -oFast при компиляции кода C?
Я думаю, что лучшая разница между меткой бутылки и ярлыком может выглядеть следующим образом: Буклетная этикетка прямо по краям сверху вниз. Может ли изображение вверху становится тоньше. Помимо этого, с точки зрения алгоритма чрезвычайно сложно сделать разницу. В моем алгоритме, анализируя моменты, я бы специально искал эту функцию.
Ещё вопросы
- 0Реализация моей собственной линзы в Panda3D
- 0Как отобразить HTML с угловым, когда объекты передаются
- 1Общие методы приводят это к T
- 0вставить HTML-разметку в HTML-строку PHP
- 0Нужно img: парить, чтобы не повлиять на макет
- 0Типы функций PHP-функций - одновременное использование атрибутов contentType и type не поддерживается
- 1unauthorized_client: клиент не авторизован для получения токенов доступа с помощью этого метода
- 1невозможно получить контур правильно
- 0перемещение приложения php на локальный сервер
- 0Как можно эмулировать нажатие клавиатуры или мыши?
- 0Показывать электронные письма из Gmail на веб-сайте SaaS
- 0Как я могу добавить значок на заголовке с выравниванием по центру в ионном?
- 0Выполнить функцию, если не удается выполнить другую функцию в течение периода времени
- 1Получить IP из AWS SDK descriptionAddresses
- 0Как обнаружить, что директива B находится внутри директивы A
- 1Счетчик значений по группе не показывает счетчик значений NULL / NA в пандах
- 1Получить значение из ListBox, содержащего TextBlocks, используя SelectedItem в WPF
- 1BackgroundWorker ReportProgress из другого класса
- 0Интерфейс Laravel
- 0«Двойной результат», когда я использую случай, когда заявление
- 0AngularJS 10 $ digest () достигнуты итерации. Попытка синхронизировать службу, контроллер и представление с помощью $ watch работает, но вызывает ошибки
- 1Запустите скрипт оболочки из терминала с аргументом строки и списка Python
- 0MySQL: нужно выбрать список уникальных названий улиц из таблицы адресов
- 1прекратите зарядку, когда батарея полностью заряжена
- 1Рассчитать RA DEC / AZ EL точек Лагранжа, видимых с места на земле
- 0использовать DGEMM BLAS в Windows Eclipse
- 1Как установить переменную среды PYTHONUTF8 для включения кодировки UTF-8 по умолчанию в Python?
- 1Валюта текстовое поле реагировать родной
- 0Объединить 2 ассоциативных массива путем сопоставления значения подмассива?
- 0Как внедрить $ scope в шаблон компиляции?
- 1Изображение Android не вращается после 1-го запуска с помощью ViewPropertyAnimator
- 0Отладка сортировки слиянием
- 1Пользовательский агрегат RadGrid: где я?
- 1Вставка Сортировка LinkedList Java
- 0Контент в моем iframe не кликабелен в Chrome, но работает в IE
- 0Области применения переменных и объектов в угловых
- 1Как отправить сообщение NDEF с телефона Android на Pi
- 0JQuery Datepicker - ограничить опции TIME
- 1Lightinject - Обнаружена рекурсивная зависимость
- 0Заполнение выпадающего списка с помощью jquery
- 1строитель электронов не связывает файлы python
- 1Круглый значок не отображается на Зефир
- 0Замена набора данных 1,5 миллиона строк каждые 5 минут
- 1Обходное окно window.location.hash для chrome / angular2
- 1C # x509Certificate2 не может быть создан
- 1xna c # перехватить и отменить кнопку закрытия окна (x) и Ctrl F4
- 1Как сделать для цикла быстрее с NumPy
- 1Java: изменить значение объекта без изменения всех ссылок
- 0Как предотвратить открытие редактора сетки кендо, всплывающих в JavaScript
- 0Мои значки не будут отображаться в моем нижнем колонтитуле
