Что означает «коалгебра» в контексте программирования?
Я слышал термин "коалгебры" несколько раз в функциональном программировании и кругах PLT, особенно когда речь идет об объектах, комонадах, объективах и т.д. В результате этого термина даны страницы, которые дают математическое описание этих структур, что для меня совершенно непонятно. Может ли кто-нибудь объяснить, что означают коалгебры в контексте программирования, каково их значение и как они относятся к объектам и комонадам?
-
19Могу ли я порекомендовать отличную книгу Джереми Гиббонса «Образцы в FP»: templatesinfp.wordpress.com и его вполне понятную статью «Расчет функциональных программ»? Они оба охватывают угольные алгебры довольно строго (по сравнению, например, с сообщением в блоге), но они также довольно самодостаточны для тех, кто немного знает Хаскель.Kristopher Micinski
-
2@KristopherMicinski, очень интересно. Спасибо!missingfaktor
4 ответа
Алгебры
Я думаю, что местом для начала было бы понять идею алгебры. Это всего лишь обобщение алгебраических структур, таких как группы, кольца, моноиды и т.д. В большинстве случаев эти вещи вводятся с точки зрения множеств, но поскольку мы находимся среди друзей, я буду говорить о типах Haskell. (Я не могу сопротивляться использованию некоторых греческих букв, хотя они делают все более круче!)
Тогда алгебра является просто типом τ с некоторыми функциями и тождествами. Эти функции принимают различное количество аргументов типа τ и производят τ: uncurried, все они выглядят как (τ, τ,…, τ) → τ. Они также могут иметь "идентичности" -элементы τ, которые имеют особое поведение с некоторыми функциями.
Простейшим примером этого является моноид. Моноидом является любой тип τ с функцией mappend ∷ (τ, τ) → τ и личность mzero ∷ τ. Другие примеры включают такие вещи, как группы (которые похожи на моноиды, за исключением дополнительной функции invert ∷ τ → τ), колец, решеток и т.д.
Все функции работают на τ, но могут иметь разные значения. Мы можем записать их как τⁿ → τ, где τⁿ отобразится в набор из n τ. Таким образом, имеет смысл думать о тождествах как τ⁰ → τ, где τ⁰ - это всего лишь пустой набор (). Таким образом, мы можем фактически упростить идею алгебры: это всего лишь некоторый тип с некоторым количеством функций на нем.
Алгебра - это всего лишь обычная закономерность в математике, которая была "деформирована", как и мы с кодом. Люди заметили, что целая куча интересных вещей - вышеупомянутые моноиды, группы, решетки и т.д. - все следуют аналогичной схеме, поэтому они абстрагировали ее. Преимущество этого - то же, что и в программировании: оно создает многоразовые доказательства и облегчает некоторые виды рассуждений.
F-алгебра
Однако мы не совсем сделали это с факторингом. До сих пор у нас есть куча функций τⁿ → τ. На самом деле мы можем сделать аккуратный трюк, чтобы объединить их в одну функцию. В частности, посмотрим на моноиды: у нас есть mappend ∷ (τ, τ) → τ и mempty ∷ () → τ. Мы можем превратить их в одну функцию, используя тип суммы - Either. Это будет выглядеть так:
op ∷ Monoid τ ⇒ Either (τ, τ) () → τ
op (Left (a, b)) = mappend (a, b)
op (Right ()) = mempty
Мы можем использовать это преобразование многократно, чтобы объединить все функции τⁿ → τ в одну, для любой алгебры. (На самом деле мы можем сделать это для любого числа функций a → τ, b → τ и т.д. Для любого a, b,….)
Это позволяет говорить о алгебрах как тип τ с одной функцией от некоторого беспорядка Either до единственного τ. Для моноидов этот беспорядок: Either (τ, τ) (); для групп (которые имеют дополнительную операцию τ → τ), это: Either (Either (τ, τ) τ) (). Это другой тип для каждой другой структуры. Итак, что общего у всех этих типов? Самое очевидное, что все они представляют собой просто суммы продуктов-алгебраических типов данных. Например, для моноидов мы могли бы создать тип аргумента моноида, который работает для любого моноида τ:
data MonoidArgument τ = Mappend τ τ -- here τ τ is the same as (τ, τ)
| Mempty -- here we can just leave the () out
Мы можем сделать то же самое для групп и колец и решеток и всех других возможных структур.
Что еще особенного в отношении всех этих типов? Ну, они все Functors! Например:
instance Functor MonoidArgument where
fmap f (Mappend τ τ) = Mappend (f τ) (f τ)
fmap f Mempty = Mempty
Таким образом, мы можем еще больше обобщить нашу идею алгебры. Это всего лишь некоторый тип τ с функцией f τ → τ для некоторого функтора f. Фактически, мы могли бы записать это как класс:
class Functor f ⇒ Algebra f τ where
op ∷ f τ → τ
Это часто называют "F-алгеброй", потому что он определяется функтором f. Если бы мы могли частично применять классы типов, мы могли бы определить что-то вроде class Monoid = Algebra MonoidArgument.
коалгебрах
Теперь, надеюсь, вы хорошо понимаете, что такое алгебра и как это просто обобщение нормальных алгебраических структур. Итак, что такое F-коалгебра? Ну, co подразумевает, что это "двойственное" алгебра, то есть мы берем алгебру и переворачиваем некоторые стрелки. Я вижу только одну стрелку в приведенном выше определении, поэтому я просто переверну это:
class Functor f ⇒ CoAlgebra f τ where
coop ∷ τ → f τ
И это все! Теперь этот вывод может показаться немного легкомысленным (хех). Он говорит вам, что такое коалгебра, но на самом деле не дает никакого представления о том, как это полезно или почему мы заботимся. Я доберусь до этого немного, как только найду или придумаю хороший пример или два: P.
Классы и объекты
Прочитав немного, я думаю, что у меня есть хорошая идея, как использовать коалгебры для представления классов и объектов. У нас есть тип C, который содержит все возможные внутренние состояния объектов в классе; сам класс является коалгеброй над C, которая определяет методы и свойства объектов.
Как показано в примере алгебры, если у нас есть куча функций типа a → τ и b → τ для любого a, b,…, мы можем объединить их все в одну функцию, используя Either, тип суммы. Двойное "понятие" будет сочетать кучу функций типа τ → a, τ → b и так далее. Мы можем сделать это, используя двойственный тип суммы - тип продукта. Поэтому, учитывая две вышеперечисленные функции (называемые f и g), мы можем создать один такой:
both ∷ τ → (a, b)
both x = (f x, g x)
Тип (a, a) является прямолинейным функтором, поэтому он, безусловно, соответствует нашему понятию F-коалгебры. Этот конкретный трюк позволяет нам упаковать множество различных функций - или, для ООП, - в одну функцию типа τ → f τ.
Элементы нашего типа C представляют внутреннее состояние объекта. Если объект имеет некоторые читаемые свойства, они должны быть в состоянии зависеть от состояния. Самый очевидный способ сделать это - сделать их функцией C. Поэтому, если нам требуется свойство length (например, object.length), у нас будет функция C → Int.
Нам нужны методы, которые могут принимать аргумент и изменять состояние. Для этого нам нужно взять все аргументы и создать новый C. Представьте себе метод setPosition, который принимает координату x и a y: object.setPosition(1, 2). Это будет выглядеть так: C → ((Int, Int) → C).
Важным здесь является то, что "методы" и "свойства" объекта берут объект в качестве первого аргумента. Это похоже на параметр self в Python и как неявный this для многих других языков. Коалгебра по существу просто инкапсулирует поведение взятия параметра self: что первый C в C → F C есть.
Итак, пусть все вместе. Представьте себе класс с свойством position, a name и setPosition:
class C
private
x, y : Int
_name : String
public
name : String
position : (Int, Int)
setPosition : (Int, Int) → C
Нам нужно две части для представления этого класса. Во-первых, нам нужно представить внутреннее состояние объекта; в этом случае он просто содержит два Int и a String. (Это наш тип C.) Тогда нам нужно придумать коалгебру, представляющую класс.
data C = Obj { x, y ∷ Int
, _name ∷ String }
У нас есть два свойства для записи. Они довольно тривиальны:
position ∷ C → (Int, Int)
position self = (x self, y self)
name ∷ C → String
name self = _name self
Теперь нам просто нужно обновить позицию:
setPosition ∷ C → (Int, Int) → C
setPosition self (newX, newY) = self { x = newX, y = newY }
Это как класс Python с его явными переменными self. Теперь, когда у нас есть куча функций self →, нам нужно объединить их в одну функцию для коалгебры. Мы можем сделать это с помощью простого кортежа:
coop ∷ C → ((Int, Int), String, (Int, Int) → C)
coop self = (position self, name self, setPosition self)
Тип ((Int, Int), String, (Int, Int) → c) - для любого C - является функтором, поэтому coop имеет желаемый вид: Functor f ⇒ C → f C.
Учитывая это, C вместе с coop образуют коалгебру, которая задает класс I, указанный выше. Вы можете увидеть, как мы можем использовать этот же метод, чтобы указать любое количество методов и свойств для наших объектов.
Это позволяет использовать коалгебраические рассуждения для рассмотрения классов. Например, мы можем ввести понятие "гомоморфизма F-коалгебр" для представления преобразований между классами. Это пугающий звуковой термин, который просто означает трансформацию между коалгебрами, которые сохраняют структуру. Это значительно облегчает мысль о сопоставлении классов с другими классами.
Короче говоря, F-коалгебра представляет класс, имея кучу свойств и методов, которые зависят от параметра self, содержащего каждое внутреннее состояние объекта.
Другие категории
До сих пор мы говорили о алгебрах и коалгебрах как типы Хаскелла. Алгебра - это всего лишь тип τ с функцией f τ → τ, а коалгебра - это просто тип τ с функцией τ → f τ.
Однако ничто действительно не связывает эти идеи с Хаскеллом как таковым. Фактически, они обычно вводятся в терминах множеств и математических функций, а не типов и функций Haskell. Действительно, мы можем обобщить эти понятия на любые категории!
Мы можем определить F-алгебру для некоторой категории C. Во-первых, нам нужен функтор F : C → C, т.е. Эндофонн. (Все Haskell Functor на самом деле являются эндофенторами из Hask → Hask.) Тогда алгебра - это просто объект A из C с морфизмом F A → A. Коалгебра такая же, за исключением A → F A.
Что мы можем получить, рассмотрев другие категории? Ну, мы можем использовать одни и те же идеи в разных контекстах. Как монады. В Haskell монада представляет собой некоторый тип M ∷ ★ → ★ с тремя операциями:
map ∷ (α → β) → (M α → M β)
return ∷ α → M α
join ∷ M (M α) → M α
Функция map является просто доказательством того, что M является Functor. Итак, мы можем сказать, что монада - это просто функтор с двумя операциями: return и join.
Функторы образуют сами категорию, причем морфизмы между ними являются так называемыми "естественными преобразованиями". Естественное преобразование - это просто способ превратить один функтор в другой, сохранив его структуру. Вот хорошая статья, помогающая объяснить идею. Он говорит о concat, который просто join для списков.
С функторами Хаскелла композиция из двух функторов является самим функтором. В псевдокоде мы могли бы написать это:
instance (Functor f, Functor g) ⇒ Functor (f ∘ g) where
fmap fun x = fmap (fmap fun) x
Это помогает нам думать о join как о преобразовании из f ∘ f → f. Тип join - ∀α. f (f α) → f α. Интуитивно мы видим, как функцию, действительную для всех типов α, можно рассматривать как преобразование f.
return является аналогичным преобразованием. Его тип ∀α. α → f α. Это выглядит по-другому - первый α не является "в" функтором! К счастью, мы можем исправить это, добавив туда функтор тождества: ∀α. Identity α → f α. Итак, return является преобразованием Identity → f.
Теперь мы можем думать о монаде как о просто алгебре, базирующейся вокруг некоторого функтора f с операциями f ∘ f → f и Identity → f. Разве это не знакомо? Он очень похож на моноид, который был всего лишь одним типом τ с операциями τ × τ → τ и () → τ.
Итак, монада похожа на моноид, но вместо того, чтобы иметь тип, у нас есть функтор. Это такая же алгебра, как раз в другой категории. (Здесь фраза "Монада - просто моноид в категории эндофунторов" происходит, насколько я знаю.)
Теперь у нас есть две операции: f ∘ f → f и Identity → f. Чтобы получить соответствующую коалгебру, мы просто перевернем стрелки. Это дает нам две новые операции: f → f ∘ f и f → Identity. Мы можем превратить их в типы Haskell, добавив переменные типа, как указано выше, давая нам ∀α. f α → f (f α) и ∀α. f α → α. Это выглядит так же, как определение comonad:
class Functor f ⇒ Comonad f where
coreturn ∷ f α → α
cojoin ∷ f α → f (f α)
Итак, комонада является тогда коалгеброй в категории эндофенторов.
-
43Это невероятно ценно. Мне удалось распутать некоторые интуиции об этом бизнесе F-алгебры из чтения и примеров (например, увидев их использование с катаморфизмом), но это все совершенно ясно, даже для меня. Спасибо!
-
24Это отличное объяснение.
F-алгебры и F-коалгебры являются математическими структурами, которые играют важную роль в рассуждении о индуктивных типах (или рекурсивных типах).
F-алгебра
Сначала мы начнем с F-алгебр. Я постараюсь быть как можно более простым.
Я думаю, вы знаете, что такое рекурсивный тип. Например, это тип для списка целых чисел:
data IntList = Nil | Cons (Int, IntList)
Очевидно, что он рекурсивный - действительно, его определение относится к самому себе. Его определение состоит из двух конструкторов данных, которые имеют следующие типы:
Nil :: () -> IntList
Cons :: (Int, IntList) -> IntList
Обратите внимание, что я написал тип Nil как () -> IntList, а не просто IntList. Это на самом деле эквивалентные типы с теоретической точки зрения, потому что тип () имеет только одного жителя.
Если мы будем писать сигнатуры этих функций более теоретически, мы получим
Nil :: 1 -> IntList
Cons :: Int × IntList -> IntList
где 1 - единичное множество (задано с одним элементом), а операция A × B является поперечным произведением двух наборов A и B (т.е. набора пар (a, b), где A проходит через все элементы A и B проходит через все элементы B).
Несвязанное объединение двух множеств A и B представляет собой набор A | B, являющийся объединением множеств {(a, 1) : a in A} и {(b, 2) : b in B}. По существу это набор всех элементов из A и B, но каждый из этих элементов "помечен" как принадлежащий либо A, либо B, поэтому, когда мы выбираем любой элемент из A | B, мы сразу узнает, пришел ли этот элемент из A или из B.
Мы можем "присоединиться" к Nil и Cons функциям, поэтому они образуют единую функцию, работающую на множестве 1 | (Int × IntList):
Nil|Cons :: 1 | (Int × IntList) -> IntList
В самом деле, если функция Nil|Cons применяется к значению () (которое, очевидно, принадлежит набору 1 | (Int × IntList)), то оно ведет себя так, как если бы оно было Nil; если Nil|Cons применяется к любому значению типа (Int, IntList) (такие значения также находятся в наборе 1 | (Int × IntList), он ведет себя как Cons.
Теперь рассмотрим другой тип данных:
data IntTree = Leaf Int | Branch (IntTree, IntTree)
Он имеет следующие конструкторы:
Leaf :: Int -> IntTree
Branch :: (IntTree, IntTree) -> IntTree
которые также могут быть объединены в одну функцию:
Leaf|Branch :: Int | (IntTree × IntTree) -> IntTree
Можно видеть, что обе эти функции joined имеют похожий тип: они оба выглядят как
f :: F T -> T
где F - это своего рода преобразование, которое берет наш тип и дает более сложный тип, который состоит из операций x и |, использования T и, возможно, других типов. Например, для IntList и IntTree F выглядит следующим образом:
F1 T = 1 | (Int × T)
F2 T = Int | (T × T)
Мы можем сразу заметить, что любой алгебраический тип может быть записан таким образом. Действительно, поэтому их называют "алгебраическими": они состоят из ряда "сумм" (союзов) и "продуктов" (перекрестных произведений) других типов.
Теперь мы можем определить F-алгебру. F-алгебра - это просто пара (T, f), где T - некоторый тип, а F - функция типа f :: F T -> T. В наших примерах F-алгебры (IntList, Nil|Cons) и (IntTree, Leaf|Branch). Обратите внимание, однако, что, несмотря на то, что тип F для каждого F одинаковый, то сами T и F могут быть произвольными. Например, (String, g :: 1 | (Int x String) -> String) или (Double, h :: Int | (Double, Double) -> Double) для некоторых g и h также являются F-алгебрами для соответствующих F.
Впоследствии мы можем ввести гомоморфизмы F-алгебр, а затем начальные F-алгебры, обладающие очень полезными свойствами. Действительно, (IntList, Nil|Cons) - начальная F1-алгебра, а (IntTree, Leaf|Branch) - начальная F2-алгебра. Я не буду приводить точные определения этих терминов и свойств, поскольку они более сложны и абстрактны, чем нужно.
Тем не менее тот факт, что, скажем, (IntList, Nil|Cons) является F-алгеброй, позволяет определить такую функцию типа t269. Как вы знаете, fold - это своего рода операция, которая преобразует некоторый рекурсивный тип данных за одно конечное значение. Например, мы можем свернуть список целых чисел в одно значение, которое является суммой всех элементов в списке:
foldr (+) 0 [1, 2, 3, 4] -> 1 + 2 + 3 + 4 = 10
Можно обобщить такую операцию на любой рекурсивный тип данных.
Ниже представлена сигнатура функции foldr:
foldr :: ((a -> b -> b), b) -> [a] -> b
Обратите внимание, что я использовал фигурные скобки, чтобы отделить первые два аргумента от последнего. Это не реальная функция foldr, но она изоморфна ей (т.е. Вы можете легко получить ее от другой и наоборот). Частично примененный foldr будет иметь следующую подпись:
foldr ((+), 0) :: [Int] -> Int
Мы видим, что это функция, которая берет список целых чисел и возвращает одно целое число. Пусть определим такую функцию в терминах нашего типа IntList.
sumFold :: IntList -> Int
sumFold Nil = 0
sumFold (Cons x xs) = x + sumFold xs
Мы видим, что эта функция состоит из двух частей: первая часть определяет это поведение функции на Nil части IntList, а вторая часть определяет поведение функции на части Cons.
Теперь предположим, что мы программируем не в Haskell, а на каком-то языке, который позволяет использовать алгебраические типы непосредственно в сигнатурах типов (ну, технически Haskell допускает использование алгебраических типов через кортежи и тип данных Either a b, но это приведет к ненужному подробность). Рассмотрим функцию:
reductor :: () | (Int × Int) -> Int
reductor () = 0
reductor (x, s) = x + s
Можно видеть, что reductor является функцией типа F1 Int -> Int, как и в определении F-алгебры! Действительно, пара (Int, reductor) является F1-алгеброй.
Поскольку IntList является начальной F1-алгеброй, для каждого типа T и для каждой функции r :: F1 T -> T существует функция, называемая катаморфизмом для r, которая преобразует IntList в T и такая функция единственна. Действительно, в нашем примере катаморфизм для reductor равен sumFold. Обратите внимание, как reductor и sumFold похожи: они имеют почти ту же структуру! В определении reductor s использование параметра (тип которого соответствует T) соответствует использованию результата вычисления sumFold xs в определении sumFold.
Чтобы сделать его более понятным и помочь вам увидеть шаблон, вот еще один пример, и мы снова начинаем с полученной функции сгибания. Рассмотрим функцию append, которая добавляет первый аргумент ко второму:
(append [4, 5, 6]) [1, 2, 3] = (foldr (:) [4, 5, 6]) [1, 2, 3] -> [1, 2, 3, 4, 5, 6]
Как это выглядит на нашем IntList:
appendFold :: IntList -> IntList -> IntList
appendFold ys () = ys
appendFold ys (Cons x xs) = x : appendFold ys xs
Опять попробуем записать редуктор:
appendReductor :: IntList -> () | (Int × IntList) -> IntList
appendReductor ys () = ys
appendReductor ys (x, rs) = x : rs
appendFold является катаморфизмом для appendReductor, который преобразует IntList в IntList.
Таким образом, по существу, F-алгебры позволяют определить "складки" на рекурсивных структурах данных, т.е. операции, которые сводят наши структуры к некоторому значению.
F-коалгебрами
F-коалгебры являются так называемым "двойственным" членом для F-алгебр. Они позволяют нам определить unfolds для рекурсивных типов данных, то есть способ построения рекурсивных структур из некоторого значения.
Предположим, что у вас есть следующий тип:
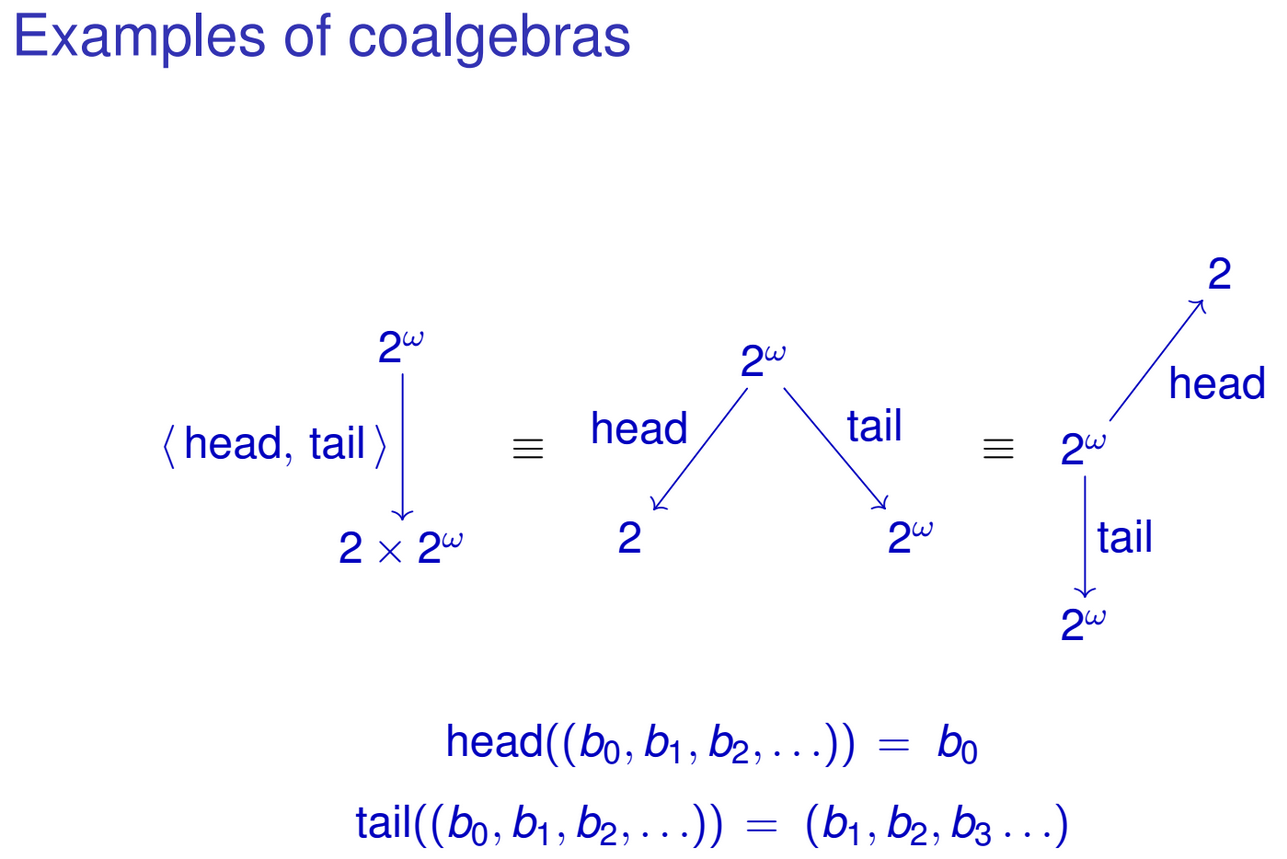
data IntStream = Cons (Int, IntStream)
Это бесконечный поток целых чисел. Его единственный конструктор имеет следующий тип:
Cons :: (Int, IntStream) -> IntStream
Или, в терминах множеств
Cons :: Int × IntStream -> IntStream
Haskell позволяет сопоставлять шаблоны конструкторам данных, поэтому вы можете определить следующие функции, работающие на IntStream s:
head :: IntStream -> Int
head (Cons (x, xs)) = x
tail :: IntStream -> IntStream
tail (Cons (x, xs)) = xs
Вы можете "объединить" эти функции в одну функцию типа IntStream -> Int × IntStream:
head&tail :: IntStream -> Int × IntStream
head&tail (Cons (x, xs)) = (x, xs)
Обратите внимание, как результат функции совпадает с алгебраическим представлением нашего типа IntStream. Аналогичную вещь можно сделать и для других рекурсивных типов данных. Возможно, вы уже заметили шаблон. Я имею в виду семейство функций типа
g :: T -> F T
где T - некоторый тип. Отныне мы определим
F1 T = Int × T
Теперь F-коалгебра представляет собой пару (T, g), где T - тип, а g - функция типа g :: T -> F T. Например, (IntStream, head&tail) является F1-коалгеброй. Опять же, как и в F-алгебрах, g и T могут быть произвольными, например, (String, h :: String -> Int x String) также является F1-коалгеброй для некоторого h.
Среди всех F-коалгебр существуют так называемые терминальные F-коалгебры, которые являются двойственными к начальным F-алгебрам. Например, IntStream является терминальной F-коалгеброй. Это означает, что для каждого типа T и для каждой функции p :: T -> F1 T существует функция, называемая анаморфизмом, которая преобразует T в IntStream, и такая функция уникальна.
Рассмотрим следующую функцию, которая генерирует поток последовательных целых чисел, начиная с заданного:
nats :: Int -> IntStream
nats n = Cons (n, nats (n+1))
Теперь рассмотрим функцию natsBuilder :: Int -> F1 Int, то есть natsBuilder :: Int -> Int × Int:
natsBuilder :: Int -> Int × Int
natsBuilder n = (n, n+1)
Опять же, мы можем видеть некоторое сходство между nats и natsBuilder. Он очень похож на связь, которую мы наблюдали с редукторами и складками ранее. nats является анаморфизмом для natsBuilder.
Другой пример: функция, которая принимает значение и функцию и возвращает поток последовательных приложений функции к значению:
iterate :: (Int -> Int) -> Int -> IntStream
iterate f n = Cons (n, iterate f (f n))
Его функция-строитель следующая:
iterateBuilder :: (Int -> Int) -> Int -> Int × Int
iterateBuilder f n = (n, f n)
Тогда iterate является анаморфизмом для iterateBuilder.
Заключение
Итак, вкратце, F-алгебры позволяют определять складки, то есть операции, которые редуцируют структуру вниз до одного значения, а F-коалгебры позволяют сделать обратное: построить [потенциально] бесконечную структуру из одного значение.
Действительно, в F-алгебрах Haskell и F-коалгебрах совпадают. Это очень приятное свойство, которое является следствием наличия "нижнего" значения в каждом типе. Таким образом, в Haskell обе складки и разворачивания могут создаваться для каждого рекурсивного типа. Однако теоретическая модель позади этого сложнее, чем та, которую я представил выше, поэтому я сознательно избегал этого.
Надеюсь, что это поможет.
-
0Тип и определение
appendReductorвыглядит немного странно и не очень помогло мне увидеть шаблон там ... :) Можете ли вы еще раз проверить, что он правильный? .. Как должны выглядеть типы редукторов в целом? В определенииrесть,F1определяется IntList, или это произвольный F?
Прохождение учебного пособия Учебник по (со) алгебрам и (со) индукции должен дать вам некоторое представление о совместной алгебре в информатике.
Ниже приведена цитата, чтобы убедить вас,
В общих чертах, программа на некотором языке программирования манипулирует данными. В течение развития компьютерной науки за последние несколько десятилетий стало ясно, что абстрактная описание этих данных желательно, например, чтобы гарантировать, что одна программа не зависит от конкретного представления данных, на которых она работает. Кроме того, такая абстрактность облегчает доказательства корректности.
Это желание привело к использованию алгебраических методов в информатике, в ветки, называемой алгебраической спецификацией или абстрактной теорией типов данных. Объектом исследования являются сами типы данных, используя понятия техник, которые знакомы из алгебры. Типы данных, используемые компьютерными учеными, часто генерируются из заданного набора (конструкторов) операций, и именно по этой причине такая" инициативность "алгебр играет такую важную роль.
Стандартные алгебраические методы оказались полезными для сбора различных существенных аспектов структур данных, используемых в информатике. Но оказалось, что алгебраически сложно описать некоторые из присущих им динамических структур, возникающих при вычислении. Такие структуры обычно включают понятие государства, которое может быть трансформировано по-разному. Формальные подходы к таким государственным динамическим системам обычно используют автоматы или системы перехода, как классические ранние ссылки.
В течение последнего десятилетия постепенно возрастало понимание того, что такие государственные системы не следует описывать как алгебры, а как так называемые коалгебры. Это формальная двойственность алгебр, которая будет уточнена в этом уроке. Двойственное свойство" начальности" для алгебр, а именно завершение, оказалось решающим для таких коалгебр. И логический принцип рассуждения, который необходим для таких окончательных коалгебр, не является индукцией, а является коиндукцией.
Прелюдия, о теории категорий. Теорию категорий следует переименовать в теорию функторов. Поскольку категории - это то, что нужно определить для определения функторов. (Более того, функторы - это то, что нужно определить для определения естественных преобразований.)
Что такое функтор? Это преобразование из одного набора в другое, которое сохраняет их структуру. (Более подробно в сети есть много хорошего описания).
Что такое F-алгебра? Это алгебра функтора. Это просто изучение универсальной уместности функтора.
Как это может быть ссылка на информатику? Программу можно рассматривать как структурированный набор информации. Выполнение программы соответствует модификации этого структурированного набора информации. Хорошо, что выполнение должно сохранить структуру программы. Затем выполнение можно рассматривать как приложение функтора над этим набором информации. (Тот, который определяет программу).
Почему F-ко-алгебра? Программа двойственна по сути, поскольку они описываются информацией, и они действуют на нее. Тогда в основном информация, составляющая программу и изменяющая их, может быть просмотрена двумя способами.
- Данные, которые могут быть определены как информация, обрабатываемая программой.
- Состояние, которое можно определить как информацию, совместно используемую программой.
Тогда на этом этапе я хотел бы сказать, что
- F-алгебра - это исследование функториального преобразования, действующего над Вселенной Вселенной (как определено здесь).
- F-коалгебры - это изучение функториального преобразования, действующего на Государственную Вселенную (как определено здесь).
В течение жизни программы данные и состояние сосуществуют, и они дополняют друг друга. Они двойственны.
Я начну с вещей, которые, очевидно, связаны с программированием, а затем добавим некоторые математические материалы, чтобы сохранить их как конкретные, так и простые, как я могу.
Давайте процитировать некоторых ученых-ученых по вопросам coinduction...
http://www.cs.umd.edu/~micinski/posts/2012-09-04-on-understanding-coinduction.html
Индукция - это конечные данные, коиндукция - бесконечные данные.
Типичным примером бесконечных данных является тип ленивого списка (a поток). Например, скажем, что у нас есть следующий объект в память:
let (pi : int list) = (* some function which computes the digits of
π. *)
Компьютер не может содержать все π, поскольку он имеет только конечную сумму памяти! Но что он может сделать, это провести конечную программу, которая будет произвольное произвольное расширение π, которое вы желаете. Как долго поскольку вы используете только конечные части списка, вы можете вычислить с этим бесконечный список, сколько вам нужно.
Однако рассмотрим следующую программу:
let print_third_element (k : int list) = match k with
| _ :: _ :: thd :: tl -> print thd
print_third_element pi
Эта программа должна печатать третья цифра пи. Но на некоторых языках любой аргумент функции вычисляется перед передачей в функцию (строгая, не ленивая, оценка). Если мы будем использовать это порядок сокращения, то наша вышеприведенная программа будет работать навсегда, вычисляя цифры pi, прежде чем он может быть передан нашей функции принтера (которая никогда не бывает). Поскольку у машины нет бесконечной памяти, программа в конечном итоге исчерпает память и сбой. Это может быть не лучший порядок оценки.
http://adam.chlipala.net/cpdt/html/Coinductive.html
В ленивых функциональных языках программирования, таких как Haskell, бесконечные структуры данных везде. Бесконечные списки и более экзотические типы данных абстракции для связи между частями программы. Достижение аналогичных удобство без бесконечных ленивых структур во многих случаях требовало бы акробатические инверсии потока управления.
http://www.alexandrasilva.org/#/talks.html
Отнесение окружающего математического контекста к обычным задачам программирования
Что такое "алгебра"?
Алгебраические структуры обычно выглядят так:
- Материал
- Что может сделать материал
Это должно звучать как объекты с 1. свойствами и 2. методами. Или даже лучше, это должно звучать как сигнатуры типов.
Стандартные математические примеры включают моноида ⊃ group ⊃ вектор-пространство ⊃ "алгебра". Моноиды похожи на автоматы: последовательности глаголов (например, f.g.h.h.nothing.f.g.f). Журнал git, который всегда добавляет историю и никогда не удаляет его, будет моноидом, но не группой. Если вы добавляете инверсии (например, отрицательные числа, дроби, корни, удаляя накопленную историю, не разбивая разбитое зеркало), вы получаете группу.
Группы содержат вещи, которые могут быть добавлены или вычтены вместе. Например, Duration можно добавить вместе. (Но Date не может.) Длительности живут в векторном пространстве (а не только в группе), потому что их также можно масштабировать по внешним номерам. (Подпись типа scaling :: (Number,Duration) → Duration.)
Алгебры ⊂ векторные пространства могут сделать еще одно: theres some m :: (T,T) → T. Назовите это "умножение" или нет, потому что как только вы покинете Integers, его менее очевидно, что "умножение" (или "exponentiation" ) должно быть.
(Вот почему люди смотрят на универсальные свойства (категориальные): сказать им, что умножение должно делать или быть следующим:
 )
)
Алгебры → Коалгебры
Коммультипликацию легче определить таким образом, что она воспринимается не произвольно, чем умножение, потому что для перехода от T → (T,T) вы можете просто повторить один и тот же элемент. ( "диагональное отображение" - как диагональные матрицы/операторы в спектральной теории)
Учет обычно - это трассировка (сумма диагональных записей), хотя опять же важно то, что делает ваш контингент; trace является просто хорошим ответом для матриц.
Причиной смотреть на двойное пространство, в общем, является то, что легче думать в этом пространстве. Например, иногда легче думать о нормальном векторе, чем о нормальном нормальном плане, но вы можете управлять плоскостями (включая гиперплоскости) с векторами (и теперь я говорю о знакомом геометрическом векторе, как в луч-трассере).
Укрощение (un) структурированных данных
Математики могут моделировать что-то веселое, например TQFT, тогда как программистам приходится бороться с
- даты/время (
+ :: (Date,Duration) → Date), - places (
Paris& ne;(+48.8567,+2.3508)! Это форма, а не точка.), - неструктурированный JSON, который должен быть в некотором смысле последовательным,
- неправильный, но закрытый XML,
- невероятно сложные данные ГИС, которые должны удовлетворять множеству разумных отношений,
- регулярные выражения, которые что-то значили для вас, но означают значительно меньше perl.
- CRM, который должен содержать все номера исполнительных телефонов и вилл, имена его (теперь бывших) жен и детей, день рождения и все предыдущие подарки, каждый из которых должен удовлетворять "очевидным" отношениям (очевидным для клиента) которые невероятно сложно кодировать,
- .....
Ученые-компьютерщики, говоря о коалгебрах, обычно имеют в виду множество операций, как декартово произведение. Я считаю, что это то, что люди имеют в виду, когда говорят, что "Алгебры - это коалгебры в Хаскелле". Но в той мере, в какой программистам приходится моделировать сложные типы данных, такие как Place, Date/Time и Customer - и сделать эти модели похожими на реальный мир (или, по крайней мере, представление конечного пользователя реального мир), насколько это возможно, я считаю, что дуалисты могут быть полезными не только в мире с множеством.
Ещё вопросы
- 0«СОДЕРЖИТ» не работает в критериях просмотра
- 1Является ли Material TextAppearance полезным для обработки различных textSize
- 2Игнорирование видимого устройства GPU с вычислительной возможностью 3.0. Минимальная требуемая способность Cuda составляет 3,5
- 0PHP массив не работает правильно
- 0Как добавить прокручиваемый div внутри snap-контента, который исправлен?
- 0FullText InnoDB Поиск без ответа
- 1включая простой файл JavaScript в конфигурации WebPack 2
- 0выделить строку поиска с датой
- 1Мое приложение вылетает, даже если при его создании не было ошибок [duplicate]
- 0jquery - получить значение выбранной опции в выбранном входе
- 0Преобразовать целое число в формат времени, чтобы вы могли рассчитать разницу во времени с ним
- 0установка div со скрытым атрибутом данных с помощью jquery
- 0new-выражение и delete-выражение для константной ссылки и константного указателя
- 1Как создать библиотеку CHAQUOPY Android (файл .AAR или .JAR) в Android Studio
- 1NHibernate - наиболее лаконичный способ выбора нескольких столбцов с помощью QueryOver.
- 0Я не могу сгенерировать автоинкрементный Id, а hibernate всегда генерирует 1 как Id
- 0Я использую угловой фильтр «Дата», но что это за числовое выражение?
- 1Сигнал переподключается каждые 2 секунды, даже если сервер работает
- 0Как открыть вторичную ссылку IFRAME на Первичную ссылку IFRAME?
- 0JQuery получить индекс объекта, где поле равно значению
- 0AngularJS кликает только на небольших разрешениях
- 0сбой линии связи mysql на 2 ноутбуках
- 0OS X 10.10 (yosemite) PHP 5.5.14 - есть ли способ установить поддержку png без HomeBrew
- 1Как решить «ошибка: не удается найти символьную переменную new_location» в Android Studio?
- 1Как справиться с игровым потоком?
- 0Я хочу получать вложения в электронное письмо от формы
- 0Побитовое «не» нуля равно нулю, когда ноль рассчитывается сдвигами
- 1Функция module.exports не является функцией
- 0Список каталогов Apache с кнопкой загрузки и текстовым полем поиска
- 0В AngularJS, как я могу вызвать директиву внутри контроллера для выполнения задачи?
- 0Возникли проблемы с доступом к таблице с помощью моего запроса SQL. Не получить желаемый результат
- 0Усечение столбца BINARY в MySQL с использованием ALTER TABLE
- 1Заменить существующие R блестящие данные htmlwidget новыми данными
- 0Как вставить в таблицу SQL значения из var_char ($ _ POST) и выпадающие списки, сделанные с помощью цикла for?
- 0Проблемы тайм-аута сеанса с PHP MySQL
- 1ItemsControl в HubSection не на 100% высоты
- 0Я получаю указатель, который свободен, но не выделяется ошибка при запуске make, make test in putty
- 0Почему мой процесс останавливается при запуске в фоновом режиме?
- 1Как удалить строки с повторяющимися значениями столбцов во фрейме данных Pandas?
- 1Добавить целое число из другого класса в textView
- 1преобразование температуры Java в GUI
- 1преобразовать данные массива из объекта / float в int для использования в методе
- 0Наименование векселей с использованием оператора модуля С ++
- 0Слияние сортировки по структурам не работает
- 0Допустимо ли открывать журнал ошибок до тех пор, пока приложение работает?
- 0Упорядочение двух таблиц по одной дате с PHP, MYSQL (PDO)
- 1LinqToSql - SQL, сгенерированный CONCAT (UNION)
- 0Изменить цвет определенного ряда с помощью модуля выбора
- 1как найти угол определенной точки
- 1Моя программа зачетных книжек не печатает должным образом, чтобы превзойти документ
