Разница между скобками [] и двойными скобками [[]] для доступа к элементам списка или фрейма данных
R предоставляет два разных метода для доступа к элементам списка или оператора data.frame - [] и [[]].
В чем разница между этими двумя? В каких ситуациях я должен использовать один над другим?
11 ответов
Определение R-языка полезно для ответа на следующие типы вопросов:
R имеет три основных оператора индексирования: синтаксис, отображаемый в следующих примерах
х [г] x [i, j] х [[я]] x [[i, j]] х $ а х $ "а"Для векторов и матриц
[[формы редко используются, хотя они имеют некоторые незначительные смысловые отличия от[формы (например, он отбрасывает атрибуты имен или атрибутов dimnames, а частичное совпадение используется для символьных индексов). При индексировании многомерных структур с одним индексомx[[i]]илиx[i]вернетiй последовательный элементx.Для списков обычно используется
[[для выбора любого отдельного элемента, тогда как[возвращает список выбранных элементов.Форма
[[form] позволяет выбирать только один элемент с использованием целочисленных или символьных индексов, тогда как[позволяет индексировать по векторам. Обратите внимание, что для списка индекс может быть вектором, и каждый элемент вектора применяется в свою очередь к списку, выбранному компоненту, выбранному компоненту этого компонента и т.д. В результате все еще остается один элемент.
Значительные различия между этими двумя методами - это класс возвращаемых ими объектов при использовании для извлечения и могут ли они принимать диапазон значений или просто одно значение при назначении.
Рассмотрим случай извлечения данных в следующем списке:
foo <- list( str='R', vec=c(1,2,3), bool=TRUE )
Скажем, мы хотели бы извлечь значение, сохраненное bool из foo, и использовать его внутри оператора if(). Это иллюстрирует различия между значениями возврата [] и [[]], когда они используются для извлечения данных. Метод [] возвращает объекты списка классов (или data.frame, если foo был data.frame), в то время как метод [[]] возвращает объекты, класс которых определяется типом их значений.
Таким образом, использование метода [] приводит к следующему:
if( foo[ 'bool' ] ){ print("Hi!") }
Error in if (foo["bool"]) { : argument is not interpretable as logical
class( foo[ 'bool' ] )
[1] "list"
Это связано с тем, что метод [] возвратил список, а список недействителен для передачи непосредственно в оператор if(). В этом случае нам нужно использовать [[]], потому что он вернет "голый" объект, хранящийся в "bool", который будет иметь соответствующий класс:
if( foo[[ 'bool' ]] ){ print("Hi!") }
[1] "Hi!"
class( foo[[ 'bool' ]] )
[1] "logical"
Второе отличие состоит в том, что оператор [] может использоваться для доступа к слотам диапазона в списке или столбцах в кадре данных, в то время как оператор [[]] ограничен доступом к одиночный слот или столбец. Рассмотрим случай присвоения значений, используя второй список, bar():
bar <- list( mat=matrix(0,nrow=2,ncol=2), rand=rnorm(1) )
Скажем, мы хотим перезаписать последние два слота foo данными, содержащимися в баре. Если мы попытаемся использовать оператор [[]], то это произойдет:
foo[[ 2:3 ]] <- bar
Error in foo[[2:3]] <- bar :
more elements supplied than there are to replace
Это связано с тем, что [[]] ограничивается доступом к одному элементу. Нам нужно использовать []:
foo[ 2:3 ] <- bar
print( foo )
$str
[1] "R"
$vec
[,1] [,2]
[1,] 0 0
[2,] 0 0
$bool
[1] -0.6291121
Обратите внимание, что при успешном присваивании слоты в foo сохранили свои оригинальные имена.
Двойные скобки обращаются к элементу списка , а одна скобка возвращает вам список с одним элементом.
lst <- list('one','two','three')
a <- lst[1]
class(a)
## returns "list"
a <- lst[[1]]
class(a)
## returns "character"
[] извлекает список, [[]] извлекает элементы из списка
alist <- list(c("a", "b", "c"), c(1,2,3,4), c(8e6, 5.2e9, -9.3e7))
str(alist[[1]])
chr [1:3] "a" "b" "c"
str(alist[1])
List of 1
$ : chr [1:3] "a" "b" "c"
str(alist[[1]][1])
chr "a"
От Хэдли Уикхема:
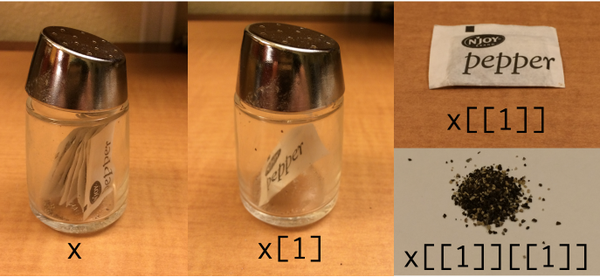
Моя (дерьмовая) модификация, показывающая использование tidyverse/purrr:

-
1Здорово! У тебя есть пикосекунды Грейс Хоппер!
Просто добавив, что [[ также оснащен рекурсивной индексацией.
Это было намечено в ответе @JijoMatthew, но не изучено.
Как отмечено в ?"[[", синтаксис типа x[[y]], где length(y) > 1, интерпретируется как:
x[[ y[1] ]][[ y[2] ]][[ y[3] ]] ... [[ y[length(y)] ]]
Обратите внимание, что это не меняет то, что должно быть вашим основным выносным разницей между значениями [ и [[, а именно, что первый используется для подмножества, а последний - используется для извлечения элементов единого списка.
Например,
x <- list(list(list(1), 2), list(list(list(3), 4), 5), 6)
x
# [[1]]
# [[1]][[1]]
# [[1]][[1]][[1]]
# [1] 1
#
# [[1]][[2]]
# [1] 2
#
# [[2]]
# [[2]][[1]]
# [[2]][[1]][[1]]
# [[2]][[1]][[1]][[1]]
# [1] 3
#
# [[2]][[1]][[2]]
# [1] 4
#
# [[2]][[2]]
# [1] 5
#
# [[3]]
# [1] 6
Чтобы получить значение 3, мы можем сделать:
x[[c(2, 1, 1, 1)]]
# [1] 3
Возвращаясь к ответу @JijoMatthew выше, напомните r:
r <- list(1:10, foo=1, far=2)
В частности, это объясняет ошибки, которые мы склонны получать при неправильном использовании [[, а именно:
r[[1:3]]
Ошибка в
r[[1:3]]: рекурсивная индексация завершилась неудачей на уровне 2
Поскольку этот код на самом деле пытался оценить r[[1]][[2]][[3]], а вложенность r останавливается на первом уровне, попытка извлечь из рекурсивной индексации завершилась с ошибкой [[2]], то есть на уровне 2.
Ошибка в
r[[c("foo", "far")]]: индекс за пределами
Здесь R искал r[["foo"]][["far"]], которого не существует, поэтому мы получаем ошибку индекса за пределами границ.
Вероятно, было бы немного более полезно/непротиворечиво, если бы обе эти ошибки дали одно и то же сообщение.
-
0Здравствуйте, Майкл, сэр, мы можем использовать [[]] для множественной индексации ??
Оба они являются способами подмножества. Единая скобка вернет подмножество списка, которое само по себе будет списком. т.е.: оно может содержать или не содержать более одного элемента. С другой стороны, двойная скобка возвращает только один элемент из списка.
- Единая скобка предоставит нам список. Мы также можем использовать одиночную скобку, если хотим вернуть несколько элементов из списка. рассмотрите следующий список: -
>r<-list(c(1:10),foo=1,far=2);
Теперь обратите внимание, как возвращается список, когда я пытаюсь его отобразить. I введите r и нажмите enter
>r
#the result is:-
[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
$foo
[1] 1
$far
[1] 2
Теперь мы увидим магию одной скобки: -
>r[c(1,2,3)]
#the above command will return a list with all three elements of the actual list r as below
[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
$foo
[1] 1
$far
[1] 2
что точно так же, как когда мы пытались отобразить значение r на экране, что означает, что использование единственной скобки вернуло список, где в индексе 1 мы имеем вектор из 10 элементов, то у нас есть еще два элемента с именами foo и far. Мы также можем указать один индекс или имя элемента в качестве входных данных для одной скобки. например:
> r[1]
[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
В этом примере мы дали один индекс "1" и взамен получили список с одним элементом (который представляет собой массив из 10 чисел)
> r[2]
$foo
[1] 1
В приведенном выше примере мы дали один индекс "2" и в ответ получили список с одним элементом
> r["foo"];
$foo
[1] 1
В этом примере мы передали имя одного элемента, и в результате список был возвращен одним элементом.
Вы также можете передать вектор имен элементов, например: -
> x<-c("foo","far")
> r[x];
$foo
[1] 1
$far
[1] 2
В этом примере мы передали вектор с двумя именами элементов "foo" и "far"
Взамен мы получили список с двумя элементами.
Короче говоря, одна скобка всегда возвращает вам другой список с количеством элементов, равным количеству элементов или количеству индексов, которые вы передаете в одну скобку.
Напротив, двойная скобка всегда возвращает только один элемент.
Прежде чем переходить к двойной скобке, нужно иметь в виду примечание.
NOTE:THE MAJOR DIFFERENCE BETWEEN THE TWO IS THAT SINGLE BRACKET RETURNS YOU A LIST WITH AS MANY ELEMENTS AS YOU WISH WHILE A DOUBLE BRACKET WILL NEVER RETURN A LIST. RATHER A DOUBLE BRACKET WILL RETURN ONLY A SINGLE ELEMENT FROM THE LIST.
Я приведу несколько примеров. Пожалуйста, обратите внимание на слова, выделенные жирным шрифтом, и вернитесь к нему после того, как вы закончите с приведенными ниже примерами:
Двойная скобка вернет вам фактическое значение в индексе. (Он будет НЕ возвращать список)
> r[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
>r[["foo"]]
[1] 1
для двойных скобок, если мы попытаемся просмотреть несколько элементов, передав вектор, это приведет к ошибке только потому, что она не была построена для удовлетворения этой потребности, а просто для возврата одного элемента.
Рассмотрим следующее
> r[[c(1:3)]]
Error in r[[c(1:3)]] : recursive indexing failed at level 2
> r[[c(1,2,3)]]
Error in r[[c(1, 2, 3)]] : recursive indexing failed at level 2
> r[[c("foo","far")]]
Error in r[[c("foo", "far")]] : subscript out of bounds
-
1Недопустимо, потому что «передача вектора ... приведет к ошибке только потому, что он не был создан для удовлетворения этой потребности» - неверно; смотри мой новый ответ.
-
1Понижен, потому что это делает сильные заявления как, "КОГДА ДВОЙНОЙ КРОНШТЕЙН НИКОГДА НЕ ВОЗВРАЩАЕТ СПИСОК". Это неправда - если у нас есть объект, который является списком списков, двойная скобка вернет другой список.
Чтобы помочь новичкам перемещаться по ручному туману, может быть полезно увидеть нотацию [[ ... ]] как функцию свертывания - другими словами, именно тогда, когда вы просто хотите "получить данные" из именованного вектора, перечислите или кадра данных. Это полезно сделать, если вы хотите использовать данные из этих объектов для расчетов. Эти простые примеры иллюстрируют.
(x <- c(x=1, y=2)); x[1]; x[[1]]
(x <- list(x=1, y=2, z=3)); x[1]; x[[1]]
(x <- data.frame(x=1, y=2, z=3)); x[1]; x[[1]]
Итак, из третьего примера:
> 2 * x[1]
x
1 2
> 2 * x[[1]]
[1] 2
-
1Как новичок, я нашел полезным в 3 назначениях x (используя «<-») заменить x = 1 на w = 1, чтобы избежать путаницы с x, который является целью «<-»
Для еще одного конкретного варианта использования используйте двойные скобки, когда вы хотите выбрать фрейм данных, созданный функцией split(). Если вы не знаете, split() группирует список/фрейм данных в подмножества на основе поля ключа. Это полезно, если вы хотите работать с несколькими группами, нарисуйте их и т.д.
> class(data)
[1] "data.frame"
> dsplit<-split(data, data$id)
> class(dsplit)
[1] "list"
> class(dsplit['ID-1'])
[1] "list"
> class(dsplit[['ID-1']])
[1] "data.frame"
Будучи терминологическим, оператор [[ извлекает элемент из списка, тогда как оператор [ принимает подмножество списка.
Пожалуйста, обратитесь к ниже подробному объяснению.
Я использовал встроенный фрейм данных в R, называемый mtcars.
> mtcars
mpg cyl disp hp drat wt ...
Mazda RX4 21.0 6 160 110 3.90 2.62 ...
Mazda RX4 Wag 21.0 6 160 110 3.90 2.88 ...
Datsun 710 22.8 4 108 93 3.85 2.32 ...
............
Верхняя строка таблицы называется заголовком, который содержит имена столбцов. Каждая горизонтальная линия впоследствии обозначает строку данных, которая начинается с имени строки, а затем за ней следуют фактические данные. Каждый элемент данных строки называется ячейкой.
одиночная квадратная скобка "[]"
Для извлечения данных в ячейке мы вводим его координаты строк и столбцов в одиночном квадратном скобке "[]". Две координаты разделены запятой. Другими словами, координаты начинаются с позиции строки, затем за запятой и заканчиваются позицией столбца. Порядок важен.
Например, 1: - Здесь значение ячейки из первой строки, второй столбец mtcars.
> mtcars[1, 2]
[1] 6
Например, 2: - Кроме того, мы можем использовать имена строк и столбцов вместо числовых координат.
> mtcars["Mazda RX4", "cyl"]
[1] 6
Двойная квадратная скобка "[[]]" оператор
Мы ссылаемся на столбец фреймов данных с помощью оператора двойной квадратной скобки [[]].
Например, 1: - Чтобы получить девятый вектор столбца встроенного набора данных mtcars, мы пишем mtcars [[9]].
mtcars [[9]] [1] 1 1 1 0 0 0 0 0 0 0 0...
Например, 2: - Мы можем получить один и тот же вектор столбца по его названию.
mtcars [["am"]] [1] 1 1 1 0 0 0 0 0 0 0 0...
Ещё вопросы
- 0Карты Google отключают маршруты и отображают карту напрямую
- 0Получить всю зарплату сотрудника из таблиц сотрудников с 3-й по величине зарплаты в MYSQL
- 1Приложение Android закрывается при добавлении класса-оболочки в манифест
- 1Почему действие возвращается к предыдущему, когда я получаю данные из базы данных?
- 0Подождите, пока звук не закончится, чтобы использовать страницу
- 0Изменение непрозрачности Javascript
- 1Использование экземпляра одноэлементного класса в качестве переменной уровня класса приемлемо?
- 1G1GC Значения округления бревен для больших куч
- 1Как разделить макет на 3 вида
- 0Угловое извлечение всех заголовочных файлов html в один файл
- 1Преимущество привязки функций к именам в локальных областях?
- 1Обработка пользовательских сообщений об ошибках в веб-API
- 0Открывать новую страницу, когда пользователь нажимает на любой элемент из ion-item
- 0Пользовательский интерфейс jQuery, сбрасываемый за пределы видимой области jScrollpane, ловит событие удаления
- 1SUM () в SQL для LINQ
- 1Как получить размер итератора без зацикливания?
- 1Где разместить SwingUtilities.invokeLater в отдельном Java-приложении с поддержкой Spring?
- 0MySQL генерирует годовые отчеты по месяцам с указанием имени персонала
- 1изменить цвета в styles.xml, которые установлены в colors.xml
- 0Поделиться постами на фейсбуке по идентификатору блога
- 1Не удается правильно прочитать словарь, сохраненный как файл json
- 0Написание подготовленных запросов MySQL с узла MySQL?
- 0Перестала работать горизонтальная линия через заголовок заголовка
- 1KnockoutJS - показать накопленную стоимость для каждого элемента
- 0Qt4.8 периодическая отправка нерегулярных данных
- 0Typeahead AngularStrap: слишком много вызовов $ http
- 1HTML5: воспроизведение потокового HTTP в домене HTTPS
- 0Как получить текстовое значение в HTML-форме? текстовое значение используется для перехода на следующую страницу
- 0Вложенный / Рекурсивный класс в C ++
- 0WAMP - phpMyAdmin
- 0MYSQL Присоединиться только к максимальной строке с данными из нескольких таблиц
- 1Как остановить приращение индекса, используя итерацию Array.map на основе определенных условий внутри цикла?
- 0как сравнить Auth :: user () -> id и user_id и выполнить команду if else в Laravel
- 0Выполнить код, когда отображается частичное представление
- 0двойной выход в Cout C ++
- 1подписка на изменения свойств в View throws ArgumentNullException
- 0MySQLIntegrityConstraintViolationException не показывает имена столбцов в сообщении об исключении
- 1Разбор строки данных: split против регулярного выражения
- 1Java BufferedReader FileReader проблема
- 0Открытие локального файла XML в Google Chrome
- 1BayazitDecomposer недоступен при обновлении с Farseer 3.3.1 до Farseer 3.5
- 0json_search выдает ошибку MySQL - # 2014 - команды не синхронизированы; Вы не можете запустить эту команду сейчас
- 0JQuery - слияние / несколько $ (это) My в той же функции
- 1Как использовать пользовательский исполнитель с помощью асинхронной аннотации
- 0CSS jQuery с функциями и свойствами
- 0Свернуть все последующие элементы до определенного тега
- 0получение функции из класса не работает
- 1Как изменить статус релиза продукта на альфа / бета приложение для Android в Google Play
- 1Получить информацию о поле Peoplepicker из другого списка в Sharepoint 2013
- 1Веб-формы .NET обновляют контент на стороне сервера

[всегда возвращать список означает, что вы получаете один и тот же выходной класс дляx[v]независимо от длиныv. Например, кто-то может захотетьlapplyнад подмножеством списка:lapply(x[v], fun). Если бы[отбросило бы список векторов длины один, это вернуло бы ошибку всякий раз, когдаvимеет длину один.