Генерация матрицы, содержащей все комбинации элементов, взятых из n векторов
Этот вопрос возникает довольно часто в той или иной форме (см. здесь здесь или здесь), Поэтому я решил представить его в общей форме и дать ответ, который может служить для справок в будущем.
Учитывая произвольное число
nвекторов, возможно, разных размеров, сгенерируйте матрицуn-column, строки которой описывают все комбинации элементов, взятых из этих векторов (декартово произведение).
Например,
vectors = { [1 2], [3 6 9], [10 20] }
должен давать
combs = [ 1 3 10
1 3 20
1 6 10
1 6 20
1 9 10
1 9 20
2 3 10
2 3 20
2 6 10
2 6 20
2 9 10
2 9 20 ]
-
0Эй, @bla, в последнее время ты избавляешься от некоторых представителей! :-)Luis Mendo
-
3Я решил запустить SO версию "The Giving Pledge", то есть 90% моего представителя возвращаются авторам, мне достаточно 2-3K ...bla
4 ответа
Функция ndgrid почти дает ответ, но имеет одно предостережение: n выходные переменные должны быть явно определены для вызова. Так как n произвольно, лучше всего использовать список, разделенный запятыми (сгенерированный из массива ячеек с ячейками n) для вывода. Полученные матрицы n затем объединяются в искомую матрицу n -column:
vectors = { [1 2], [3 6 9], [10 20] }; %// input data: cell array of vectors
n = numel(vectors); %// number of vectors
combs = cell(1,n); %// pre-define to generate comma-separated list
[combs{end:-1:1}] = ndgrid(vectors{end:-1:1}); %// the reverse order in these two
%// comma-separated lists is needed to produce the rows of the result matrix in
%// lexicographical order
combs = cat(n+1, combs{:}); %// concat the n n-dim arrays along dimension n+1
combs = reshape(combs,[],n); %// reshape to obtain desired matrix
-
2Это действительно хороший трюк. Это полезный способ обобщить декартово произведение на N измерений . Часть
cat(n+1,...)особенно умна. ;) -
0@chappjc Спасибо! В прошлом я использовал вызов
cellfunдля линеаризации n-dim массивов до их объединения, но да, мне это нравится больше
Немного проще... если у вас есть набор инструментов Neural Network, вы можете просто использовать combvec:
vectors = {[1 2], [3 6 9], [10 20]};
combs = combvec(vectors{:}).' % Use cells as arguments
который возвращает матрицу в несколько ином порядке:
combs =
1 3 10
2 3 10
1 6 10
2 6 10
1 9 10
2 9 10
1 3 20
2 3 20
1 6 20
2 6 20
1 9 20
2 9 20
Если вам нужна матрица, которая находится в вопросе, вы можете использовать sortrows:
combs = sortrows(combvec(vectors{:}).')
% Or equivalently as per @LuisMendo in the comments:
% combs = fliplr(combvec(vectors{end:-1:1}).')
который дает
combs =
1 3 10
1 3 20
1 6 10
1 6 20
1 9 10
1 9 20
2 3 10
2 3 20
2 6 10
2 6 20
2 9 10
2 9 20
Если вы посмотрите на внутренности combvec (введите edit combvec в командном окне), вы увидите, что он использует другой код, чем @LuisMendo. Я не могу сказать, что более эффективно в целом.
Если у вас есть матрица, строки которой сродни более раннему массиву ячеек, вы можете использовать:
vectors = [1 2;3 6;10 20];
vectors = num2cell(vectors,2);
combs = sortrows(combvec(vectors{:}).')
-
0Хорошее предложение. У меня нет этого в настоящее время, но это полезно знать.
-
2+1 Я не знал об этой функции. Жаль, что у меня нет этого набора инструментов. Может быть, вместо использования
sortrowsвы могли бы сэкономить время с помощьюcombs = fliplr(combvec(vectors{end:-1:1}).')?
Я провела сравнительный анализ двух предлагаемых решений. Код бенчмаркинга основан на timeit function и включен в конце этого сообщения.
Я рассматриваю два случая: три вектора размера n и три вектора размеров n/10, n и n*10 соответственно (оба случая дают одинаковое количество комбинаций). n изменяется до максимума 240 (я выбираю это значение, чтобы избежать использования виртуальной памяти на моем ноутбуке).
Результаты приведены на следующем рисунке. Видно, что решение на основе ndgrid занимает меньше времени, чем combvec. Интересно также отметить, что время, затрачиваемое на combvec, меняется в меньшей степени в разном случае.
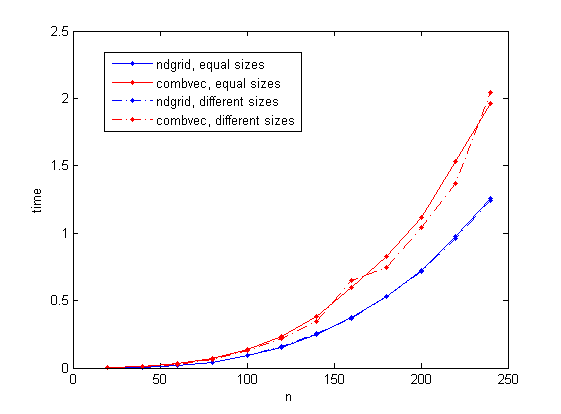
Код бенчмаркинга
Функция для решения ndgrid:
function combs = f1(vectors)
n = numel(vectors); %// number of vectors
combs = cell(1,n); %// pre-define to generate comma-separated list
[combs{end:-1:1}] = ndgrid(vectors{end:-1:1}); %// the reverse order in these two
%// comma-separated lists is needed to produce the rows of the result matrix in
%// lexicographical order
combs = cat(n+1, combs{:}); %// concat the n n-dim arrays along dimension n+1
combs = reshape(combs,[],n);
Функция для решения combvec:
function combs = f2(vectors)
combs = combvec(vectors{:}).';
Script, чтобы измерить время, вызвав timeit для этих функций:
nn = 20:20:240;
t1 = [];
t2 = [];
for n = nn;
%//vectors = {1:n, 1:n, 1:n};
vectors = {1:n/10, 1:n, 1:n*10};
t = timeit(@() f1(vectors));
t1 = [t1; t];
t = timeit(@() f2(vectors));
t2 = [t2; t];
end
-
2Я никогда не работал с Matlab, поэтому я не знаю, подходит ли мое решение в Java stackoverflow.com/a/10083452/312172 для mathlab. Он работает без генерации декартового произведения, но рассчитывает для каждого заданного индекса комбинацию элементов, заданную по этому индексу. Таким образом, его можно использовать там, где необходимо учитывать скорость и использование памяти. Это может быть принято долго или BigInteger, ну, по крайней мере, долго, я должен был это сделать. Один доступ всегда занимает немного времени, но для произвольного доступа в диапазоне миллиардов он все равно должен работать в постоянном времени. Может быть, вы заинтересованы.
Вот мой метод, который заставлял меня хихикать с восторгом, используя nchoosek, хотя он не лучше, чем @Luis Mendo принял решение.
В приведенном примере после 1000 запусков это решение заняло мою машину в среднем 0,00065935 с по сравнению с принятым решением 0,00012877 с. Для более крупных векторов, следующих за бенчмаркингом @Luis Mendo, это решение последовательно медленнее, чем принятый ответ. Тем не менее, я решил опубликовать его в надежде, что, может быть, вы найдете что-то полезное:
Код:
tic;
v = {[1 2], [3 6 9], [10 20]};
L = [0 cumsum(cellfun(@length,v))];
V = cell2mat(v);
J = nchoosek(1:L(end),length(v));
J(any(J>repmat(L(2:end),[size(J,1) 1]),2) | ...
any(J<=repmat(L(1:end-1),[size(J,1) 1]),2),:) = [];
V(J)
toc
дает
ans =
1 3 10
1 3 20
1 6 10
1 6 20
1 9 10
1 9 20
2 3 10
2 3 20
2 6 10
2 6 20
2 9 10
2 9 20
Elapsed time is 0.018434 seconds.
Объяснение:
L получает длину каждого вектора, используя cellfun. Хотя cellfun - это в основном цикл, он эффективен здесь, учитывая, что ваше число векторов должно быть относительно низким, чтобы эта проблема была даже практичной.
V объединяет все векторы для легкого доступа позже (это предполагает, что вы ввели все ваши векторы в виде строк. v 'будет работать для векторов столбцов.)
nchoosek получает все способы выбрать элементы n=length(v) из общего числа элементов L(end). Здесь будет больше комбинаций, чем то, что нам нужно.
J =
1 2 3
1 2 4
1 2 5
1 2 6
1 2 7
1 3 4
1 3 5
1 3 6
1 3 7
1 4 5
1 4 6
1 4 7
1 5 6
1 5 7
1 6 7
2 3 4
2 3 5
2 3 6
2 3 7
2 4 5
2 4 6
2 4 7
2 5 6
2 5 7
2 6 7
3 4 5
3 4 6
3 4 7
3 5 6
3 5 7
3 6 7
4 5 6
4 5 7
4 6 7
5 6 7
Так как в v(1) есть только два элемента, нам нужно выкинуть любые строки, где J(:,1)>2. Аналогично, где J(:,2)<3, J(:,2)>5 и т.д. Используя L и repmat, мы можем определить, находится ли каждый элемент J в соответствующем диапазоне, а затем используйте any для удаления строк, которые любой плохой элемент.
Наконец, это не фактические значения из V, а только индексы. V(J) вернет желаемую матрицу.
-
0Хорошо иметь другие способы решения проблемы! Просто мой обычный комментарий:
'не транспонировать;.'является -
0Спасибо Луис! Вы правы, но после второй мысли это выполнимо с v 'или v.' поскольку форма V в конечном итоге не имеет значения.
Ещё вопросы
- 0Загрузка данных перед загрузкой контроллеров и представлений
- 0«Нет результата» при попытке извлечь имена из базы данных
- 1Объясните о нисходящем и восходящем в rxJava
- 1Virtuoso Jena Provider Construct Query Error
- 0Удаление опций из Выбрать с помощью Jquery
- 1Python 3 добавляет элементы в список независимо от ключа, используемого в dict
- 0Расширение помощника Codeigniter
- 1Как сохранить изображение как varbinay в sql server 2008r2?
- 1Я объявил метод, но он показывает ошибку при вызове [closed]
- 1Как извлечь данные из CDATA в Python и BeautifulSoup?
- 0Доступ к объекту внутри массива, который находится внутри другого объекта, используя PHP
- 0Ошибка java-скрипта при перемещении ссылок jquery на главную страницу asp.net
- 0UDP-сообщения продолжают поступать даже после остановки клиента или перезапуска сервера
- 0Добавление в MySQL из формы Materialise
- 1Удаление класса из всех изображений с помощью JavaScript без использования jQuery
- 0Невозможно создать / удалить файл / папку в Linux Fedora при получении вызова с php-сервера
- 0Сокращенный способ проверки следующего элемента массива со строковыми индексами
- 0Какую часть CSS нужно изменить, чтобы это работало, т.е.
- 1Как разделить длинную сопрограмму без использования await?
- 1Код синхронизации для Promise All [дубликаты]
- 1Что касается неизменяемой коллекции
- 1Передача никогда не выполняется при остановке приложения
- 0Назначение значения?
- 0Вложенная функция C ++ с указателем в качестве возвращаемого значения
- 1После перевода реселлервью перестает слушать сенсорные события
- 0Passport JS auth middleware проблема
- 1как получить заказы из компонента ordertools в atg или как протестировать apl orderlookup droplet
- 1Преобразование миллисекунд в объект даты UTC с часовым поясом UTC
- 0Должен ли я использовать внешний ключ пользователя для всех таблиц?
- 1Локализация MVC4 с DisplayName в базе данных
- 0Как получить preg_replace () для удаления текста между двумя тегами?
- 1Android - Как изменить размеры только определенных видов при изменении видимости клавиатуры
- 0AngularJS объем этого в фабрике
- 0Обновите родительскую область из директивы Child
- 0Выпадающее меню CSS3 при наведении на размер
- 1Как заменить прозрачный цвет в подушку
- 0Есть ли разница между этими условными присваиваниями, которые обрабатывают значения по умолчанию?
- 1Java - проблемы с подстрокой
- 1HashMaps достаточно быстро?
- 1Grails не кодирует в UTF-8 после публикации тела с помощью contentType application / json
- 0Угловой выбор помнить при перемещении по представлениям
- 1Невозможно получить какой-либо ответ от API (залп)
- 0изменить скорость animate (), пока она анимируется, и наводить курсор на элемент
- 1Отображать изображения в сетке
- 1Android: отображение неверной даты окончания (за день до фактической даты) в Календаре Google при добавлении события с намерением
- 1Pythonic способ перебирать списки внутри dict параллельно как dict
- 1Запрос OrderByChild, equalTo и limitToFirst загружает всю базу данных
- 0php pdo fetchAll возвращает ошибку SQL «нет активных полей» при выполнении хранимой процедуры
- 1Выбор массива, чтобы стать свойствами объекта
- 0Как получить значение из запроса MySQL вне оператора запроса?
