Мне действительно нужно кодировать '&' как '& amp;'?
Я использую символ < & с HTML5 и UTF-8 на моем сайте <title>. Google показывает амперсанд в своих выдаче, как и все браузеры в своих названиях.
http://validator.w3.org дает мне следующее:
& не начиналась символьная ссылка. (& вероятно, должно было быть экранировано как
&.)
Нужно ли мне делать &?
Я не суетился о том, что мои страницы проверяются ради проверки, но мне любопытно слышать мнения людей по этому поводу, и если это важно и почему.
-
62Спецификации не говорят так. Постер ссылается на HTML5, который не требует выхода из амперсанда во всех сценариях.Matthew Wilson
-
2Это должна быть Вики Сообщества, так как вы ищете мнения, а отсутствие суеты по поводу проверки подразумевает, что нет объективных оснований для ответа.Richard JP Le Guen
17 ответов
Да. Так же, как и ошибка, в HTML атрибуты #PCDATA означают, что они разбираются. Это означает, что вы можете использовать символьные сущности в атрибутах. Использование & само по себе неверно, и если не для мягких браузеров и того факта, что это HTML не XHTML, это нарушит разбор. Просто избегайте его как &, и все будет хорошо.
HTML5 позволяет оставить его неэкранированным, но только тогда, когда последующие данные не выглядят как действительная символьная ссылка. Однако лучше избегать всех экземпляров этого символа, чем беспокоиться о том, какие из них должны быть, а какие не нужны.
Помните об этом; если вы не ускользаете, а к & amp;, это достаточно плохо для создаваемых вами данных (где код может быть очень недействительным), вы также не можете избежать разделителей тегов, что является огромной проблемой для пользовательских данные, которые вполне могут привести к HTML и script инъекциям, хищению файлов cookie и другим эксплойтам.
Пожалуйста, просто избегайте кода. Это сэкономит вам массу неприятностей в будущем.
-
9Ни один браузер никогда не будет «неверно истолковывать» a &. Каждый существующий браузер отображает его как «&». Принимая во внимание, что он явно попросил практическую причину сделать это, и что он заявил, что его не волнует проверка ...
-
44Да. Но морально, мы должны полагаться на снисходительность и "хорошую" обработку ошибок браузеров? Или мы должны просто написать правильный код?
Валидация в стороне, факт остается фактом: кодирование определенных символов важно для HTML-документа, чтобы он мог корректно и безопасно отображать веб-страницу.
Кодирование & как & при любых обстоятельствах, для меня - это более легкое правило жить, уменьшая вероятность ошибок и сбоев.
Сравните следующее: что проще? который легче взломать?
Методология 1
- Напишите некоторый контент, содержащий символы амперсанда.
- Кодировать их все.
Методология 2
(с зерном соли, пожалуйста;))
- Напишите некоторый контент, который включает символы амперсанда.
- В каждом конкретном случае просмотрите каждый амперсанд. Определите, если:
- Он изолирован и как таковой однозначно амперсанд. например.
volt & amp
> В этом случае не надо его кодировать. - Он не изолирован, но вы чувствуете, что он тем не менее однозначен, поскольку результирующий объект не существует и никогда не будет существовать, поскольку список сущностей никогда не может эволюционировать. например
amp&volt
> В этом случае не беспокойтесь, кодируя его. - Он не изолирован и неоднозначен. например.
volt&
> Кодировать его.
- Он изолирован и как таковой однозначно амперсанд. например.
??
-
3Второй случай
amp&voltнеоднозначен: Является ли&voltтеперь ссылка на сущность или нет? -
6@Gumbo Амперсанд в
amp&voltне является неоднозначным амперсандом (согласно определению в спецификации HTML). См. Mathiasbynens.be/notes/ambiguous-ampersands и mothereff.in/ampersands#amp%26volt .
Ive тщательно изучил это и написал о моих выводах здесь: http://mathiasbynens.be/notes/ambiguous-ampersands
Ive также создал онлайн-инструмент, который вы можете использовать для проверки вашей разметки для двусмысленных амперсандов или ссылок на символы, которые не заканчиваются точкой с запятой, как из которых недействительны. (В настоящее время HTML-валидатор делает это правильно.)
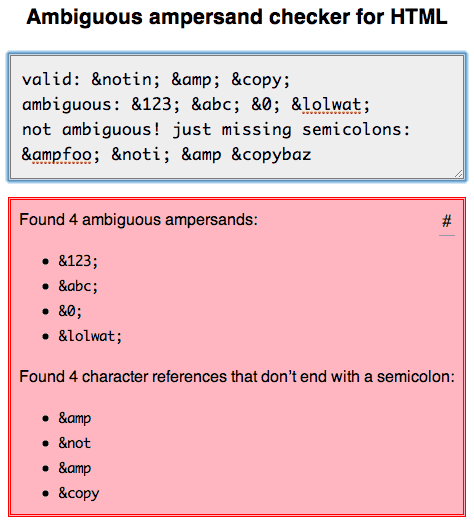
-
0Могу ли я просто предложить поместить приведенные здесь примеры в инструмент вместо текущего текста по умолчанию, что просто сбивает с толку и неясно?
-
0@Kzwai Какие примеры? ОП не указал.
Правила HTML5 отличаются от HTML4. Это не требуется в HTML5 - если амперсанд не выглядит так, как он запускает имя параметра. "& copy = 2" по-прежнему является проблемой, например, поскольку & copy; является символом авторского права.
Однако мне кажется, что труднее решить, чтобы кодировать или не кодировать в зависимости от следующего текста. Поэтому самый простой путь - это, вероятно, все время кодировать.
-
2Это похоже на цитирование значений атрибутов - вам не нужно, но вы не ошибетесь, если будете делать это все время.
-
3
©=2не такая большая проблема, как вы думаете. В значениях атрибута (например, атрибутеhref) символ©не будет рассматриваться как символьная ссылка для©. Вне значения атрибута это было бы.
Я думаю, что это превратилось в вопрос "зачем следовать спецификации, когда браузеру все равно". Вот мой обобщенный ответ:
Стандарты не являются "настоящими" вещь. Они являются "будущими". вещь. Если мы, разработчики, следуем веб-стандартам, то поставщики браузеров с большей вероятностью правильно реализуют эти стандарты, и мы приближаемся к полностью интероперабельному веб-сайту, где CSS-хаки, обнаружение функций и обнаружение браузера не нужны. Где нам не нужно выяснять, почему наши макеты разбиваются в определенном браузере или как обойти это.
В частности, если HTML5 не требует использования & в вашей конкретной ситуации, и вы используете доктрину HTML5 (а также ожидаете, что ваши пользователи будут использовать HTML5-совместимые браузеры), тогда нет причин для этого.
-
1При этом, в общем, вы должны помнить, что большинство «стандартных» способов все еще находятся в черновом режиме и могут измениться в будущем.
Не могли бы вы показать нам, что ваш title на самом деле? Когда я отправляю
<!DOCTYPE html>
<html>
<title>Dolce & Gabbana</title>
<body>
<p>am i allowed loose & mpersands?</p>
</body>
</html>
to http://validator.w3.org/ - , в котором явным образом просил использовать экспериментальный режим HTML 5 - он не жалуется на & s...
-
0Да, HTML5 имеет другой синтаксический анализатор, чем предыдущие анализаторы HTML и XHTML, и в определенных ситуациях допускает использование неэкранированных амперсандов.
-
0Что касается этих примеров, в HTML5 нет ничего нового.
<title>Dolce & Gabbana</title>и<p>Dolce & Gabbana</p>являются действительными HTML 2.0.
Ну, если это исходит от пользовательского ввода, то абсолютно да, по понятным причинам. Подумайте, не сделал ли этот сам сайт: название этого вопроса будет отображаться как , мне действительно нужно кодировать '& как '&?
Если это просто что-то вроде echo '<title>Dolce & Gabbana</title>';, то, строго говоря, вам это не нужно. Было бы лучше, но если вы этого не сделаете, пользователь не заметит разницы.
В HTML a & отмечается начало ссылки, любая из ссылок или ссылка на сущность. С этой точки анализатор ожидает либо a #, обозначающего ссылку на символ, либо имя объекта, обозначающее ссылку на сущность, с последующим знаком ;. Это нормальное поведение.
Но если вместо ссылочного имени или только эталонного открытия & следует пробел или другие разделители, такие как ", ', <, >, &, окончание ; и даже ссылка для представления простой & может быть опущена:
<p title="&">foo & bar</p>
<p title="&">foo & bar</p>
<p title="&">foo & bar</p>
Только в этих случаях конец ; или даже сама ссылка может быть опущена (по крайней мере, в HTML 4). Я думаю, что HTML 5 требует окончания ;.
Но спецификация рекомендует всегда использовать ссылку, например ссылку на символ & или ссылку на объект &, чтобы избежать путаницы:
Авторы должны использовать "
&" (ASCII decimal 38) вместо "&", чтобы избежать путаницы с началом ссылки на символ (ограничитель ссылки на сущность). Авторы также должны использовать "&" в значениях атрибутов, так как символьные ссылки разрешены в значениях атрибута CDATA.
-
1Это спецификация HTML 4, на которую вы ссылаетесь; из моего прочтения (черновой) спецификации HTML 5 запрещены только неоднозначные амперсанды. Например, амперсанд, за которым следует пробел, не является двусмысленным, и поэтому (опять же по моим прочтениям) должен быть разрешен - см. Мой ответ для разметки, который принимает валидатор HTML 5.
-
0@AakashM: Я что-то сказал не так?
Я проверял, почему URL-адрес изображения нужно экранировать, поэтому попробовал его в https://validator.w3.org. Объяснение довольно приятно. Он подчеркивает, что даже URL-адрес должен быть экранирован. [PS: Я предполагаю, что это не будет отменено, когда его потребляемый с URL-адреса нужно &. Может кто-нибудь уточнить?]
<img alt="" src="foo?bar=qut&qux=fop" />
Ссылка на объект была найдена в документе, но нет ссылка на это имя определена. Часто это вызвано ошибкой имя ссылки, неуказанные амперсанды или конечная точка с запятой (;). Наиболее распространенной причиной этой ошибки является unencoded ampersands в URL-адресах, как описано в WDG в "Амперсандах в URL-адреса". Ссылки на объекты начинаются с амперсанда (&) и заканчиваются точка с запятой (;). Если вы хотите использовать буквальный амперсанд в своем документе вы должны закодировать его как "&" (даже внутри URL!). Будьте осторожны, чтобы закончить ссылки на объекты с точкой с запятой или ссылкой на вашу сущность могут интерпретируется в связи со следующим текстом. Также имейте в виду что ссылки на именованные сущности зависят от регистра; & Aelig; и & aelig; это разные персонажи. Если эта ошибка появляется в некоторой разметке сгенерированный кодом обработки сеанса PHP, эта статья имеет объяснения и решения вашей проблемы.
-
1Прочитайте ответ с наибольшим количеством голосов. Атрибуты #PCDATA и, следовательно, анализируются. Объекты обрабатываются там. В вашем примере
&запускает ссылку на сущность. После прочтения&quxсинтаксический анализатор не находит окончательной точки с запятой (;), но наталкивается на знак равенства (=), который не может быть частью имени объекта. Это должно быть ошибкой синтаксического анализа, если анализатор пытался быть очень строгим (согласно HTML 4). В HTML 5 разбор сущностей в целом более упрощен. -
0Я подозреваю, что в целом это лучше всего использовать
;по этой причине в качестве разделителя в строках запроса (когда вы управляете ссылкой).
Пару лет назад мы получили сообщение о том, что одно из наших веб-приложений неправильно отображалось в Firefox. Оказалось, что страница содержала тег, который выглядел как
<div style="..." ... style="...">
Когда вы сталкиваетесь с атрибутом повторяющегося стиля, IE объединяет оба стиля, в то время как Firefox использует только один из них, отсюда и другое поведение. Я изменил тег на
<div style="...; ..." ...>
и, конечно же, он исправил проблему! Мораль этой истории заключается в том, что браузеры имеют более последовательную обработку допустимого HTML, чем недействительный HTML. Итак, исправьте свою проклятую разметку! (Или используйте HTML Tidy, чтобы исправить его.)
Если пользователь передает его вам или он закроется в URL-адресе, вам нужно его избежать.
Если он отображается в статическом тексте на странице? Все браузеры получат это право в любом случае, вы не сильно беспокоитесь об этом, так как он будет работать.
Да, вы должны попытаться использовать действительный код, если это возможно.
Большинство браузеров будут тихо исправлять эту ошибку, но есть проблема с использованием обработки ошибок в браузерах. Существует не стандарт для обработки неправильного кода, поэтому каждый поставщик браузера пытается выяснить, что делать с каждой ошибкой, и результаты могут отличаться.
Некоторые примеры, когда браузеры могут реагировать по-разному, - это если вы помещаете элементы внутри таблицы, но вне ячеек таблицы, или если вы вставляете ссылки друг в друга.
В вашем конкретном примере это вряд ли вызовет какие-либо проблемы, но, возможно, исправление ошибок в браузере может привести к тому, что браузер изменится со стандартного режима совместимости на режим quirks, что может полностью раскрыть ваш макет.
Итак, вы должны исправить ошибки, подобные этому в коде, если не для чего-либо еще, чтобы сохранить список ошибок в валидаторе коротким, чтобы вы могли выявить более серьезные проблемы.
Не уверен, что это полезно для всех... Я боролся с этим некоторое время... вот славное регулярное выражение, которое вы можете использовать, чтобы исправить все ваши ссылки, javascript, контент. Мне пришлось иметь дело с тонной частью старого контента, который никто не хотел исправлять.
Добавьте это к вашему переопределению Render на главной странице или в панели управления:
Пожалуйста, не плачьте меня, чтобы поместить это в неправильное место:
// remove the & from href="blaw?a=b&b=c" and replace with &
//in urls - this corrects any unencoded & not just those in URL's
// this match will also ignore any matches it finds within <script> blocks AND
// it will also ignore the matches where the link includes a javascript command like
// <a href="javascript:alert{'& & &'}">blaw</a>
html = Regex.Replace(html, "&(?!(?<=(?<outerquote>[\"'])javascript:(?>(?!\\k<outerquote>|[>]).)*)\\k<outerquote>?)(?!(?:[a-zA-Z][a-zA-Z0-9]*|#\\d+);)(?!(?>(?:(?!<script|\\/script>).)*)\\/script>)", "&", RegexOptions.Singleline | RegexOptions.IgnoreCase);
Если & используется в html, вам следует избегать его
Если & используется в строках javascript, например. a alert('This & that'); или document.href вам не нужно использовать его.
Если вы используете document.write, вы должны использовать его, например. document.write(<p>this & that</p>)
-
0
document.writeследует избегать. Смотрите окно с предупреждением в w3.org/html/wg/drafts/html/master/dom.html#document.write%28%29 -
0Хороший вопрос о
document.write(). Но главное, что Алекс делает для записи в документ со сценариев, IMO. +1
Это зависит от вероятности того, что точка с запятой заканчивается рядом с вашим &, в результате чего она будет отображать что-то совсем другое.
Например, когда вы имеете дело с данными от пользователей (например, если вы включаете тему заголовка форума в теги заголовка), вы никогда не знаете, где они могут помещать случайные точки с запятой, и это может случайно отображать странные юридические лица. Поэтому всегда избегайте в этой ситуации.
Для вашего собственного статического html, конечно, вы можете пропустить его, но это так тривиально, чтобы включить правильное экранирование, чтобы не было никаких оснований его избегать.
Если, вы действительно говорите о статическом тексте
<title>Foo & Bar</title>
хранится в каком-либо файле на жестком диске и обслуживается непосредственно сервером, а затем да. Вероятно, его не нужно экранировать.
Однако, поскольку в настоящее время очень мало содержимого HTML, которое полностью статично, я добавлю следующий отказ от ответственности, предполагающий, что содержимое HTML создается из какого-то другого источника (содержимое базы данных, пользовательский ввод, результат вызова веб-службы, устаревший API результат,...):
Если вы не избежите простого &, то, скорее всего, вы также не избежите & или или <b> или <script src="http://attacker.com/evil.js"> или любого другого недействительного текста. Это означает, что вы в лучшем случае неправильно отображаете свой контент и, скорее всего, подозреваете атаки XSS.
Другими словами: когда вы уже проверяете и избегаете других более проблемных случаев, тогда почти нет причин оставлять не полностью-сломанный, но все же несколько-одичалый автономный & неэкранированный.
-
0@Downvoter: хотите прокомментировать?
-
2Я не понизил голос, но, если бы мне пришлось угадывать, я бы сказал, что за вас проголосовали, потому что ваш ответ (хотя и умный) немного не соответствует вопросу. Он не спрашивает о том, чтобы избежать пользовательского ввода. Он контролирует персонажей и в основном спрашивает: «Если он делает то, что я хочу, действительно ли важно следовать спецификации языка к букве?» То есть он знает, что есть &, потому что он вставил его.
В ссылке есть довольно хороший пример того, когда и почему вам может понадобиться избежать & до &
https://jsfiddle.net/vh2h7usk/1/
Интересно, что мне пришлось скрыться от персонажа, чтобы правильно представить его в моем ответе. Если бы я использовал встроенный образец кода (из панели ответов), я могу просто ввести & и он появится как следует. Но если бы мне пришлось вручную использовать элемент <code></code>, тогда мне нужно убежать, чтобы правильно его представить:)
Ещё вопросы
- 0Разбор HTML от определенной начальной точки до определенной конечной точки?
- 1Получить дамп потока в браузере JS?
- 0Как отобразить многоуровневое дерево отношений один ко многим
- 1nodejs - дождитесь завершения fs.stat
- 0ionic не удалось загрузить веб-страницу с ошибкой: операция не может быть завершена. (NSURLErrorDomain ошибка -999.)
- 1Как читать PDF-файлы на азиатских языках (китайский, японский, тайский и т. Д.) И хранить их в виде строки в python
- 1Проблемы сортировки слиянием
- 1Idaeablade PassthruEsqlQuery возвращает пустой список
- 0Ajax In QueryMethod Вызов в классическом Asp для отправки электронной почты
- 0Как мне очистить эти вложенные циклы?
- 0Удалить отступ между вкладкой 2 jquery
- 1Как удалить последнюю строку в сетке с помощью WPF?
- 1Использование itertools для условия с перечислением для получения только определенных индексов списка (python)
- 1Таймер Java не работает. Вызов нескольких таймеров одновременно
- 1Создание метода равных
- 0Выборка площади против выборки BRDF при рендеринге
- 1Автоматическое изменение размера окна tkinter, чтобы соответствовать всем виджетам
- 0У меня есть повторяющееся фоновое квадратное изображение размером 89x89 пикселей, которое я хотел бы изменить на изображение произвольного цвета, когда мышь зависает
- 1вставить новый экземпляр, используя API GCE
- 1Валюта Formatter не является дружественным к пользователю / интуитивно понятным. Случайно увеличивает поле ввода
- 1MediaRouteButton не активен во фрагменте
- 1Как установить переменную среды PYTHONUTF8 для включения кодировки UTF-8 по умолчанию в Python?
- 0Как наследовать класс A от B при наследовании B от A?
- 0Вызов функции-члена assign () для необъекта в smarty
- 0Как мне предложить пользователю ввести символ или цифру?
- 0jQuery blueimp fileup загрузить Firefox / Opera расчетов проблема, хром в порядке
- 0Можно ли с помощью jQuery «перехватить» два действия?
- 0неверный JSON при использовании Pivotal API?
- 0Прекращение загрузки файла Symfony2 с сервера Apache
- 1Как сделать np.where более эффективным с помощью треугольных матриц?
- 0Как добавить элемент в div в angularjs?
- 1Как конвертировать дату в метку времени
- 1JAXP - поиск в каталоге отладки XSD
- 0GCC не разрешается автоматически .cpp из класса .h include
- 0Вычеркнуть несколько текстов в опции выбора
- 1Загрузка запрещена с помощью X-Frame-Options: websitename / Register не разрешает кадрирование между источниками в MVC5
- 1Как нормализовать цвета, приобретая один цвет?
- 1время выполнения программы на питоне
- 1Передача более одного значения из списка DropDown
- 0Угловой фильтр на объекте json
- 1Как остановить службу переднего плана перед вызовом метода startForeground ()?
- 1Как поставить задержку для функции в JavaScript? [Дубликат]
- 0HTML данные таблицы в JSON и отправить его контроллер Mvc в список
- 0Пользовательский ввод для фильтрации строк таблицы
- 1RxJS запускает функцию выбора только один раз
- 0Угловой дизайн материала md-autocomplete с md-max-length и рисунком
- 1Python - ускорить итерацию панд
- 1Захват изображений со смешанными изображениями в Nokia Imaging SDK
- 0Методы событий плагина в Virtuemart для статуса заказа
- 1Javascript Self-вызванные функции
