Функции группировки (tapply, by, aggregate) и семейство * apply
Всякий раз, когда я хочу сделать что-то "map" py в R, я обычно пытаюсь использовать функцию в семействе apply.
Однако я никогда не понимал различий между ними: как { sapply, lapply и т.д.} применяют эту функцию к входному/сгруппированному входу, как будет выглядеть вывод, или даже то, что вход может быть - поэтому я часто просто просматриваю их все, пока не получу то, что хочу.
Может кто-нибудь объяснить, как использовать тот, когда?
Мое текущее (возможно неправильное/неполное) понимание...
-
sapply(vec, f): input - это вектор. output - вектор/матрица, где элементiравенf(vec[i]), давая вам матрицу, еслиfимеет многоэлементный вывод -
lapply(vec, f): то же, что иsapply, но вывод - это список? -
apply(matrix, 1/2, f): input - это матрица. output - это вектор, где элементiравен f (строка/col я матрицы) -
tapply(vector, grouping, f): output - это матрица/массив, где элемент в матрице/массиве является значениемfпри группировкеgвектора, аgпопадает в строку /col имена -
by(dataframe, grouping, f): пустьg- группировка. применитеfк каждому столбцу группы /dataframe. достаточно напечатать группировку и значениеfв каждом столбце. -
aggregate(matrix, grouping, f): похоже наby, но вместо того, чтобы печатать вывод, агрегат вставляет все в кадр данных.
Боковой вопрос: я до сих пор не узнал plyr или не изменил форму - plyr или reshape полностью заменить все это?
9 ответов
R имеет множество * применяемых функций, которые хорошо описаны в файлах справки (например, ?apply). Однако их достаточно, что для начала использования Rs может возникнуть трудность в определении того, какой из них подходит для их ситуации или даже помнит их все. У них может быть общее мнение, что "я должен использовать функцию приложения * здесь", но сначала может быть сложно сохранить их все прямо.
Несмотря на то, что (в других ответах) большая часть функциональности семейства * apply распространяется на чрезвычайно популярный пакет plyr, базовые функции остаются полезными и заслуживают внимания.
Этот ответ предназначен для использования в качестве своего рода знака для новых useRs, чтобы помочь направить их на правильную * применимую функцию для их конкретной проблемы. Обратите внимание, что это не, предназначенное для простого опрокидывания или замены документации R! Надежда состоит в том, что этот ответ поможет вам решить, какая функция * подходит для вашей ситуации, и тогда вам решать ее дальше. За одним исключением различия производительности не будут устранены.
-
применить. Если вы хотите применить функцию к строкам или столбцам матрицы (и многомерных аналогов); обычно не рекомендуется для фреймов данных, поскольку он сначала будет принуждать к матрице.
# Two dimensional matrix M <- matrix(seq(1,16), 4, 4) # apply min to rows apply(M, 1, min) [1] 1 2 3 4 # apply max to columns apply(M, 2, max) [1] 4 8 12 16 # 3 dimensional array M <- array( seq(32), dim = c(4,4,2)) # Apply sum across each M[*, , ] - i.e Sum across 2nd and 3rd dimension apply(M, 1, sum) # Result is one-dimensional [1] 120 128 136 144 # Apply sum across each M[*, *, ] - i.e Sum across 3rd dimension apply(M, c(1,2), sum) # Result is two-dimensional [,1] [,2] [,3] [,4] [1,] 18 26 34 42 [2,] 20 28 36 44 [3,] 22 30 38 46 [4,] 24 32 40 48Если вы хотите использовать значения строк или столбцов для двумерной матрицы, убедитесь, что исследовать высокооптимизированный, молниеносный
colMeans,rowMeans,colSums,rowSums. -
lapply. Если вы хотите применить функцию к каждому элементу список в свою очередь и получить список назад.
Это рабочая лошадка многих других * применимых функций. корка верните их код, и вы часто найдете под ним
lapply.x <- list(a = 1, b = 1:3, c = 10:100) lapply(x, FUN = length) $a [1] 1 $b [1] 3 $c [1] 91 lapply(x, FUN = sum) $a [1] 1 $b [1] 6 $c [1] 5005 -
sapply. Если вы хотите применить функцию к каждому элементу в свою очередь, но вам нужен вектор, а не список.
Если вы набрали
unlist(lapply(...)), остановитесь и рассмотритеsapply.x <- list(a = 1, b = 1:3, c = 10:100) # Compare with above; a named vector, not a list sapply(x, FUN = length) a b c 1 3 91 sapply(x, FUN = sum) a b c 1 6 5005В более сложных целях использования
sapplyон попытается принудить результат в многомерном массиве, если это необходимо. Например, если наша функция возвращает векторы одинаковой длины,sapplyбудет использовать их в качестве столбцов матрицы:sapply(1:5,function(x) rnorm(3,x))Если наша функция возвращает 2-мерную матрицу,
sapplyбудет делать по существу одно и то же, рассматривая каждую возвращаемую матрицу как один длинный вектор:sapply(1:5,function(x) matrix(x,2,2))Если мы не укажем
simplify = "array", в этом случае он будет использовать отдельные матрицы для построения многомерного массива:sapply(1:5,function(x) matrix(x,2,2), simplify = "array")Каждое из этих поведений, конечно, зависит от нашей функции, возвращающей векторы или матрицы одинаковой длины или размера.
-
vapply. Если вы хотите использовать
sapply, но, возможно, вам понадобится сжимайте еще немного скорости из вашего кода.Для
vapplyвы в основном даете R пример того, что ваша функция вернется, что может сэкономить некоторое время, вызванное возвратом значения для одного атомного вектора.x <- list(a = 1, b = 1:3, c = 10:100) #Note that since the advantage here is mainly speed, this # example is only for illustration. We're telling R that # everything returned by length() should be an integer of # length 1. vapply(x, FUN = length, FUN.VALUE = 0L) a b c 1 3 91 -
mapply. Если у вас несколько структур данных (например, векторы, списки), и вы хотите применить функцию к 1-му элементам каждого, а затем 2-го элемента каждого и т.д., приводя к результату к вектору/массиву, как в
sapply.Это многомерность в том смысле, что ваша функция должна принимать несколько аргументов.
#Sums the 1st elements, the 2nd elements, etc. mapply(sum, 1:5, 1:5, 1:5) [1] 3 6 9 12 15 #To do rep(1,4), rep(2,3), etc. mapply(rep, 1:4, 4:1) [[1]] [1] 1 1 1 1 [[2]] [1] 2 2 2 [[3]] [1] 3 3 [[4]] [1] 4 -
Карта. Оболочка
mapplyсSIMPLIFY = FALSE, поэтому гарантированно вернет список.Map(sum, 1:5, 1:5, 1:5) [[1]] [1] 3 [[2]] [1] 6 [[3]] [1] 9 [[4]] [1] 12 [[5]] [1] 15 -
rapply. Если вы хотите применить функцию к каждому элементу структуры вложенного списка, рекурсивно.
Чтобы дать вам некоторое представление о том, насколько необычен
rapply, я забыл об этом при первом отправке этого ответа! Очевидно, я уверен, что многие используют его, но YMMV.rapplyлучше всего иллюстрируется пользовательской функцией:# Append ! to string, otherwise increment myFun <- function(x){ if(is.character(x)){ return(paste(x,"!",sep="")) } else{ return(x + 1) } } #A nested list structure l <- list(a = list(a1 = "Boo", b1 = 2, c1 = "Eeek"), b = 3, c = "Yikes", d = list(a2 = 1, b2 = list(a3 = "Hey", b3 = 5))) # Result is named vector, coerced to character rapply(l, myFun) # Result is a nested list like l, with values altered rapply(l, myFun, how="replace") -
tapply. Если вы хотите применить функцию к подмножествам вектор и подмножества определяются каким-либо другим вектором, обычно фактор.
Черная овца * применяет семейство. Использование файла справки фраза "оборванный массив" может быть немного запутанной, но на самом деле довольно просто.
Вектор:
x <- 1:20Коэффициент (той же длины!), определяющий группы:
y <- factor(rep(letters[1:5], each = 4))Добавьте значения в
xв пределах каждой подгруппы, определеннойy:tapply(x, y, sum) a b c d e 10 26 42 58 74Более сложные примеры можно обрабатывать там, где определены подгруппы уникальными комбинациями списка из нескольких факторов.
tapplyявляется аналогичные по духу функциям split-apply-comb, которые общий в R (aggregate,by,ave,ddplyи т.д.). Следовательно, его черный овец.
-
29Поверьте, вы обнаружите, что
byявляется чисто расщепленным, аaggregate-tapply. Я думаю, что черная овца делает отличную ткань. -
17Фантастический ответ! Это должно быть частью официальной документации R :). Одно крошечное предложение: возможно, добавить несколько маркеров при использовании
aggregatebyа также? (Я, наконец, понимаю их после вашего описания!, Но они довольно распространены, поэтому может быть полезно выделить и привести несколько конкретных примеров для этих двух функций.)
С другой стороны, вот как различные функции plyr соответствуют базовым функциям *apply (от ввода к документу plyr с веб-страницы plyr http://had.co.nz/plyr/)
Base function Input Output plyr function
---------------------------------------
aggregate d d ddply + colwise
apply a a/l aaply / alply
by d l dlply
lapply l l llply
mapply a a/l maply / mlply
replicate r a/l raply / rlply
sapply l a laply
Одной из целей plyr является предоставление согласованных соглашений об именах для каждой из функций, кодирующих типы входных и выходных данных в имени функции. Он также обеспечивает согласованность вывода, поскольку вывод из dlply() легко проходит к ldply() для получения полезного вывода и т.д.
Концептуально, обучение plyr не более сложно, чем понимание базовых функций *apply.
plyr и reshape заменили почти все эти функции в моем ежедневном использовании. Но, также из документа Intro to Plyr:
Связанные функции
tapplyиsweepне имеют соответствующей функции вplyrи остаются полезными.mergeполезен для комбинирования сумм с исходными данными.
-
13Когда я начал изучать R с нуля, я обнаружил, что plyr НАМНОГО легче освоить, чем семейство функций
*apply(). Для меняddply()был очень интуитивным, так как я был знаком с функциями агрегации SQL.ddply()стал моим молотком для решения многих проблем, некоторые из которых могли бы быть лучше решены с помощью других команд. -
1Полагаю, я понял, что концепция функций
plyrпохожа на*applyфункции, поэтому, если вы можете сделать одну, вы можете сделать другую, но функцииplyrлегче запомнить. Но я полностью согласен сddply()!
Из слайда 21 http://www.slideshare.net/hadley/plyr-one-data-analytic-strategy:
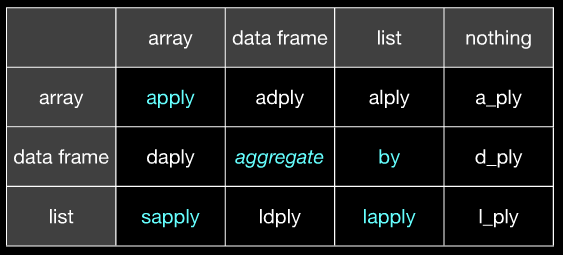
(Надеюсь, ясно, что apply соответствует @Hadley aaply и aggregate соответствует @Hadley ddply и т.д. Слайд 20 из того же слайд-шоу прояснит, не получите ли вы его от этого изображения. )
(слева находится вход, сверху отображается)
-
3на слайде есть опечатка? Верхняя левая ячейка должна быть
Сначала начните с Joran отличный ответ - сомнительно, что что-то может улучшить это.
Тогда следующие мнемоники могут помочь запомнить различия между ними. В то время как некоторые из них очевидны, другие могут быть менее такими - для них вы найдете оправдание в обсуждениях Джорана.
Мнемоник
-
lapply- это список, который действует в списке или векторе и возвращает список. -
sapply- это простойlapply(функция по умолчанию возвращает вектор или матрицу, когда это возможно) -
vapply- это проверенное применение (позволяет задавать тип возвращаемого объекта) -
rapply- это рекурсивное применение для вложенных списков, т.е. списков в списках -
tapplyприменяется с тегами, где теги идентифицируют подмножества -
applyявляется общим: применяет функцию к матричным строкам или столбцам (или, более общо, к размерам массива)
Создание правильного фона
Если использование семейства apply все еще немного чуждо вам, возможно, вам не хватает ключевой точки зрения.
Эти две статьи могут помочь. Они обеспечивают необходимый фон для мотивации методов функционального программирования, предоставляемых семейством функций apply.
Пользователи Lisp сразу узнают парадигму. Если вы не знакомы с Lisp, как только вы пойдете вокруг FP, вы приобретете мощную точку зрения для использования в R - и apply, что будет иметь больший смысл.
- Advanced R: функциональное программирование, Hadley Wickham
- Простое функциональное программирование в R, Michael Barton
Так как я понял, что (очень превосходные) ответы на этот пост недостаток by и aggregate объяснений. Вот мой вклад.
ПО
Функция by, как указано в документации, может быть, однако, как "обертка" для tapply. Сила by возникает, когда мы хотим вычислить задачу, которую tapply не может обрабатывать. Одним из примеров является этот код:
ct <- tapply(iris$Sepal.Width , iris$Species , summary )
cb <- by(iris$Sepal.Width , iris$Species , summary )
cb
iris$Species: setosa
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.300 3.200 3.400 3.428 3.675 4.400
--------------------------------------------------------------
iris$Species: versicolor
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.000 2.525 2.800 2.770 3.000 3.400
--------------------------------------------------------------
iris$Species: virginica
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.200 2.800 3.000 2.974 3.175 3.800
ct
$setosa
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.300 3.200 3.400 3.428 3.675 4.400
$versicolor
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.000 2.525 2.800 2.770 3.000 3.400
$virginica
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.200 2.800 3.000 2.974 3.175 3.800
Если мы напечатаем эти два объекта ct и cb, мы "по существу" получим те же результаты, и единственные различия в том, как они показаны, и разные атрибуты class, соответственно by для cb и array для ct.
Как я уже сказал, сила by возникает, когда мы не можем использовать tapply; следующим примером является следующий пример:
tapply(iris, iris$Species, summary )
Error in tapply(iris, iris$Species, summary) :
arguments must have same length
R говорит, что аргументы должны иметь одинаковую длину, например "мы хотим рассчитать summary всей переменной в iris по коэффициенту Species": но R просто не может этого сделать, потому что это не знать, как обращаться.
С помощью функции by R отправляет специальный метод для класса data frame, а затем пусть функция summary работает, даже если длина первого аргумента (и тип тоже) различна.
bywork <- by(iris, iris$Species, summary )
bywork
iris$Species: setosa
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
Min. :4.300 Min. :2.300 Min. :1.000 Min. :0.100 setosa :50
1st Qu.:4.800 1st Qu.:3.200 1st Qu.:1.400 1st Qu.:0.200 versicolor: 0
Median :5.000 Median :3.400 Median :1.500 Median :0.200 virginica : 0
Mean :5.006 Mean :3.428 Mean :1.462 Mean :0.246
3rd Qu.:5.200 3rd Qu.:3.675 3rd Qu.:1.575 3rd Qu.:0.300
Max. :5.800 Max. :4.400 Max. :1.900 Max. :0.600
--------------------------------------------------------------
iris$Species: versicolor
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
Min. :4.900 Min. :2.000 Min. :3.00 Min. :1.000 setosa : 0
1st Qu.:5.600 1st Qu.:2.525 1st Qu.:4.00 1st Qu.:1.200 versicolor:50
Median :5.900 Median :2.800 Median :4.35 Median :1.300 virginica : 0
Mean :5.936 Mean :2.770 Mean :4.26 Mean :1.326
3rd Qu.:6.300 3rd Qu.:3.000 3rd Qu.:4.60 3rd Qu.:1.500
Max. :7.000 Max. :3.400 Max. :5.10 Max. :1.800
--------------------------------------------------------------
iris$Species: virginica
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
Min. :4.900 Min. :2.200 Min. :4.500 Min. :1.400 setosa : 0
1st Qu.:6.225 1st Qu.:2.800 1st Qu.:5.100 1st Qu.:1.800 versicolor: 0
Median :6.500 Median :3.000 Median :5.550 Median :2.000 virginica :50
Mean :6.588 Mean :2.974 Mean :5.552 Mean :2.026
3rd Qu.:6.900 3rd Qu.:3.175 3rd Qu.:5.875 3rd Qu.:2.300
Max. :7.900 Max. :3.800 Max. :6.900 Max. :2.500
он работает действительно, и результат очень удивителен. Это объект класса by, который вдоль Species (скажем, для каждого из них) вычисляет summary каждой переменной.
Обратите внимание, что если первым аргументом является data frame, отправленная функция должна иметь метод для этого класса объектов. Например, мы используем этот код с функцией mean, у нас будет этот код, который вообще не имеет смысла:
by(iris, iris$Species, mean)
iris$Species: setosa
[1] NA
-------------------------------------------
iris$Species: versicolor
[1] NA
-------------------------------------------
iris$Species: virginica
[1] NA
Warning messages:
1: In mean.default(data[x, , drop = FALSE], ...) :
argument is not numeric or logical: returning NA
2: In mean.default(data[x, , drop = FALSE], ...) :
argument is not numeric or logical: returning NA
3: In mean.default(data[x, , drop = FALSE], ...) :
argument is not numeric or logical: returning NA
ОБЩИЙ
aggregate можно рассматривать как другой способ использования tapply, если мы будем использовать его таким образом.
at <- tapply(iris$Sepal.Length , iris$Species , mean)
ag <- aggregate(iris$Sepal.Length , list(iris$Species), mean)
at
setosa versicolor virginica
5.006 5.936 6.588
ag
Group.1 x
1 setosa 5.006
2 versicolor 5.936
3 virginica 6.588
Два непосредственных отличия заключаются в том, что второй аргумент aggregate должен быть списком, тогда как tapply может (не обязательно) быть списком и что вывод of aggregate - это кадр данных, а один из tapply - array.
Сила aggregate заключается в том, что она может обрабатывать легко подмножества данных с аргументом subset и что у нее есть методы для объектов ts и formula.
Эти элементы упрощают работу aggregate с этим tapply в некоторых ситуациях.
Вот несколько примеров (доступно в документации):
ag <- aggregate(len ~ ., data = ToothGrowth, mean)
ag
supp dose len
1 OJ 0.5 13.23
2 VC 0.5 7.98
3 OJ 1.0 22.70
4 VC 1.0 16.77
5 OJ 2.0 26.06
6 VC 2.0 26.14
Мы можем достичь того же значения с tapply, но синтаксис немного сложнее, а выход (в некоторых случаях) менее читабельный:
att <- tapply(ToothGrowth$len, list(ToothGrowth$dose, ToothGrowth$supp), mean)
att
OJ VC
0.5 13.23 7.98
1 22.70 16.77
2 26.06 26.14
Есть другие случаи, когда мы не можем использовать by или tapply, и мы должны использовать aggregate.
ag1 <- aggregate(cbind(Ozone, Temp) ~ Month, data = airquality, mean)
ag1
Month Ozone Temp
1 5 23.61538 66.73077
2 6 29.44444 78.22222
3 7 59.11538 83.88462
4 8 59.96154 83.96154
5 9 31.44828 76.89655
Мы не можем получить предыдущий результат с помощью tapply в одном вызове, но мы должны вычислить среднее значение по Month для каждого элемента и затем объединить их (также обратите внимание, что мы должны называть na.rm = TRUE, потому что formula методы функции aggregate по умолчанию имеют значение na.action = na.omit):
ta1 <- tapply(airquality$Ozone, airquality$Month, mean, na.rm = TRUE)
ta2 <- tapply(airquality$Temp, airquality$Month, mean, na.rm = TRUE)
cbind(ta1, ta2)
ta1 ta2
5 23.61538 65.54839
6 29.44444 79.10000
7 59.11538 83.90323
8 59.96154 83.96774
9 31.44828 76.90000
в то время как с by мы просто не можем добиться того, что на самом деле следующий вызов функции возвращает ошибку (но, скорее всего, она связана с предоставленной функцией, mean):
by(airquality[c("Ozone", "Temp")], airquality$Month, mean, na.rm = TRUE)
В других случаях результаты одинаковы, а различия находятся только в классе (а затем как он отображается/печатается, а не только - например, как его подмножать):
byagg <- by(airquality[c("Ozone", "Temp")], airquality$Month, summary)
aggagg <- aggregate(cbind(Ozone, Temp) ~ Month, data = airquality, summary)
Предыдущий код достигает той же цели и результатов, в некоторых случаях какой инструмент использовать - это только вопрос личных вкусов и потребностей; предыдущие два объекта имеют очень разные потребности в терминах подмножества.
-
0Как я уже сказал, сила by возникает, когда мы не можем использовать tapply; следующий код является одним из примеров: ЭТО СЛОВА, КОТОРЫЕ ВЫ ИСПОЛЬЗУЛИ. И вы привели пример вычисления резюме. Хорошо, скажем, что итоговая статистика может быть вычислена только для того, что она нуждается в очистке: например,
data.frame(tapply(unlist(iris[,-5]),list(rep(iris[,5],ncol(iris[-5])),col(iris[-5])),summary))это использование tapply. With the right splitting there is nothing you cant do withtapply. The only thing is it returns a matrix. Please be careful by saying we cant usetapply`
Есть много замечательных ответов, в которых обсуждаются различия в вариантах использования для каждой функции. Ни один из ответов не говорит о различиях в производительности. Это разумная причина, по которой различные функции ожидают различного ввода и производят различную продукцию, но большинство из них имеют общую общую цель для оценки по группам/группам. Мой ответ будет сосредоточен на производительности. Из-за выше входное создание из векторов включено в синхронизацию, также функция apply не измеряется.
Я проверил сразу две разные функции sum и length. Тестируемый объем составляет 50 М на входе и 50 КВ на выходе. Я также включил два популярных в настоящее время пакета, которые не были широко использованы в момент запроса вопроса, data.table и dplyr. Оба, безусловно, стоит посмотреть, если вы нацелены на хорошую работу.
library(dplyr)
library(data.table)
set.seed(123)
n = 5e7
k = 5e5
x = runif(n)
grp = sample(k, n, TRUE)
timing = list()
# sapply
timing[["sapply"]] = system.time({
lt = split(x, grp)
r.sapply = sapply(lt, function(x) list(sum(x), length(x)), simplify = FALSE)
})
# lapply
timing[["lapply"]] = system.time({
lt = split(x, grp)
r.lapply = lapply(lt, function(x) list(sum(x), length(x)))
})
# tapply
timing[["tapply"]] = system.time(
r.tapply <- tapply(x, list(grp), function(x) list(sum(x), length(x)))
)
# by
timing[["by"]] = system.time(
r.by <- by(x, list(grp), function(x) list(sum(x), length(x)), simplify = FALSE)
)
# aggregate
timing[["aggregate"]] = system.time(
r.aggregate <- aggregate(x, list(grp), function(x) list(sum(x), length(x)), simplify = FALSE)
)
# dplyr
timing[["dplyr"]] = system.time({
df = data_frame(x, grp)
r.dplyr = summarise(group_by(df, grp), sum(x), n())
})
# data.table
timing[["data.table"]] = system.time({
dt = setnames(setDT(list(x, grp)), c("x","grp"))
r.data.table = dt[, .(sum(x), .N), grp]
})
# all output size match to group count
sapply(list(sapply=r.sapply, lapply=r.lapply, tapply=r.tapply, by=r.by, aggregate=r.aggregate, dplyr=r.dplyr, data.table=r.data.table),
function(x) (if(is.data.frame(x)) nrow else length)(x)==k)
# sapply lapply tapply by aggregate dplyr data.table
# TRUE TRUE TRUE TRUE TRUE TRUE TRUE
# print timings
as.data.table(sapply(timing, `[[`, "elapsed"), keep.rownames = TRUE
)[,.(fun = V1, elapsed = V2)
][order(-elapsed)]
# fun elapsed
#1: aggregate 109.139
#2: by 25.738
#3: dplyr 18.978
#4: tapply 17.006
#5: lapply 11.524
#6: sapply 11.326
#7: data.table 2.686
-
0Это нормально, что dplyr ниже, чем функции applt?
-
1@DimitriPetrenko Я так не думаю, не уверен, почему это здесь. Лучше всего проверить свои собственные данные, так как в игру вступает множество факторов.
Несмотря на все замечательные ответы здесь, есть еще две базовые функции, которые заслуживают упоминания, полезная функция outer и неявная eapply функция
внешняя
outer - очень полезная функция, скрытая как более обыденная. Если вы прочитали справку для outer, в ее описании говорится:
The outer product of the arrays X and Y is the array A with dimension
c(dim(X), dim(Y)) where element A[c(arrayindex.x, arrayindex.y)] =
FUN(X[arrayindex.x], Y[arrayindex.y], ...).
из-за чего кажется, что это полезно только для вещей типа линейной алгебры. Однако его можно использовать так же, как mapply, чтобы применить функцию к двум векторам входных данных. Разница в том, что mapply применит эту функцию к первым двум элементам, а затем ко второй и т.д., Тогда как outer применит эту функцию к каждой комбинации одного элемента из первого вектора, а вторая - к второй. Например:
A<-c(1,3,5,7,9)
B<-c(0,3,6,9,12)
mapply(FUN=pmax, A, B)
> mapply(FUN=pmax, A, B)
[1] 1 3 6 9 12
outer(A,B, pmax)
> outer(A,B, pmax)
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 6 9 12
[2,] 3 3 6 9 12
[3,] 5 5 6 9 12
[4,] 7 7 7 9 12
[5,] 9 9 9 9 12
Я лично использовал это, когда у меня есть вектор значений и вектор условий и хочу видеть, какие значения соответствуют тем условиям.
eapply
eapply похож на lapply, за исключением того, что вместо применения функции к каждому элементу в списке он применяет функцию к каждому элементу в среде. Например, если вы хотите найти список пользовательских функций в глобальной среде:
A<-c(1,3,5,7,9)
B<-c(0,3,6,9,12)
C<-list(x=1, y=2)
D<-function(x){x+1}
> eapply(.GlobalEnv, is.function)
$A
[1] FALSE
$B
[1] FALSE
$C
[1] FALSE
$D
[1] TRUE
Откровенно говоря, я не использую это очень много, но если вы создаете много пакетов или создаете множество сред, это может пригодиться.
Возможно, стоит упомянуть ave. ave tapply дружелюбный кузен. Он возвращает результаты в форме, которую вы можете подключить прямо к вашему кадру данных.
dfr <- data.frame(a=1:20, f=rep(LETTERS[1:5], each=4))
means <- tapply(dfr$a, dfr$f, mean)
## A B C D E
## 2.5 6.5 10.5 14.5 18.5
## great, but putting it back in the data frame is another line:
dfr$m <- means[dfr$f]
dfr$m2 <- ave(dfr$a, dfr$f, FUN=mean) # NB argument name FUN is needed!
dfr
## a f m m2
## 1 A 2.5 2.5
## 2 A 2.5 2.5
## 3 A 2.5 2.5
## 4 A 2.5 2.5
## 5 B 6.5 6.5
## 6 B 6.5 6.5
## 7 B 6.5 6.5
## ...
В базовом пакете ничего не работает, как ave для целых фреймов данных (как by как tapply для фреймов данных). Но вы можете выдумать это:
dfr$foo <- ave(1:nrow(dfr), dfr$f, FUN=function(x) {
x <- dfr[x,]
sum(x$m*x$m2)
})
dfr
## a f m m2 foo
## 1 1 A 2.5 2.5 25
## 2 2 A 2.5 2.5 25
## 3 3 A 2.5 2.5 25
## ...
Недавно я обнаружил довольно полезную функцию sweep и добавил ее здесь для полноты:
подметать
Основная идея состоит в том, чтобы прокручивать массив row- или по столбцам и возвращать модифицированный массив. Пример сделает это ясно (source: datacamp):
Скажем, у вас есть матрица и вы хотите стандартизировать ее по столбцам:
dataPoints <- matrix(4:15, nrow = 4)
# Find means per column with 'apply()'
dataPoints_means <- apply(dataPoints, 2, mean)
# Find standard deviation with 'apply()'
dataPoints_sdev <- apply(dataPoints, 2, sd)
# Center the points
dataPoints_Trans1 <- sweep(dataPoints, 2, dataPoints_means,"-")
print(dataPoints_Trans1)
## [,1] [,2] [,3]
## [1,] -1.5 -1.5 -1.5
## [2,] -0.5 -0.5 -0.5
## [3,] 0.5 0.5 0.5
## [4,] 1.5 1.5 1.5
# Return the result
dataPoints_Trans1
## [,1] [,2] [,3]
## [1,] -1.5 -1.5 -1.5
## [2,] -0.5 -0.5 -0.5
## [3,] 0.5 0.5 0.5
## [4,] 1.5 1.5 1.5
# Normalize
dataPoints_Trans2 <- sweep(dataPoints_Trans1, 2, dataPoints_sdev, "/")
# Return the result
dataPoints_Trans2
## [,1] [,2] [,3]
## [1,] -1.1618950 -1.1618950 -1.1618950
## [2,] -0.3872983 -0.3872983 -0.3872983
## [3,] 0.3872983 0.3872983 0.3872983
## [4,] 1.1618950 1.1618950 1.1618950
NB: для этого простого примера можно, конечно, добиться того же результата apply(dataPoints, 2, scale)
-
1Это связано с группировкой?
-
2@Frank: Честно говоря, заголовок этого поста вводит в заблуждение: когда вы читаете сам вопрос, речь идет о «подходящей семье».
sweep- это функция высшего порядка, как и все другие, упомянутые здесь, например,apply,sapply,lapplyТаким образом, тот же вопрос можно задать о принятом ответе с более чем 1000 ответами и приведенными в нем примерами. Просто посмотрите на пример, приведенный дляapplyтам.
Ещё вопросы
- 1JAX-WS + Hibernate + JAXB: как избежать исключения LazyInitializationException во время сортировки
- 0Как заставить свиток двигаться вместе с диалогом в расширяющемся элементе
- 1Python запрашивает Microsoft Graph API-аутентификацию
- 0Как обнаружить тег изображения в AngularJS?
- 1Получить сфокусированное имя окна
- 0Как я могу заполнить массив в datagridview?
- 0Результаты поиска Google Search на странице - HTML
- 1Невозможно импортировать файлы в Python
- 0я могу создать общую память (используя CreateFileMapping) в локальном пространстве имен с тем же именем?
- 1Попытка реализовать аутентификацию JWT в узле. Получение несанкционированного доступа на защищенных маршрутах
- 1Привязка данных - ObservableField <String> не обновляет представление
- 0Формат IP-адреса в HTML
- 0Javascript моя функция не будет работать во второй раз, когда он нажал
- 0Как добавить цвет для заполнителя angucomplete-alt
- 1рассчитать процентную долю значения в столбце в Python
- 0Какой тип кэша лучше использовать для повышения производительности сайта?
- 0Сравните 3 объекта и покажите 1 по указанию
- 1Как дублировать поток
- 0Инициализировать не копируемый сторонний базовый класс с указателем на объект
- 0Подключите локальный хост Mysql из ядра Docker .net
- 0Как переключать строки в угловых, чтобы развернуть или свернуть ряд, как в аккордеоне?
- 0ng-options объекта, как получить значение ключа для функции (angularJS)
- 1Как я могу показать два действия на одном экране?
- 0SQL-запрос с IF, AS и LIKE
- 0jquery mobile нажмите h3 для всплывающего окна
- 0fnfilter проблема поиска в datatables
- 0Дата и метки времени ведут себя странно в PHP при добавлении дня
- 1Простая клиент-серверная программа с каналами NIO
- 1Составление листа Excel с использованием Python и Matplotlib?
- 0Альтернатива многократному использованию if-else в базе кода
- 1WPF ItemSource DataGrid TreeViewItem ошибка дополнительной строки
- 0Sql запрос Join / Где 3 таблицы
- 0Ошибка загрузки JS с использованием Backbone с помощью requireJS
- 0Как я могу сохранить $ location.hash () от добавления / сразу после #?
- 1Как настроить палитру цветов?
- 0Преобразование прототипа в JQuery - застрял с class.create и classname.prototype
- 1PyQt4 Как держать QWidget всегда на вершине?
- 0уникальный указатель в связанном стеке
- 1удаление элемента цикла foreach из перечисленной коллекции
- 0Попытка сделать простую вещь в AngularJS: form->, если вы поставите правильное слово-> появляется кнопка-> вы можете нажать и перейти на другую страницу;
- 0Как отправить список элементов с помощью ajax и jquery и как извлечь данные из него в сценарии perl, чтобы его можно было добавить в базу данных
- 1org.hibernate.id.IdentifierGenerationException: при сохранении данных в сопоставлении один в один
- 1MATPLOTLIB: Как мне предоставить файлы метрик шрифтов для рендеринга текста TeX?
- 1Боке: Не удается обновить формат всплывающей подсказки
- 0Сбой команды «python setup.py egg_info» с кодом ошибки 1 в / tmp / pip-build-hg0dbjgz / mysqlclient /
- 1Android обрабатывает все ограничения AlarmManager
- 1Чтение значения файлов cookie в веб-клиенте с поддержкой файлов cookie
- 0положить элементы d3.js на слайдер
- 1Сохранение файлового объекта с помощью matplotlib savefig, создание tar-файла из нескольких рисунков SVG
- 1Как настроить откат на фреймворке Swift Mailer в php

*apply()иby. Plyr (по крайней мере, мне) кажется гораздо более последовательным в том, что я всегда точно знаю, какой формат данных он ожидает и что именно он будет выплевывать. Это избавляет меня от многих хлопот.doByи возможности выбора и примененияdata.table.