Использование LIMIT в GROUP BY для получения N результатов на группу?
Следующий запрос:
SELECT
year, id, rate
FROM h
WHERE year BETWEEN 2000 AND 2009
AND id IN (SELECT rid FROM table2)
GROUP BY id, year
ORDER BY id, rate DESC
дает:
year id rate
2006 p01 8
2003 p01 7.4
2008 p01 6.8
2001 p01 5.9
2007 p01 5.3
2009 p01 4.4
2002 p01 3.9
2004 p01 3.5
2005 p01 2.1
2000 p01 0.8
2001 p02 12.5
2004 p02 12.4
2002 p02 12.2
2003 p02 10.3
2000 p02 8.7
2006 p02 4.6
2007 p02 3.3
Мне бы хотелось только получить 5 лучших результатов для каждого id:
2006 p01 8
2003 p01 7.4
2008 p01 6.8
2001 p01 5.9
2007 p01 5.3
2001 p02 12.5
2004 p02 12.4
2002 p02 12.2
2003 p02 10.3
2000 p02 8.7
Есть ли способ сделать это, используя какой-то модификатор LIMIT, который работает в GROUP BY?
14 ответов
Вы можете использовать агрегированную функцию GROUP_CONCAT, чтобы получить все годы в один столбец, сгруппированный по id и упорядоченный по rate:
SELECT id, GROUP_CONCAT(year ORDER BY rate DESC) grouped_year
FROM yourtable
GROUP BY id
Результат:
-----------------------------------------------------------
| ID | GROUPED_YEAR |
-----------------------------------------------------------
| p01 | 2006,2003,2008,2001,2007,2009,2002,2004,2005,2000 |
| p02 | 2001,2004,2002,2003,2000,2006,2007 |
-----------------------------------------------------------
И затем вы можете использовать FIND_IN_SET, который возвращает позицию первого аргумента во втором, например.
SELECT FIND_IN_SET('2006', '2006,2003,2008,2001,2007,2009,2002,2004,2005,2000');
1
SELECT FIND_IN_SET('2009', '2006,2003,2008,2001,2007,2009,2002,2004,2005,2000');
6
Используя комбинацию GROUP_CONCAT и FIND_IN_SET и фильтруя по позиции, возвращаемой find_in_set, вы можете использовать этот запрос, который возвращает только первые 5 лет для каждого id:
SELECT
yourtable.*
FROM
yourtable INNER JOIN (
SELECT
id,
GROUP_CONCAT(year ORDER BY rate DESC) grouped_year
FROM
yourtable
GROUP BY id) group_max
ON yourtable.id = group_max.id
AND FIND_IN_SET(year, grouped_year) BETWEEN 1 AND 5
ORDER BY
yourtable.id, yourtable.year DESC;
Смотрите здесь скрипку здесь.
Обратите внимание, что если более одной строки может иметь одинаковый коэффициент, вам следует рассмотреть возможность использования GROUP_CONCAT (DISTINCT rate ORDER BY rate) в столбце скорости вместо столбца года.
Максимальная длина строки, возвращаемой GROUP_CONCAT, ограничена, поэтому это хорошо работает, если вам нужно выбрать несколько записей для каждой группы.
-
1Умный трюк и приятное объяснение!
-
1Это красиво , сравнительно просто и отличное объяснение; Спасибо огромное. К вашему последнему пункту, где разумная максимальная длина может быть вычислена, можно использовать
SET SESSION group_concat_max_len = <maximum length>;В случае OP это не проблема (так как по умолчанию 1024), но в качестве примера, group_concat_max_len должно быть не менее 25: 4 (максимальная длина строки года) + 1 (символ разделителя), время 5 (первое 5 лет). Строки усечены, а не выдают ошибку, поэтому следите за предупреждениями, такими как1054 rows in set, 789 warnings (0.31 sec).
исходный запрос использовал пользовательские переменные и ORDER BY в производных таблицах; поведение обоих причуд не гарантируется. Пересмотренный ответ выглядит следующим образом.
Для достижения желаемого результата вы можете использовать бедный человек в ранге над разделом. Просто внешнее соединение таблицы с самим собой и для каждой строки подсчитывает количество строк меньше, чем оно:
SELECT testdata.id, testdata.rate, testdata.year, COUNT(lesser.rate) AS rank
FROM testdata
LEFT JOIN testdata AS lesser ON testdata.id = lesser.id AND testdata.rate < lesser.rate
GROUP BY testdata.id, testdata.rate, testdata.year
HAVING COUNT(lesser.rate) < 5
ORDER BY testdata.id, testdata.rate DESC
Обратите внимание, что:
- COUNT основан на нулевом уровне
- Для сортировки по убыванию меньшая строка - с более высокой скоростью
- Все строки, привязанные для последнего места, возвращаются
Результат:
+------+-------+------+------+
| id | rate | year | rank |
+------+-------+------+------+
| p01 | 8.00 | 2006 | 0 |
| p01 | 7.40 | 2003 | 1 |
| p01 | 6.80 | 2008 | 2 |
| p01 | 5.90 | 2001 | 3 |
| p01 | 5.30 | 2007 | 4 |
| p02 | 12.50 | 2001 | 0 |
| p02 | 12.40 | 2004 | 1 |
| p02 | 12.20 | 2002 | 2 |
| p02 | 10.30 | 2003 | 3 |
| p02 | 8.70 | 2000 | 4 |
+------+-------+------+------+
-
7Я думаю, что стоит упомянуть, что ключевой частью является ORDER BY id, поскольку любое изменение значения id возобновит подсчет ранга.
-
0Почему я должен запустить его дважды, чтобы получить ответ от
WHERE rank <=5? Впервые я не получаю 5 строк от каждого идентификатора, но после этого я могу получить, как вы сказали.
Для меня что-то вроде
SUBSTRING_INDEX(group_concat(col_name order by desired_col_order_name), ',', N)
работает отлично. Нет сложного запроса.
например: получить верхнюю 1 для каждой группы
SELECT
*
FROM
yourtable
WHERE
id IN (SELECT
SUBSTRING_INDEX(GROUP_CONCAT(id
ORDER BY rate DESC),
',',
1) id
FROM
yourtable
GROUP BY year)
ORDER BY rate DESC;
Попробуйте следующее:
SELECT h.year, h.id, h.rate
FROM (SELECT h.year, h.id, h.rate, IF(@lastid = (@lastid:=h.id), @index:=@index+1, @index:=0) indx
FROM (SELECT h.year, h.id, h.rate
FROM h
WHERE h.year BETWEEN 2000 AND 2009 AND id IN (SELECT rid FROM table2)
GROUP BY id, h.year
ORDER BY id, rate DESC
) h, (SELECT @lastid:='', @index:=0) AS a
) h
WHERE h.indx <= 5;
-
1неизвестный столбец a.type в списке полей
Для этого требуется ряд подзапросов для ранжирования значений, их ограничения, затем выполнения суммы при группировке
@Rnk:=0;
@N:=2;
select
c.id,
sum(c.val)
from (
select
b.id,
b.bal
from (
select
if(@last_id=id,@Rnk+1,1) as Rnk,
a.id,
a.val,
@last_id=id,
from (
select
id,
val
from list
order by id,val desc) as a) as b
where b.rnk < @N) as c
group by c.id;
Нет, вы не можете LIMIT подзапросы произвольно (вы можете сделать это в ограниченной степени в новых MySQL, но не для 5 результатов для каждой группы).
Это запрос типа groupwise-maximum, который не является тривиальным для SQL. Существуют различные способы для решения того, что может быть более эффективным для некоторых случаев, но для top-n вообще вы захотите посмотреть ответьте на ответ на аналогичный предыдущий вопрос.
Как и в большинстве решений этой проблемы, он может возвращать более пяти строк, если имеется несколько строк с тем же значением rate, поэтому вам может потребоваться некоторое количество пост-обработки, чтобы проверить это.
Создайте виртуальные столбцы (например, RowID в Oracle)
Таблица:
`
CREATE TABLE `stack`
(`year` int(11) DEFAULT NULL,
`id` varchar(10) DEFAULT NULL,
`rate` float DEFAULT NULL)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
`
Данные:
insert into stack values(2006,'p01',8);
insert into stack values(2001,'p01',5.9);
insert into stack values(2007,'p01',5.3);
insert into stack values(2009,'p01',4.4);
insert into stack values(2001,'p02',12.5);
insert into stack values(2004,'p02',12.4);
insert into stack values(2005,'p01',2.1);
insert into stack values(2000,'p01',0.8);
insert into stack values(2002,'p02',12.2);
insert into stack values(2002,'p01',3.9);
insert into stack values(2004,'p01',3.5);
insert into stack values(2003,'p02',10.3);
insert into stack values(2000,'p02',8.7);
insert into stack values(2006,'p02',4.6);
insert into stack values(2007,'p02',3.3);
insert into stack values(2003,'p01',7.4);
insert into stack values(2008,'p01',6.8);
SQL:
select t3.year,t3.id,t3.rate
from (select t1.*, (select count(*) from stack t2 where t1.rate<=t2.rate and t1.id=t2.id) as rownum from stack t1) t3
where rownum <=3 order by id,rate DESC;
если удалить предложение where в t3, оно выглядит следующим образом:
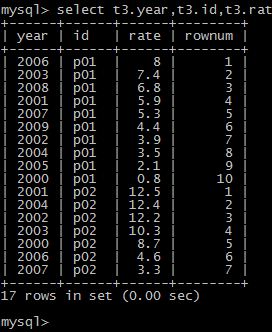
GET "TOP N Record" → добавить "rownum <= 3" в разделе where (where-clause t3);
ВЫБЕРИТЕ "год" → добавить "МЕЖДУ 2000 И 2009" в разделе where (where-clause t3);
-
0Если у вас есть ставки, которые повторяются для одного и того же идентификатора, это не будет работать, потому что ваш счетчик строк увеличится; вы не получите 3 за строку, вы можете получить 0, 1 или 2. Можете ли вы придумать какое-либо решение для этого?
-
0@starvator замените «t1.rate <= t2.rate» на «t1.rate <t2.rate», если лучшая ставка имеет одинаковые значения с одинаковым идентификатором, все они имеют одинаковый rownum, но не будут увеличиваться выше; например, "rate 8 in id p01", если он повторяется с использованием "t1.rate <t2.rate", оба из "rate 8 in id p01" имеют одинаковое значение rownum 0; при использовании «t1.rate <= t2.rate» значение rownum равно 2;
Взял немного работы, но я решил, что мое решение будет чем-то разделяться, поскольку оно кажется элегантным, а также довольно быстрым.
SELECT h.year, h.id, h.rate
FROM (
SELECT id,
SUBSTRING_INDEX(GROUP_CONCAT(CONCAT(id, '-', year) ORDER BY rate DESC), ',' , 5) AS l
FROM h
WHERE year BETWEEN 2000 AND 2009
GROUP BY id
ORDER BY id
) AS h_temp
LEFT JOIN h ON h.id = h_temp.id
AND SUBSTRING_INDEX(h_temp.l, CONCAT(h.id, '-', h.year), 1) != h_temp.l
Обратите внимание, что этот пример указан для целей вопроса и может быть легко модифицирован для других аналогичных целей.
Следующая запись: sql: selcting top N записей для каждой группы описывает сложный способ достижения этого без подзапросов.
Это улучшает другие решения, предлагаемые здесь:
- Выполнение всего в одном запросе
- Возможность правильно использовать индексы
- Предотвращение подзапросов, которые, как известно, создают плохие планы выполнения в MySQL
Это, однако, не очень. Хорошим решением было бы возможно, если в MySQL были включены функции Window (aka Analytic Functions), но это не так. В трюке, используемой в указанном сообщении, используется GROUP_CONCAT, который иногда описывается как "Функции окна для MySQL".
Попробуйте следующее:
SET @num := 0, @type := '';
SELECT `year`, `id`, `rate`,
@num := if(@type = `id`, @num + 1, 1) AS `row_number`,
@type := `id` AS `dummy`
FROM (
SELECT *
FROM `h`
WHERE (
`year` BETWEEN '2000' AND '2009'
AND `id` IN (SELECT `rid` FROM `table2`) AS `temp_rid`
)
ORDER BY `id`
) AS `temph`
GROUP BY `year`, `id`, `rate`
HAVING `row_number`<='5'
ORDER BY `id`, `rate DESC;
для таких, как я, у которых были тайм-ауты запросов. Я сделал следующее, чтобы использовать ограничения и все остальное определенной группой.
DELIMITER $$
CREATE PROCEDURE count_limit200()
BEGIN
DECLARE a INT Default 0;
DECLARE stop_loop INT Default 0;
DECLARE domain_val VARCHAR(250);
DECLARE domain_list CURSOR FOR SELECT DISTINCT domain FROM db.one;
OPEN domain_list;
SELECT COUNT(DISTINCT(domain)) INTO stop_loop
FROM db.one;
-- BEGIN LOOP
loop_thru_domains: LOOP
FETCH domain_list INTO domain_val;
SET a=a+1;
INSERT INTO db.two(book,artist,title,title_count,last_updated)
SELECT * FROM
(
SELECT book,artist,title,COUNT(ObjectKey) AS titleCount, NOW()
FROM db.one
WHERE book = domain_val
GROUP BY artist,title
ORDER BY book,titleCount DESC
LIMIT 200
) a ON DUPLICATE KEY UPDATE title_count = titleCount, last_updated = NOW();
IF a = stop_loop THEN
LEAVE loop_thru_domain;
END IF;
END LOOP loop_thru_domain;
END $$
он перебирает список доменов, а затем вставляет только 200-значный предел
SELECT year, id, rate
FROM (SELECT
year, id, rate, row_number() over (partition by id order by rate DESC)
FROM h
WHERE year BETWEEN 2000 AND 2009
AND id IN (SELECT rid FROM table2)
GROUP BY id, year
ORDER BY id, rate DESC) as subquery
WHERE row_number <= 5
Подзапрос почти идентичен вашему запросу. Только изменение добавляет
row_number() over (partition by id order by rate DESC)
-
8Это хорошо, но в MySQL нет оконных функций (например,
ROW_NUMBER()). -
2Начиная с MySQL 8.0,
row_number()доступен .
Пожалуйста, попробуйте выполнить хранимую процедуру. Я уже проверял. Я получаю правильный результат, но без использования groupby.
CREATE DEFINER=`ks_root`@`%` PROCEDURE `first_five_record_per_id`()
BEGIN
DECLARE query_string text;
DECLARE datasource1 varchar(24);
DECLARE done INT DEFAULT 0;
DECLARE tenants varchar(50);
DECLARE cur1 CURSOR FOR SELECT rid FROM demo1;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = 1;
SET @query_string='';
OPEN cur1;
read_loop: LOOP
FETCH cur1 INTO tenants ;
IF done THEN
LEAVE read_loop;
END IF;
SET @datasource1 = tenants;
SET @query_string = concat(@query_string,'(select * from demo where `id` = ''',@datasource1,''' order by rate desc LIMIT 5) UNION ALL ');
END LOOP;
close cur1;
SET @query_string = TRIM(TRAILING 'UNION ALL' FROM TRIM(@query_string));
select @query_string;
PREPARE stmt FROM @query_string;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END
Следующие группы запросов записываются на основе Grouping_COL и поэтапно назначают row_number каждой записи в каждой группе. Затем вы можете выполнить выбор, чтобы вернуть все записи, у которых количество строк меньше, чем счет.
SELECT
Grouping_COL ,
rownum_cnt
FROM
(
SELECT
Grouping_COL,
row_number() OVER (PARTITION BY Grouping_COL) AS rownum_cnt
FROM MyTable
)
WHERE rownum_cnt <= 100
Ещё вопросы
- 1Как слушать один из его компонентов JButton?
- 0Пример jQuery inArray в фильтрах
- 1Почему bouncycastle нужен сертификат эмитента для проверки статуса OCSP данного сертификата?
- 0Как добавить прокручиваемый div внутри snap-контента, который исправлен?
- 0Как я могу хранить отдельное изображение в отдельном поле с одним кодом PHP
- 1Подпись по java и openssl не совпадает
- 1Как я могу получить доступ к объекту, связанному с LiveData, вне наблюдателя?
- 0Как получить 2 конкретные строки из БД в Laravel
- 1Дополнительный набор баров на участке в Pandas?
- 1Атрибут Web.config xmlns при чтении его в xslt.Problems
- 0Ошибка PostgreSQL при попытке подключения в python: неверный dsn: неверный параметр подключения «имя пользователя»
- 1документация sikuli 1.0.2 и ScreenRegion
- 1Geckodriver не может нажать на элемент | Python 3 Coding
- 1Удалить в Java?
- 0C ++ SFML 2 Текст не обновляется должным образом
- 0Преобразование даты в формат .ICS (1 час)
- 0Ошибка подтверждения OpenCV для некоторых значений Pixal
- 1Как разбить панду dataframe одной строки на две строки?
- 1Подсчет количества вызовов функций для различных значений входных аргументов
- 0Как исключить строки со значениями '0', но не строки со значениями NULL в SQL?
- 0Как лучше всего связать обещания при использовании решимости Angular: {}?
- 1просмотреть и скачать файл из sql db с помощью Entity FrameWork
- 0Агрегация не работает в Mongoose с Match и Group
- 0Лучший способ извлечь доменное имя в Jquery
- 0Утверждение рейтинга звезд jquery
- 0Двоичное дерево не вставляется
- 0Ошибка консоли ZF2 - Get не удалось получить или создать экземпляр для ViewRenderer
- 0Сессионизация на основе событий, а не временных меток с MySQL
- 0функция slideToggle работает отдельно
- 0отправлять http запросы, поддерживать сессию: C / C ++ с cURL (камера Axus)
- 1Что происходит с файлами при обновлении приложения?
- 0Получение строк из одной таблицы, у которых нет связанных строк в других таблицах, соответствующих определенным критериям, без подзапроса
- 1Как создать частичные классы из CodeFirst
- 0Как я могу загрузить файлы CoffeeScript из пакетов Bower с помощью веб-пакета?
- 0JQuery флажок проблемы
- 1Навигационный ящик с закругленными углами фона для предметов
- 0Скользящая Div от левого угла к правому углу анимации
- 0PHP MySQL: правильный / простой способ реализации динамической фильтрации
- 0с ++: обмен картами
- 0Центрирование текста с использованием CSS
- 1Использование PowerShell в качестве двоичного файла CGI в IIS Express
- 1.renderTitle (false) не работает на линейной диаграмме DC.js
- 0Как получить доступ к одному действию контроллера внутри другого действия контроллера?
- 0Резервное копирование в онлайн-хранилище с использованием сценария оболочки
- 1Временно хранить данные в приложении с несколькими активностями, пока приложение не будет остановлено?
- 1лишние пробелы перед печатным текстом Java
- 1Поместите карту Java в JSON
- 1Чтение из нескольких обменов RabbitMQ в клиенте Java не опрос
- 1генерировать данные из базы данных в Excel с помощью Python, но дата и время в Excel не правильный формат
- 1Как преобразовать многострочные файлы fasta в однострочные файлы fasta без биопиона

LIMIT. Вот статья, которая подробно объясняет проблему: Как выбрать первую / наименьшую / максимальную строку для каждой группы в SQL. Это хорошая статья - он представляет элегантное, но наивное решение проблемы «Top N на группу», а затем постепенно улучшается на этом.