HTML-кодировка теряется при чтении атрибута из поля ввода
Im использует JavaScript, чтобы вывести значение из скрытого поля и отобразить его в текстовом поле. Значение в скрытом поле закодировано.
Например,
<input id='hiddenId' type='hidden' value='chalk & cheese' />
втягивается в
<input type='text' value='chalk & cheese' />
через некоторый jQuery, чтобы получить значение из скрытого поля (его в этот момент, когда я теряю кодировку):
$('#hiddenId').attr('value')
Проблема в том, что когда я читал chalk & cheese из скрытого поля, JavaScript, похоже, потерял кодировку. Чтобы выйти из " и ', я хочу, чтобы кодировка оставалась.
Есть ли библиотека JavaScript или метод jQuery, который будет кодировать HTML-строку?
-
0Можете ли вы показать Javascript, который вы используете?Sinan Taifour
-
1добавил, как я получаю значение из скрытого поляAJM
24 ответа
Я использую следующие функции:
function htmlEncode(value){
// Create a in-memory div, set its inner text (which jQuery automatically encodes)
// Then grab the encoded contents back out. The div never exists on the page.
return $('<div/>').text(value).html();
}
function htmlDecode(value){
return $('<div/>').html(value).text();
}
В принципе, элемент div создается в памяти, но он никогда не добавляется к документу.
В функции htmlEncode я устанавливаю innerText элемента и извлекаю закодированный innerHTML; в функции htmlDecode я устанавливаю значение innerHTML элемента и извлекается innerText.
Проверьте приведенный ниже пример .
-
95Это работает для большинства сценариев, но эта реализация htmlDecode устранит любые дополнительные пробелы. Поэтому для некоторых значений «input» введите! = HtmlDecode (htmlEncode (input)). Это было проблемой для нас в некоторых сценариях. Например, если input = "<p> \ t Hi \ n There </ p>", кодирование / декодирование в обе стороны даст "<p> Hi There </ p>". В большинстве случаев это нормально, но иногда это не так. :)
-
0Зависит от браузера, в Firefox он включает пробелы, новые строки ... В IE он удаляет все.
Трюк jQuery не кодирует метки кавычек, а в IE он лишит ваши пробелы.
На основе escape templatetag в Django, который, как мне кажется, уже давно используется/протестирован, я сделал эту функцию, которая делает то, что нужно.
Он, возможно, проще (и, возможно, быстрее), чем любой из обходных путей для проблемы удаления пробелов - и он кодирует кавычки, что существенно, если вы собираетесь использовать результат внутри значения атрибута, например.
function htmlEscape(str) {
return str
.replace(/&/g, '&')
.replace(/"/g, '"')
.replace(/'/g, ''')
.replace(/</g, '<')
.replace(/>/g, '>');
}
// I needed the opposite function today, so adding here too:
function htmlUnescape(str){
return str
.replace(/"/g, '"')
.replace(/'/g, "'")
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/&/g, '&');
}
Обновление 2013-06-17:
В поисках быстрого ускорения я нашел эту реализацию метода replaceAll:
http://dumpsite.com/forum/index.php?topic=4.msg29#msg29
(также упоминается здесь: Самый быстрый способ заменить все экземпляры символа в строке)
Некоторые результаты работы здесь:
http://jsperf.com/htmlencoderegex/25
Он дает идентичную строку результата встроенным цепочкам replace выше. Я был бы очень рад, если бы кто-нибудь мог объяснить, почему это быстрее!?
Обновление 2015-03-04:
Я только заметил, что AngularJS использует именно этот метод выше:
https://github.com/angular/angular.js/blob/v1.3.14/src/ngSanitize/sanitize.js#L435
Они добавляют несколько уточнений - они, похоже, обрабатывают непонятную проблему Unicode, а также преобразуют все не-буквенно-цифровые символы в объекты. Мне показалось, что последнее не было необходимым, если у вас есть кодировка UTF8, указанная для вашего документа.
Отмечу, что (4 года спустя) Django все равно не делает ни одной из этих вещей, поэтому я не уверен, насколько они важны:
https://github.com/django/django/blob/1.8b1/django/utils/html.py#L44
Обновление 2016-04-06:
Вы также можете избежать прокрутки вперед /. Это не требуется для правильной кодировки HTML, однако это рекомендованное OWASP в качестве меры безопасности для предотвращения XSS. (спасибо @JNF за предложение этого в комментариях)
.replace(/\//g, '/');
-
2Вы также можете использовать
'вместо' -
30@Ferruccio ... и по причинам, почему бы не использовать & apos; см: stackoverflow.com/questions/2083754/... blogs.msdn.com/b/kirillosenkov/archive/2010/03/19/... fishbowl.pastiche.org/2003/07/01/the_curse_of_apos
Здесь версия, отличная от jQuery, которая значительно быстрее, чем версия jQuery .html() и версия .replace(). Это сохраняет все пробелы, но, как и версия jQuery, не обрабатывает кавычки.
function htmlEncode( html ) {
return document.createElement( 'a' ).appendChild(
document.createTextNode( html ) ).parentNode.innerHTML;
};
Скорость: http://jsperf.com/htmlencoderegex/17
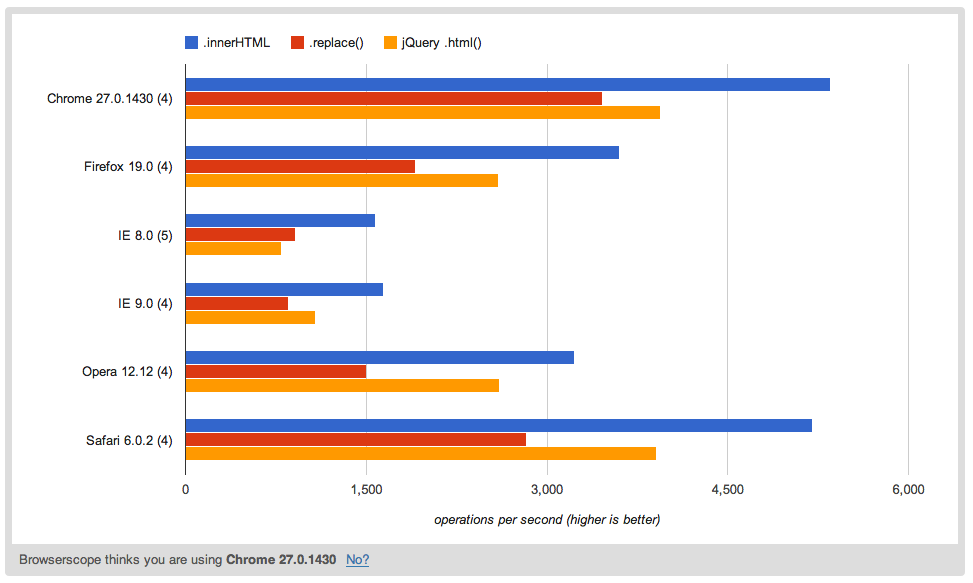
Демо: 
Вывод:

Script:
function htmlEncode( html ) {
return document.createElement( 'a' ).appendChild(
document.createTextNode( html ) ).parentNode.innerHTML;
};
function htmlDecode( html ) {
var a = document.createElement( 'a' ); a.innerHTML = html;
return a.textContent;
};
document.getElementById( 'text' ).value = htmlEncode( document.getElementById( 'hidden' ).value );
//sanity check
var html = '<div> & hello</div>';
document.getElementById( 'same' ).textContent =
'html === htmlDecode( htmlEncode( html ) ): '
+ ( html === htmlDecode( htmlEncode( html ) ) );
HTML:
<input id="hidden" type="hidden" value="chalk & cheese" />
<input id="text" value="" />
<div id="same"></div>
-
17Возникает вопрос: почему это уже не глобальная функция в JS ?!
-
2версия non-regex
.replace()недавно предложенная @SEoF, оказывается значительно быстрее: jsperf.com/htmlencoderegex/22
Я знаю, что это старый, но я хотел опубликовать вариант принятого ответа, который будет работать в IE без удаления строк:
function multiLineHtmlEncode(value) {
var lines = value.split(/\r\n|\r|\n/);
for (var i = 0; i < lines.length; i++) {
lines[i] = htmlEncode(lines[i]);
}
return lines.join('\r\n');
}
function htmlEncode(value) {
return $('<div/>').text(value).html();
}
Underscore предоставляет _.escape() и _.unescape(), которые делают это.
> _.unescape( "chalk & cheese" );
"chalk & cheese"
> _.escape( "chalk & cheese" );
"chalk & cheese"
-
0У Лодаша тоже есть похожий метод.
Хороший ответ. Обратите внимание, что если значение для кодирования составляет undefined или null с jQuery 1.4.2, вы можете получить такие ошибки, как:
jQuery("<div/>").text(value).html is not a function
ИЛИ
Uncaught TypeError: Object has no method 'html'
Решение состоит в том, чтобы изменить функцию, чтобы проверить фактическое значение:
function htmlEncode(value){
if (value) {
return jQuery('<div/>').text(value).html();
} else {
return '';
}
}
-
8
jQuery('<div/>').text(value || '').html() -
3@roufamatic - Хороший лайнер. Но проверка непустого
valueс помощьюifизбавляет от необходимости создавать DIV на лету и получать его значение. Это может быть намного более производительным, еслиhtmlEncodeвызывается много И, если это вероятно, чтоvalueбудет пустым.
Для тех, кто предпочитает простой javascript, вот метод, который я использовал успешно:
function escapeHTML (str)
{
var div = document.createElement('div');
var text = document.createTextNode(str);
div.appendChild(text);
return div.innerHTML;
}
Быстрее без JQuery. Вы можете кодировать каждый символ в строке:
function encode(e){return e.replace(/[^]/g,function(e){return"&#"+e.charCodeAt(0)+";"})}
Или просто нацелитесь на главных героев, чтобы беспокоиться (&, inebreaks, <, > , "and '), например:
function encode(r){
return r.replace(/[\x26\x0A\<>'"]/g,function(r){return"&#"+r.charCodeAt(0)+";"})
}
test.value=encode('Encode HTML entities!\n\n"Safe" escape <script id=\'\'> & useful in <pre> tags!');
testing.innerHTML=test.value;
/*************
* \x26 is &ersand (it has to be first),
* \x0A is newline,
*************/<textarea id=test rows="9" cols="55"></textarea>
<div id="testing">www.WHAK.com</div>FWIW, кодировка не теряется. Кодировка используется парсером разметки (браузером) во время загрузки страницы. После того, как источник будет прочитан и проанализирован, а браузер загрузит DOM в память, кодировка была проанализирована в том, что она представляет. Таким образом, к тому моменту, когда ваш JS выполняется для чтения чего-либо в памяти, char он получает, что представляет собой кодировка.
Я могу работать строго по семантике здесь, но я хотел, чтобы вы поняли цель кодирования. Слово "потерянное" заставляет его звучать так, будто что-то не работает так, как должно.
Прототип имеет встроенный класс String. Поэтому, если вы используете/планируете использовать Prototype, он делает что-то вроде:
'<div class="article">This is an article</div>'.escapeHTML();
// -> "<div class="article">This is an article</div>"
-
9Посмотрев на решение Prototype, это все, что он делает ...
.replace(/&/g,'&').replace(/</g,'<').replace(/>/g,'>');Достаточно просто. -
4разве это не должно делать что-то с кавычками тоже? это не хорошо
Вот простое решение для javascript. Он расширяет объект String с помощью метода "HTMLEncode", который может использоваться для объекта без параметра или с параметром.
String.prototype.HTMLEncode = function(str) {
var result = "";
var str = (arguments.length===1) ? str : this;
for(var i=0; i<str.length; i++) {
var chrcode = str.charCodeAt(i);
result+=(chrcode>128) ? "&#"+chrcode+";" : str.substr(i,1)
}
return result;
}
// TEST
console.log("stetaewteaw æø".HTMLEncode());
console.log("stetaewteaw æø".HTMLEncode("æåøåæå"))
Я создал gist "метод HTMLEncode для javascript" .
На основе angular sanitize... (синтаксис модуля es6)
// ref: https://github.com/angular/angular.js/blob/v1.3.14/src/ngSanitize/sanitize.js
const SURROGATE_PAIR_REGEXP = /[\uD800-\uDBFF][\uDC00-\uDFFF]/g;
const NON_ALPHANUMERIC_REGEXP = /([^\#-~| |!])/g;
const decodeElem = document.createElement('pre');
/**
* Decodes html encoded text, so that the actual string may
* be used.
* @param value
* @returns {string} decoded text
*/
export function decode(value) {
if (!value) return '';
decodeElem.innerHTML = value.replace(/</g, '<');
return decodeElem.textContent;
}
/**
* Encodes all potentially dangerous characters, so that the
* resulting string can be safely inserted into attribute or
* element text.
* @param value
* @returns {string} encoded text
*/
export function encode(value) {
if (value === null || value === undefined) return '';
return String(value).
replace(/&/g, '&').
replace(SURROGATE_PAIR_REGEXP, value => {
var hi = value.charCodeAt(0);
var low = value.charCodeAt(1);
return '&#' + (((hi - 0xD800) * 0x400) + (low - 0xDC00) + 0x10000) + ';';
}).
replace(NON_ALPHANUMERIC_REGEXP, value => {
return '&#' + value.charCodeAt(0) + ';';
}).
replace(/</g, '<').
replace(/>/g, '>');
}
export default {encode,decode};
-
0Хотя мне действительно нравится этот ответ, и на самом деле я думаю, что это хороший подход, у меня есть сомнения, является ли побитовый оператор
if (value === null | value === undefined) return '';опечатка или на самом деле особенность? Если это так, зачем использовать этот, а не общий||? Спасибо!! -
1@AlejandroVales Я уверен, что это была опечатка ... исправлено.
У меня была аналогичная проблема и решить ее с помощью функции encodeURIComponent из JavaScript (документация)
Например, в вашем случае, если вы используете:
<input id='hiddenId' type='hidden' value='chalk & cheese' />
и
encodeURIComponent($('#hiddenId').attr('value'))
вы получите chalk%20%26%20cheese. Сохраняются даже пробелы.
В моем случае мне пришлось кодировать одну обратную косую черту, и этот код отлично работает
encodeURIComponent('name/surname')
и я получил name%2Fsurname
Вам не нужно выходить/кодировать значения, чтобы передавать их из одного поля ввода в другое.
<form>
<input id="button" type="button" value="Click me">
<input type="hidden" id="hiddenId" name="hiddenId" value="I like cheese">
<input type="text" id="output" name="output">
</form>
<script>
$(document).ready(function(e) {
$('#button').click(function(e) {
$('#output').val($('#hiddenId').val());
});
});
</script>
JS не идет вставлять необработанный HTML-код или что-то еще; он просто сообщает DOM установить свойство value (или атрибут; не уверен). В любом случае, DOM обрабатывает любые проблемы с кодировкой для вас. Если вы не делаете что-то странное, например, используя document.write или eval, HTML-кодирование будет эффективно прозрачным.
Если вы говорите о создании нового текстового поля для хранения результата... это все равно так же просто. Просто передайте статическую часть HTML в jQuery, а затем установите остальные свойства/атрибуты объекта, который он возвращает вам.
$box = $('<input type="text" name="whatever">').val($('#hiddenId').val());
afaik в javascript нет никаких прямых методов кодирования/декодирования HTML.
Однако, что вы можете сделать, это использовать JS для создания произвольного элемента, установить его внутренний текст, а затем прочитать его с помощью innerHTML.
скажем, с jQuery это должно работать:
var helper = $('chalk & cheese').hide().appendTo('body');
var htmled = helper.html();
helper.remove();
или что-то в этом роде
-
0Я нахожу понижение голоса немного забавным, учитывая, что этот ответ почти идентичен ответу, у которого более 870 голосов, и который был опубликован чуть позже.
Здесь немного, что эмулирует функцию Server.HTMLEncode из Microsoft ASP, написанную на чистом JavaScript:
function htmlEncode(s) {
var ntable = {
"&": "amp",
"<": "lt",
">": "gt",
"\"": "quot"
};
s = s.replace(/[&<>"]/g, function(ch) {
return "&" + ntable[ch] + ";";
})
s = s.replace(/[^ -\x7e]/g, function(ch) {
return "&#" + ch.charCodeAt(0).toString() + ";";
});
return s;
}Результат не кодирует апострофы, а кодирует другие специальные HTML-символы и любой символ вне диапазона 0x20-0x7e.
Я столкнулся с некоторыми проблемами с обратной косой чертой в моей строке "Домен\Пользователь".
Я добавил это к другим экранам из ответа Anentropic
.replace(/\\/g, '\')
Что я нашел здесь: Как избежать обратной косой черты в JavaScript?
HtmlEnкодирует заданное значение
var htmlEncodeContainer = $('<div />');
function htmlEncode(value) {
if (value) {
return htmlEncodeContainer.text(value).html();
} else {
return '';
}
}
<script>
String.prototype.htmlEncode = function () {
return String(this)
.replace(/&/g, '&')
.replace(/"/g, '"')
.replace(/'/g, ''')
.replace(/</g, '<')
.replace(/>/g, '>');
}
var aString = '<script>alert("I hack your site")</script>';
console.log(aString.htmlEncode());
</script>
Выведет: <script>alert("I hack your site")</script>
.htmlEncode() будет доступен для всех строк, определенных после определения.
-
0Как правило, расширение прототипов не очень хорошая идея.
var htmlEnDeCode = (function() {
var charToEntityRegex,
entityToCharRegex,
charToEntity,
entityToChar;
function resetCharacterEntities() {
charToEntity = {};
entityToChar = {};
// add the default set
addCharacterEntities({
'&' : '&',
'>' : '>',
'<' : '<',
'"' : '"',
''' : "'"
});
}
function addCharacterEntities(newEntities) {
var charKeys = [],
entityKeys = [],
key, echar;
for (key in newEntities) {
echar = newEntities[key];
entityToChar[key] = echar;
charToEntity[echar] = key;
charKeys.push(echar);
entityKeys.push(key);
}
charToEntityRegex = new RegExp('(' + charKeys.join('|') + ')', 'g');
entityToCharRegex = new RegExp('(' + entityKeys.join('|') + '|&#[0-9]{1,5};' + ')', 'g');
}
function htmlEncode(value){
var htmlEncodeReplaceFn = function(match, capture) {
return charToEntity[capture];
};
return (!value) ? value : String(value).replace(charToEntityRegex, htmlEncodeReplaceFn);
}
function htmlDecode(value) {
var htmlDecodeReplaceFn = function(match, capture) {
return (capture in entityToChar) ? entityToChar[capture] : String.fromCharCode(parseInt(capture.substr(2), 10));
};
return (!value) ? value : String(value).replace(entityToCharRegex, htmlDecodeReplaceFn);
}
resetCharacterEntities();
return {
htmlEncode: htmlEncode,
htmlDecode: htmlDecode
};
})();
Это из исходного кода ExtJS.
Если вы хотите использовать jQuery. Я нашел это:
http://www.jquerysdk.com/api/jQuery.htmlspecialchars
(часть плагина jquery.string, предлагаемого jQuery SDK)
Проблема с Prototype, я считаю, заключается в том, что она расширяет базовые объекты в JavaScript и будет несовместима с любым jQuery, который вы, возможно, использовали. Конечно, если вы уже используете Prototype, а не jQuery, это не будет проблемой.
РЕДАКТИРОВАТЬ: Также есть это, который является портом строковых утилит Prototype для jQuery:
Моя функция чистого JS:
/**
* HTML entities encode
*
* @param {string} str Input text
* @return {string} Filtered text
*/
function htmlencode (str){
var div = document.createElement('div');
div.appendChild(document.createTextNode(str));
return div.innerHTML;
}
Используя некоторые из других ответов здесь, я сделал версию, которая заменяет все соответствующие символы за один проход, независимо от количества различных кодированных символов (только один вызов для replace()), поэтому будет быстрее для больших строк.
Он не полагается на DOM API для существования или в других библиотеках.
window.encodeHTML = (function() {
function escapeRegex(s) {
return s.replace(/[-\/\\^$*+?.()|[\]{}]/g, '\\$&');
}
var encodings = {
'&' : '&',
'"' : '"',
'\'' : ''',
'<' : '<',
'>' : '>',
'\\' : '/'
};
function encode(what) { return encodings[what]; };
var specialChars = new RegExp('[' +
escapeRegex(Object.keys(encodings).join('')) +
']', 'g');
return function(text) { return text.replace(specialChars, encode); };
})();
Запустив это однажды, вы можете позвонить
encodeHTML('<>&"\'')
Чтобы получить <>&"'
Выбор того, что escapeHTML() в prototype.js
Добавление этого скрипта поможет вам избежатьHTML:
String.prototype.escapeHTML = function() {
return this.replace(/&/g,'&').replace(/</g,'<').replace(/>/g,'>')
}
теперь вы можете вызвать метод escapeHTML для строк в вашем скрипте, например:
var escapedString = "<h1>this is HTML</h1>".escapeHTML();
// gives: "<h1>this is HTML</h1>"
Надеюсь, что это поможет любому, кто ищет простое решение без необходимости включать весь prototype.js
Ещё вопросы
- 1JAX-WS + Hibernate + JAXB: как избежать исключения LazyInitializationException во время сортировки
- 0window.location.href или $ (location) .attr ('href') и польские диакритические знаки
- 0ошибка в bind_param, количество параметров в подготовленном утверждении не совпадает
- 1Python, построить три графика в plt.subplots (2,2)?
- 1Панель инструментов Android может изменить цвет кнопки назад, но не цвет заголовка
- 1Создать один CSV из двух файлов CSV со значениями X и Y в Python
- 0Скомпилируйте Qt-проект и включите библиотеки Qt
- 0Получение Mac (системного физического адреса) адреса успешно на локальном хосте, но не на сервере
- 0Как проверить ввод в динамической таблице HTML?
- 0Вывод вектора списков в C ++
- 1ValueError: X.shape [1] = 2 должно быть равно 13, количество функций во время обучения
- 0Не вернуть родителя с помощью фильтра в jquery
- 0Структура данных для обработки списка из 3 целых чисел
- 0Перебирать разные типы коллекций в классе
- 0Встроенное переполнение: скрыто, только частично работает
- 0почему ссылки cdn ставятся внизу индексного файла
- 1Сбой приложения после активности в фоновом режиме
- 1заглушка метода для всех экземпляров класса
- 1Валюта Formatter не является дружественным к пользователю / интуитивно понятным. Случайно увеличивает поле ввода
- 0Назначение значения?
- 0PHP класс не загружается, когда файл класса включен
- 0Создание функции jquery для анимации непрозрачности изображения не работает
- 1Правильно установить приоритеты между правилами и терминалами в грамматике для жаворонка
- 0Не удается заставить PHP password_hash api работать [дубликаты]
- 0проблема при передаче аргумента из директивы в контроллер
- 0Как выбрать ресурс с условием выполнения двух отношений в объединенной таблице
- 0Как добавить сервисную ссылку в библиотеку C #?
- 1Movidius и шаблон соответствия
- 0Angularjs фильтр накопительный массив
- 1Jsoup удалить конкретный идентификатор TR
- 0Настройка постоянной переменной MariaDB
- 0Как управлять вертикальным выпадающим меню при наведении курсора?
- 1Java SE Truth API Morena7
- 1Java - проблемы с подстрокой
- 0ASP.net MVC Можете ли вы перегрузить HttpPost Index ()?
- 1Как выбрать тот же вариант, который был выбран на другой странице
- 1Почему магическая функция ipython `% timeit -n1 code_block` выполняет` code_block` несколько раз?
- 0Как перехватить / обработать исключения бэкэнда в AngularJS
- 1Извлечение Unicode-смайликов в список, Python 3.x
- 0Переключение класса правильно
- 0Laravel 5.5 Получить порядок сообщений по сумме голосов
- 1Местоположение включено, но слушатель ничего не возвращает
- 0Получение contact.id после сохранения контактного плагина Cordova
- 0Отношения многие ко многим по умолчанию «все»
- 0конструктор и конструктор копирования
- 0Обновление номера в подсказках jQuery UI
- 1Как ASP.NET вызывает события на клиенте?
- 0отрицательные расстояния с cv :: HoughLines?
- 0Несколько вставок в цикле codeigniter
- 1лямбда-выражения для сравнения, содержит ли строка [] заданную строку
