Быстрая бета-версия: сортировка массивов
Я реализовывал алгоритм в Swift Beta и заметил, что производительность была очень плохой. Покопавшись глубже, я понял, что одним из узких мест является нечто такое же простое, как сортировка массивов. Соответствующая часть здесь:
let n = 1000000
var x = [Int](repeating: 0, count: n)
for i in 0..<n {
x[i] = random()
}
// start clock here
let y = sort(x)
// stop clock here
В C++ аналогичная операция занимает 0.06 с на моем компьютере.
В Python требуется 0,6 с (без трюков, просто y = sorted (x) для списка целых чисел).
В Swift требуется 6 секунд, если я скомпилирую его с помощью следующей команды:
xcrun swift -O3 -sdk 'xcrun --show-sdk-path --sdk macosx'
И это займет целых 88 секунд, если я скомпилирую его с помощью следующей команды:
xcrun swift -O0 -sdk 'xcrun --show-sdk-path --sdk macosx'
Синхронизация в Xcode со сборками "Release" и "Debug" аналогична.
Что здесь не так? Я мог понять некоторую потерю производительности по сравнению с C++, но не 10-кратное замедление по сравнению с чистым Python.
Изменить: mweathers заметил, что изменение -O3 на -Ofast делает этот код работать почти так же быстро, как версия C++! Однако -Ofast меняет семантику языка - в моем тестировании он отключил проверки на целочисленные переполнения и переполнения индексации массивов. Например, с -Ofast следующий код Swift выполняется без сбоев (и выводит мусор):
let n = 10000000
print(n*n*n*n*n)
let x = [Int](repeating: 10, count: n)
print(x[n])
Так что -Ofast не то, что мы хотим; Суть Swift в том, что у нас есть защитные сетки. Конечно, системы безопасности оказывают некоторое влияние на производительность, но они не должны делать программы в 100 раз медленнее. Помните, что Java уже проверяет границы массивов, и в типичных случаях замедление в -ftrapv раза меньше. А в Clang и GCC мы получили -ftrapv для проверки (целочисленных) целочисленных переполнений, и это не так медленно, или.
Отсюда вопрос: как мы можем получить разумную производительность в Swift, не теряя сетей безопасности?
Редактировать 2: я сделал еще несколько тестов, с очень простыми циклами по линии
for i in 0..<n {
x[i] = x[i] ^ 12345678
}
(Здесь операция xor существует просто для того, чтобы мне было легче найти соответствующий цикл в коде сборки. Я попытался выбрать операцию, которую легко обнаружить, но при этом "безвредную" в том смысле, что она не должна требовать каких-либо проверок, связанных с к целочисленным переполнениям.)
Опять же, была огромная разница в производительности между -O3 и -Ofast. Итак, я посмотрел на код сборки:
-
С
-Ofastя получаю почти то, что ожидал. Соответствующая часть представляет собой цикл с 5 инструкциями на машинном языке. -
С
-O3я получаю то, что было за пределами моего самого смелого воображения. Внутренний цикл занимает 88 строк кода сборки. Я не пытался понять все это, но наиболее подозрительными частями являются 13 вызовов "callq _swift_retain" и еще 13 вызовов "callq _swift_release". То есть 26 вызовов подпрограммы во внутреннем цикле !
Редактировать 3: В комментариях Ферруччо попросил критерии, которые являются справедливыми в том смысле, что они не полагаются на встроенные функции (например, сортировка). Я думаю, что следующая программа является довольно хорошим примером:
let n = 10000
var x = [Int](repeating: 1, count: n)
for i in 0..<n {
for j in 0..<n {
x[i] = x[j]
}
}
Здесь нет арифметики, поэтому нам не нужно беспокоиться о целочисленных переполнениях. Единственное, что мы делаем, это просто множество ссылок на массивы. И результаты здесь - Свифт -O3 теряет почти в 500 раз по сравнению с -Ofast:
- C++ -O3: 0,05 с
- C++ -O0: 0,4 с
- Ява: 0,2 с
- Питон с PyPy: 0,5 с
- Питон: 12 с
- Свифт -Ofast: 0,05 с
- Свифт -O3: 23 с
- Свифт -O0: 443 с
(Если вы обеспокоены тем, что компилятор может полностью оптимизировать бессмысленные циклы, вы можете изменить его, например, на x[i] ^= x[j], и добавить оператор print, который выводит x[0]. Это ничего не меняет; сроки будут очень похожи.)
И да, здесь реализация Python была глупой чистой реализацией Python со списком целых и вложенных в циклы. Это должно быть намного медленнее, чем неоптимизированный Свифт. Кажется, что-то серьезно сломано с помощью Swift и индексации массивов.
Редактировать 4: Эти проблемы (а также некоторые другие проблемы с производительностью), кажется, были исправлены в Xcode 6 beta 5.
Для сортировки у меня теперь есть следующие тайминги:
- clang++ -O3: 0,06 с
- swiftc -Ofast: 0,1 с
- swiftc -O: 0,1 с
- swiftc: 4 с
Для вложенных циклов:
- clang++ -O3: 0,06 с
- swiftc -Ofast: 0,3 с
- swiftc -O: 0,4 с
- swiftc: 540 с
Кажется, что больше нет причин использовать небезопасный -Ofast (он же -Ounchecked); -O производит одинаково хороший код.
-
19Вот еще один вопрос «Свифт в 100 раз медленнее, чем С»: stackoverflow.com/questions/24102609/…Jukka Suomela
-
16А вот обсуждение маркетингового материала Apple, связанного с хорошей производительностью Swift в сортировке: programmers.stackexchange.com/q/242816/913Jukka Suomela
9 ответов
В этом тесте Dr Swift 1.0 теперь работает так же быстро, как и C, используя уровень оптимизации релиза по умолчанию [-O].
Вот быстрая сортировка на месте в Swift Beta:
func quicksort_swift(inout a:CInt[], start:Int, end:Int) {
if (end - start < 2){
return
}
var p = a[start + (end - start)/2]
var l = start
var r = end - 1
while (l <= r){
if (a[l] < p){
l += 1
continue
}
if (a[r] > p){
r -= 1
continue
}
var t = a[l]
a[l] = a[r]
a[r] = t
l += 1
r -= 1
}
quicksort_swift(&a, start, r + 1)
quicksort_swift(&a, r + 1, end)
}
И то же самое в C:
void quicksort_c(int *a, int n) {
if (n < 2)
return;
int p = a[n / 2];
int *l = a;
int *r = a + n - 1;
while (l <= r) {
if (*l < p) {
l++;
continue;
}
if (*r > p) {
r--;
continue;
}
int t = *l;
*l++ = *r;
*r-- = t;
}
quicksort_c(a, r - a + 1);
quicksort_c(l, a + n - l);
}
Обе работы:
var a_swift:CInt[] = [0,5,2,8,1234,-1,2]
var a_c:CInt[] = [0,5,2,8,1234,-1,2]
quicksort_swift(&a_swift, 0, a_swift.count)
quicksort_c(&a_c, CInt(a_c.count))
// [-1, 0, 2, 2, 5, 8, 1234]
// [-1, 0, 2, 2, 5, 8, 1234]
Оба вызываются в той же программе, что и написаны.
var x_swift = CInt[](count: n, repeatedValue: 0)
var x_c = CInt[](count: n, repeatedValue: 0)
for var i = 0; i < n; ++i {
x_swift[i] = CInt(random())
x_c[i] = CInt(random())
}
let swift_start:UInt64 = mach_absolute_time();
quicksort_swift(&x_swift, 0, x_swift.count)
let swift_stop:UInt64 = mach_absolute_time();
let c_start:UInt64 = mach_absolute_time();
quicksort_c(&x_c, CInt(x_c.count))
let c_stop:UInt64 = mach_absolute_time();
Это преобразует абсолютное время в секунды:
static const uint64_t NANOS_PER_USEC = 1000ULL;
static const uint64_t NANOS_PER_MSEC = 1000ULL * NANOS_PER_USEC;
static const uint64_t NANOS_PER_SEC = 1000ULL * NANOS_PER_MSEC;
mach_timebase_info_data_t timebase_info;
uint64_t abs_to_nanos(uint64_t abs) {
if ( timebase_info.denom == 0 ) {
(void)mach_timebase_info(&timebase_info);
}
return abs * timebase_info.numer / timebase_info.denom;
}
double abs_to_seconds(uint64_t abs) {
return abs_to_nanos(abs) / (double)NANOS_PER_SEC;
}
Вот сводка уровней оптимизации компилятора:
[-Onone] no optimizations, the default for debug.
[-O] perform optimizations, the default for release.
[-Ofast] perform optimizations and disable runtime overflow checks and runtime type checks.
Время в секундах с [-O нет] для n = 10_000:
Swift: 0.895296452
C: 0.001223848
Вот встроенная сортировка Swift() для n = 10_000:
Swift_builtin: 0.77865783
Вот [-O] для n = 10_000:
Swift: 0.045478346
C: 0.000784666
Swift_builtin: 0.032513488
Как видите, производительность Swift улучшилась в 20 раз.
Согласно ответу Мвезерса, установка [-O fast] дает реальную разницу, приводя к этим временам для n = 10_000:
Swift: 0.000706745
C: 0.000742374
Swift_builtin: 0.000603576
И для n = 1_000_000:
Swift: 0.107111846
C: 0.114957179
Swift_sort: 0.092688548
Для сравнения это с [-O none] для n = 1_000_000:
Swift: 142.659763258
C: 0.162065333
Swift_sort: 114.095478272
Таким образом, на этом этапе разработки Swift без оптимизации был почти в 1000 раз медленнее, чем C. С другой стороны, с обоими компиляторами, установленными на [-O fast], Swift действительно работал по крайней мере так же хорошо, если не немного лучше, чем C.
Было отмечено, что [-O fast] изменяет семантику языка, делая его потенциально небезопасным. Вот что Apple заявляет в заметках о выпуске Xcode 5.0:
Новый уровень оптимизации -O fast, доступный в LLVM, обеспечивает агрессивную оптимизацию. -O быстро ослабляет некоторые консервативные ограничения, в основном для операций с плавающей запятой, которые безопасны для большей части кода. Это может дать значительные высокопроизводительные выигрыши от компилятора.
Они почти защищают это. Будь это мудро или нет, я не могу сказать, но из того, что я могу сказать, кажется достаточно разумным использовать [-O fast] в релизе, если вы не выполняете высокоточную арифметику с плавающей запятой и уверены, что нет в вашей программе возможно переполнение целого числа или массива. Если вам нужна высокая производительность и проверки переполнения/точная арифметика, выберите другой язык.
БЕТА 3 ОБНОВЛЕНИЕ:
n = 10_000 с [-O]:
Swift: 0.019697268
C: 0.000718064
Swift_sort: 0.002094721
Swift в целом работает немного быстрее, и похоже, что встроенная сортировка Swift значительно изменилась.
ЗАКЛЮЧИТЕЛЬНОЕ ОБНОВЛЕНИЕ:
[-O нет]:
Swift: 0.678056695
C: 0.000973914
[-O]:
Swift: 0.001158492
C: 0.001192406
[-O не проверено]:
Swift: 0.000827764
C: 0.001078914
-
24Использование -emit-sil для вывода промежуточного кода SIL показывает, что сохраняется (ага, переполнение стека делает невозможным форматирование). Это внутренний буферный объект в массиве. Это определенно звучит как ошибка оптимизатора, оптимизатор ARC должен быть в состоянии удалить остатки без -Ofast.
-
0Я просто не согласен с тем, что мы должны использовать другой язык, если хотим использовать оптимизацию Ofast. При выборе другого языка, такого как C., ему придется аналогичным образом решить вопрос о проверке границ и других мелких проблем. Swift - это круто именно потому, что он должен быть безопасным по умолчанию и, при необходимости, быстрым и небезопасным, если это необходимо. Это позволяет программисту также отлаживать ваш код, чтобы убедиться, что все в порядке, и скомпилировать с использованием Ofast. Возможность использования современных стандартов и все же обладать мощью «небезопасного» языка, такого как С, очень крута.
TL; DR: Да, единственная реализация языка Swift выполняется медленно, прямо сейчас. Если вам нужен быстрый, числовой (и другие типы кода, предположительно) код, просто перейдите к другому. В будущем вы должны переоценить свой выбор. Это может быть достаточно хорошим для большинства прикладных программ, написанных на более высоком уровне.
Из того, что я вижу в SIL и LLVM IR, похоже, им нужна куча оптимизаций для удаления сохранений и выпусков, которые могут быть реализованы в Clang (для Objective-C), но они еще не портировали их. То, что теория, с которой я иду (на данный момент... Мне все еще нужно подтвердить, что Clang что-то делает с ней), поскольку профайлер, запущенный в последнем тестовом случае этого вопроса, дает этот "красивый" результат:
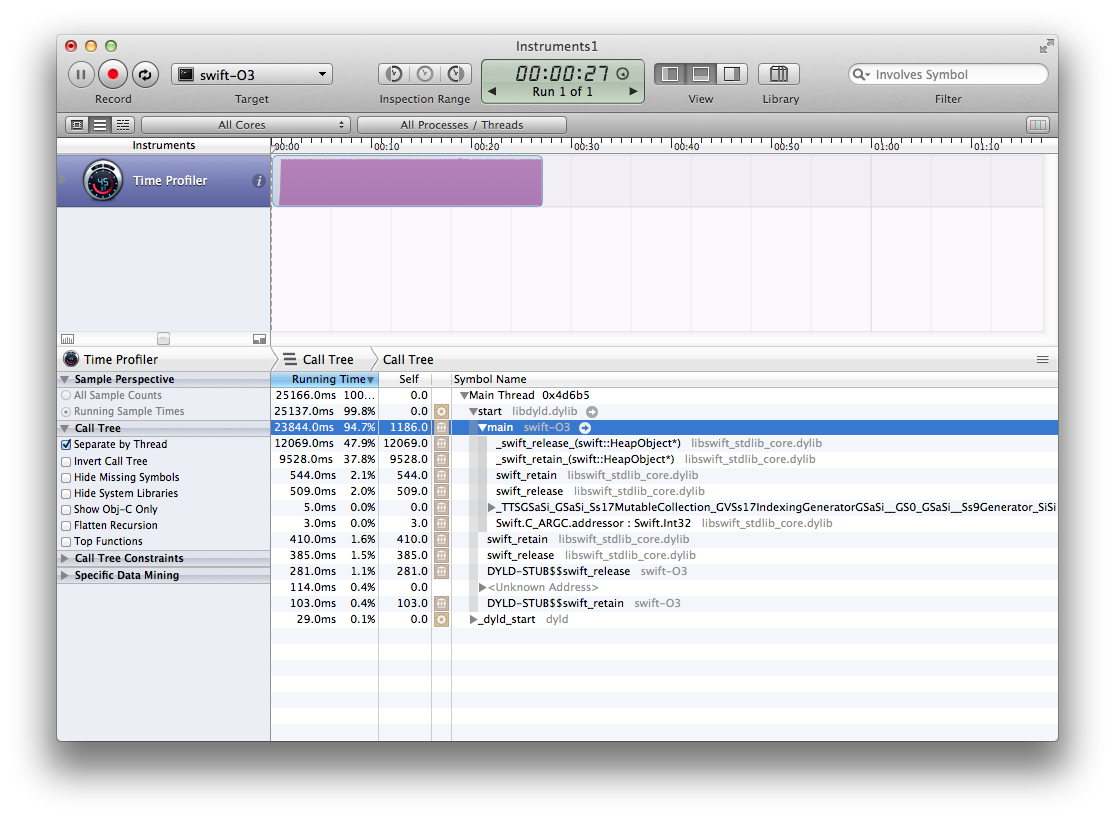
Как было сказано многими другими, -Ofast абсолютно небезопасен и изменяет семантику языка. Для меня это на "Если вы собираетесь использовать это, просто используйте другой язык". Я буду переоценивать этот выбор позже, если он изменится.
-O3 дает нам кучу вызовов swift_retain и swift_release, которые, честно говоря, не выглядят так, как будто они должны быть там для этого примера. Оптимизатор должен был исключить (большинство из них) AFAICT, поскольку он знает большую часть информации о массиве и знает, что он имеет (по крайней мере) сильную ссылку на него.
Он не должен выделять больше, если он даже не вызывает функции, которые могут освобождать объекты. Я не думаю, что конструктор массива может вернуть массив, который меньше запрашиваемого, что означает, что много проверок, которые были выбраны, бесполезны. Он также знает, что целое число никогда не будет выше 10k, поэтому проверки переполнения могут быть оптимизированы (не из-за -Ofast странности, а из-за семантики языка (ничто иное не меняет этот var и не может получить к нему доступ, а добавление до 10k безопасно для типа Int).
Компилятор, возможно, не сможет распаковать массив или элементы массива, хотя, поскольку они передаются в sort(), который является внешней функцией и должен получать ожидаемые аргументы. Это заставит нас косвенно использовать значения Int, которые заставили бы его пойти немного медленнее. Это может измениться, если функция sort() generic (не в методе с несколькими методами) была доступна компилятору и была встроена.
Это очень новый (общедоступный) язык, и он проходит через то, что я предполагаю, это множество изменений, так как есть люди (сильно), связанные с языком Swift, требующие обратной связи, и все говорят, что язык не является закончен и будет изменен.
Используемый код:
import Cocoa
let swift_start = NSDate.timeIntervalSinceReferenceDate();
let n: Int = 10000
let x = Int[](count: n, repeatedValue: 1)
for i in 0..n {
for j in 0..n {
let tmp: Int = x[j]
x[i] = tmp
}
}
let y: Int[] = sort(x)
let swift_stop = NSDate.timeIntervalSinceReferenceDate();
println("\(swift_stop - swift_start)s")
P.S: Я не эксперт в Objective-C и не все средства из Cocoa, Objective-C или время выполнения Swift. Я мог бы также предположить некоторые вещи, которые я не писал.
-
0Однако компилятор не сможет распаковать массив или элементы массива, поскольку они передаются в sort (), которая является внешней функцией и должна получить ожидаемые аргументы. Это не должно иметь значения для относительно хорошего компилятора. Передача метаданных (в указателе - 64 бита предлагает много уровней) о реальных данных и их ветвление в вызываемой функции.
-
2Что именно делает
-Ofast«абсолютно небезопасным»? Предполагая, что вы знаете, как проверить свой код и исключить переполнение.
Я решил посмотреть на это для удовольствия, и вот время, которое я получаю:
Swift 4.0.2 : 0.83s (0.74s with `-Ounchecked`)
C++ (Apple LLVM 8.0.0): 0.74s
Swift
// Swift 4.0 code
import Foundation
func doTest() -> Void {
let arraySize = 10000000
var randomNumbers = [UInt32]()
for _ in 0..<arraySize {
randomNumbers.append(arc4random_uniform(UInt32(arraySize)))
}
let start = Date()
randomNumbers.sort()
let end = Date()
print(randomNumbers[0])
print("Elapsed time: \(end.timeIntervalSince(start))")
}
doTest()
Результаты:
Swift 1.1
xcrun swiftc --version
Swift version 1.1 (swift-600.0.54.20)
Target: x86_64-apple-darwin14.0.0
xcrun swiftc -O SwiftSort.swift
./SwiftSort
Elapsed time: 1.02204304933548
Swift 1.2
xcrun swiftc --version
Apple Swift version 1.2 (swiftlang-602.0.49.6 clang-602.0.49)
Target: x86_64-apple-darwin14.3.0
xcrun -sdk macosx swiftc -O SwiftSort.swift
./SwiftSort
Elapsed time: 0.738763988018036
Swift 2.0
xcrun swiftc --version
Apple Swift version 2.0 (swiftlang-700.0.59 clang-700.0.72)
Target: x86_64-apple-darwin15.0.0
xcrun -sdk macosx swiftc -O SwiftSort.swift
./SwiftSort
Elapsed time: 0.767306983470917
Кажется, что такая же производительность, если я скомпилирую с -Ounchecked.
Swift 3.0
xcrun swiftc --version
Apple Swift version 3.0 (swiftlang-800.0.46.2 clang-800.0.38)
Target: x86_64-apple-macosx10.9
xcrun -sdk macosx swiftc -O SwiftSort.swift
./SwiftSort
Elapsed time: 0.939633965492249
xcrun -sdk macosx swiftc -Ounchecked SwiftSort.swift
./SwiftSort
Elapsed time: 0.866258025169373
Кажется, что была регрессия производительности от Swift 2.0 до Swift 3.0, и я также вижу разницу между -O и -Ounchecked в первый раз.
Swift 4.0
xcrun swiftc --version
Apple Swift version 4.0.2 (swiftlang-900.0.69.2 clang-900.0.38)
Target: x86_64-apple-macosx10.9
xcrun -sdk macosx swiftc -O SwiftSort.swift
./SwiftSort
Elapsed time: 0.834299981594086
xcrun -sdk macosx swiftc -Ounchecked SwiftSort.swift
./SwiftSort
Elapsed time: 0.742045998573303
Swift 4 снова улучшает производительность, сохраняя зазор между -O и -Ounchecked. -O -whole-module-optimization, похоже, не имеет значения.
С++
#include <chrono>
#include <iostream>
#include <vector>
#include <cstdint>
#include <stdlib.h>
using namespace std;
using namespace std::chrono;
int main(int argc, const char * argv[]) {
const auto arraySize = 10000000;
vector<uint32_t> randomNumbers;
for (int i = 0; i < arraySize; ++i) {
randomNumbers.emplace_back(arc4random_uniform(arraySize));
}
const auto start = high_resolution_clock::now();
sort(begin(randomNumbers), end(randomNumbers));
const auto end = high_resolution_clock::now();
cout << randomNumbers[0] << "\n";
cout << "Elapsed time: " << duration_cast<duration<double>>(end - start).count() << "\n";
return 0;
}
Результаты:
Apple Clang 6.0
clang++ --version
Apple LLVM version 6.0 (clang-600.0.54) (based on LLVM 3.5svn)
Target: x86_64-apple-darwin14.0.0
Thread model: posix
clang++ -O3 -std=c++11 CppSort.cpp -o CppSort
./CppSort
Elapsed time: 0.688969
Apple Clang 6.1.0
clang++ --version
Apple LLVM version 6.1.0 (clang-602.0.49) (based on LLVM 3.6.0svn)
Target: x86_64-apple-darwin14.3.0
Thread model: posix
clang++ -O3 -std=c++11 CppSort.cpp -o CppSort
./CppSort
Elapsed time: 0.670652
Apple Clang 7.0.0
clang++ --version
Apple LLVM version 7.0.0 (clang-700.0.72)
Target: x86_64-apple-darwin15.0.0
Thread model: posix
clang++ -O3 -std=c++11 CppSort.cpp -o CppSort
./CppSort
Elapsed time: 0.690152
Apple Clang 8.0.0
clang++ --version
Apple LLVM version 8.0.0 (clang-800.0.38)
Target: x86_64-apple-darwin15.6.0
Thread model: posix
clang++ -O3 -std=c++11 CppSort.cpp -o CppSort
./CppSort
Elapsed time: 0.68253
Apple Clang 9.0.0
clang++ --version
Apple LLVM version 9.0.0 (clang-900.0.38)
Target: x86_64-apple-darwin16.7.0
Thread model: posix
clang++ -O3 -std=c++11 CppSort.cpp -o CppSort
./CppSort
Elapsed time: 0.736784
Вердикт
На момент написания этой статьи Swift sort быстро, но не так быстро, как С++-сортировка при компиляции с -O, с указанными выше компиляторами и библиотеками. С -Ounchecked он выглядит так же быстро, как С++ в Swift 4.0.2 и Apple LLVM 9.0.0.
-
0На самом деле вы никогда не должны вызывать vector :: reserve (), прежде чем вставлять десять миллионов элементов.
-
0Может быть! Только сортировка рассчитывается в данный момент.
От The Swift Programming Language:
Стандартная библиотека Sort Function Swifts предоставляет функцию, называемую sort, который сортирует массив значений известного типа, основанный на вывода закрывающейся сортировки, которую вы предоставляете. После завершения сортировка, функция сортировки возвращает новый массив того же тип и размер, как старый, с его элементами в правильной сортировке порядок.
Функция sort имеет два объявления.
Объявление по умолчанию, которое позволяет вам указать закрытие сравнения:
func sort<T>(array: T[], pred: (T, T) -> Bool) -> T[]
И второе объявление, которое принимает только один параметр (массив) и "жестко запрограммировано для использования меньше, чем компаратор".
func sort<T : Comparable>(array: T[]) -> T[]
Example:
sort( _arrayToSort_ ) { $0 > $1 }
Я протестировал модифицированную версию вашего кода на игровой площадке с добавленным закрытием, чтобы я мог более внимательно отслеживать эту функцию, и я обнаружил, что с n установленным до 1000, закрытие вызывалось примерно 11 000 раз.
let n = 1000
let x = Int[](count: n, repeatedValue: 0)
for i in 0..n {
x[i] = random()
}
let y = sort(x) { $0 > $1 }
Это не эффективная функция, я бы рекомендовал использовать лучшую реализацию функции сортировки.
EDIT:
Я просмотрел страницу Quicksort wikipedia и написал для нее реализацию Swift. Вот полная программа, которую я использовал (на игровой площадке)
import Foundation
func quickSort(inout array: Int[], begin: Int, end: Int) {
if (begin < end) {
let p = partition(&array, begin, end)
quickSort(&array, begin, p - 1)
quickSort(&array, p + 1, end)
}
}
func partition(inout array: Int[], left: Int, right: Int) -> Int {
let numElements = right - left + 1
let pivotIndex = left + numElements / 2
let pivotValue = array[pivotIndex]
swap(&array[pivotIndex], &array[right])
var storeIndex = left
for i in left..right {
let a = 1 // <- Used to see how many comparisons are made
if array[i] <= pivotValue {
swap(&array[i], &array[storeIndex])
storeIndex++
}
}
swap(&array[storeIndex], &array[right]) // Move pivot to its final place
return storeIndex
}
let n = 1000
var x = Int[](count: n, repeatedValue: 0)
for i in 0..n {
x[i] = Int(arc4random())
}
quickSort(&x, 0, x.count - 1) // <- Does the sorting
for i in 0..n {
x[i] // <- Used by the playground to display the results
}
Используя это с n = 1000, я обнаружил, что
- quickSort() вызвали около 650 раз,
- было сделано около 6000 свопов,
- и есть около 10000 сравнений
Кажется, что встроенный метод сортировки (или близок к) быстро сортируется и очень медленный...
-
16Возможно, я совершенно не прав, но, согласно en.wikipedia.org/wiki/Quicksort , среднее число сравнений в Quicksort составляет
2*n*log(n). Это 13815 сравнений для сортировки n = 1000 элементов, поэтому, если функция сравнения вызывается примерно 11000 раз, это не так уж плохо. -
5Также Apple утверждала, что «сортировка сложных объектов» (что бы это ни было) в 3,9 раза быстрее в Swift, чем в Python. Поэтому не должно быть необходимости искать «лучшую функцию сортировки». - Но Swift все еще находится в разработке ...
С Xcode 7 вы можете включить Fast, Whole Module Optimization. Это должно немедленно увеличить производительность.

Ожидается производительность Swift Array:
Я написал собственный тест, сравнивающий Swift с C/ Objective-C. В моем тесте вычисляются простые числа. Он использует массив предыдущих простых чисел для поиска простых факторов в каждом новом кандидате, поэтому он довольно быстро. Тем не менее, он делает TONS чтения массива и меньше записывает в массивы.
Я изначально сделал этот тест против Swift 1.2. Я решил обновить проект и запустить его против Swift 2.0.
Проект позволяет выбирать между использованием обычных быстрых массивов и использованием буферов небезопасной памяти Swift с использованием семантики массива.
Для C/ Objective-C вы можете выбрать использование массивов NSArrays или C malloc'ed.
Результаты тестов, похоже, очень похожи на самую быструю, минимальную оптимизацию кода ([-0s]) или самую быструю, агрессивную ([-0fast]) оптимизацию.
Производительность Swift 2.0 по-прежнему ужасна, когда оптимизация кода отключена, тогда как производительность C/ Objective-C умеренно медленнее.
Суть в том, что вычисления на основе массива C malloc'd являются самыми быстрыми, на скромном уровне
Swift с небезопасными буферами занимает около 1,19X - 1,20X длиннее массивов C malloc'd при использовании самой быстрой и минимальной оптимизации кода. разница кажется немного меньшей с быстрой, агрессивной оптимизацией (Swift больше похож на 1,18x на 1,16x больше, чем на C.
Если вы используете регулярные массивы Swift, разница с C немного больше. (Swift занимает ~ 1.22 до 1.23 дольше.)
Регулярные массивы Swift DRAMATICALLY быстрее, чем они были в Swift 1.2/Xcode 6. Их производительность настолько близка к небезопасным буферным массивам Swift, что использование небезопасных буферов памяти на самом деле больше не стоит того,
BTW, Objective-C Производительность NSArray воняет. Если вы собираетесь использовать собственные объекты контейнера на обоих языках, Swift быстрее DRAMATICALLY.
Вы можете проверить мой проект на github в SwiftPerformanceBenchmark
У этого есть простой пользовательский интерфейс, который упрощает сбор статистики.
Интересно, что сортировка, по-видимому, немного быстрее в Swift, чем в C, но этот алгоритм с простым числом еще быстрее в Swift.
Основная проблема, которая упоминается другими, но не вызванная достаточно, заключается в том, что -O3 ничего не делает в Swift (и никогда не имеет), поэтому при компиляции с тем, что она эффективно не оптимизирована (-Onone).
Имена опций со временем менялись, поэтому некоторые другие ответы имеют устаревшие флаги для вариантов сборки. Правильные параметры тока (Swift 2.2):
-Onone // Debug - slow
-O // Optimised
-O -whole-module-optimization //Optimised across files
Оптимизация всего модуля имеет более медленную компиляцию, но может оптимизировать файлы в модуле, то есть в пределах каждой структуры и внутри реального кода приложения, но не между ними. Вы должны использовать это для любой критической производительности)
Вы также можете отключить проверки безопасности еще быстрее, но со всеми утверждениями и предпосылками не просто отключены, но оптимизированы на основе их правильности. Если вы когда-либо ударили утверждение, это означает, что вы находитесь в поведении undefined. Используйте с особой осторожностью и только если вы определите, что ускорение скорости стоит для вас (путем тестирования). Если вы считаете это ценным для некоторого кода, я рекомендую разделить этот код на отдельную структуру и отключить проверку безопасности этого модуля.
-
0Этот ответ сейчас устарел. Начиная с Swift 4.1, опция оптимизации всего модуля представляет собой отдельное логическое значение, которое можно комбинировать с другими настройками, и теперь есть опция -Os для оптимизации по размеру. Я могу обновить, когда у меня будет время, чтобы проверить точные флажки опций.
func partition(inout list : [Int], low: Int, high : Int) -> Int {
let pivot = list[high]
var j = low
var i = j - 1
while j < high {
if list[j] <= pivot{
i += 1
(list[i], list[j]) = (list[j], list[i])
}
j += 1
}
(list[i+1], list[high]) = (list[high], list[i+1])
return i+1
}
func quikcSort(inout list : [Int] , low : Int , high : Int) {
if low < high {
let pIndex = partition(&list, low: low, high: high)
quikcSort(&list, low: low, high: pIndex-1)
quikcSort(&list, low: pIndex + 1, high: high)
}
}
var list = [7,3,15,10,0,8,2,4]
quikcSort(&list, low: 0, high: list.count-1)
var list2 = [ 10, 0, 3, 9, 2, 14, 26, 27, 1, 5, 8, -1, 8 ]
quikcSort(&list2, low: 0, high: list2.count-1)
var list3 = [1,3,9,8,2,7,5]
quikcSort(&list3, low: 0, high: list3.count-1)
Это мой блог о Quick Sort- Github образец Quick-Sort
Вы можете взглянуть на алгоритм разбиения Lomuto в разделе Разделение списка. Написано в Swift
Swift 4.1 представляет новый -Osize оптимизации -Osize.
В Swift 4.1 компилятор теперь поддерживает новый режим оптимизации, который позволяет использовать специальные оптимизации для уменьшения размера кода.
Компилятор Swift поставляется с мощными оптимизациями. При компиляции с -O компилятор пытается преобразовать код так, чтобы он выполнялся с максимальной производительностью. Однако такое улучшение производительности во время выполнения может иногда сопровождаться компромиссом увеличения размера кода. В новом режиме оптимизации -Osize пользователь имеет возможность компилировать для минимального размера кода, а не для максимальной скорости.
Чтобы включить режим оптимизации размера в командной строке, используйте -Osize вместо -O.
Дальнейшее чтение: https://swift.org/blog/osize/
Ещё вопросы
- 0Как я могу получить URL входного файла?
- 0Как расширить многоуровневые div с помощью javascript и сохранить расширенное условие в URL для совместного использования ссылок или ручного копирования / прошлого
- 1Как сохранить цветовую шкалу d3 с разрывом и повторным соединением ссылок
- 0JQuery анимация не работает
- 0TMXTiledMap показывает пустой экран
- 1Большие проблемы с памятью матрицы
- 0ионное представление содержимого <ion-slide-box>
- 1Asp.Net MVC отправляет JSON как строку, всегда усеченную на сервере
- 1ngModel не может правильно определить изменения массива
- -1показ jQuery не определен, даже если загружен файл jQuery
- 1Как отслеживать и увеличивать количество дубликатов, используя hashmap
- 0Ошибка получения компоновщика при создании экземпляра класса шаблона
- 0Невозможно войти в phpMyAdmin
- 1Android: как подключить Studio к виртуальному устройству Genymotion?
- 0Ось даты JQPlot не представляет график
- 0Выполнение модуля C ++ CGAL, который вызывается из Python
- 0Может ли установка boost испортить мои программы?
- 1Как установить значок на значок приложения программно?
- 1В Google Appmaker не удается получить requestAnimationFrame работает
- 1Начальные проблемы с перекрашиванием и подсчет соседних проблем
- 0Наложение jQuery .fadeIn () (после просмотра другой вкладки браузера)
- 1Структурированный массив Numpy не выполняет основные операции с NumPy
- 0php localhost почта не отправляется с использованием xampp
- 0Сравнение пользовательского ввода с некоторыми полями в массиве объектов JSON
- 1Система оценки фигуристов
- 0Как стилизовать 4 сетки на странице, если на моих страницах более 4 сеток?
- 0Безопасные ссылки при использовании пользовательского интерфейса маршрутизатора Angular Js
- 1Пропустить конвертацию сущностей при загрузке строки yaml (используя PyYAML)
- 0HTML-таблица и выравнивание границ
- 1Передача массива из js for loop в данные серии highcharts
- 1Speech to Text - сопоставить метку докладчика с соответствующей расшифровкой в ответе JSON
- 0Отправить одну форму для той же модели с множеством User_id, выбранным с окном select2 в рельсах 3
- 0Можно ли расширить имя переменной? PHP
- 0Как показать содержимое файла журнала в новом окне, когда мы нажимаем на ссылку весной mvc
- 1HashMaps достаточно быстро?
- 1SQL-запрос для проверки наличия определенного товара в нескольких таблицах
- 1Сканирование штрих-кода не работает с API видения
- 0Ошибка при выделении текста жирным и цветным шрифтом в JTextPane
- 1Express.js - обернуть каждое промежуточное ПО / маршрут в «декоратор»
- 0как я могу отобразить содержимое этой вкладки на основе события
- 0Слушатель потребляет ключи даже с холста?
- 1Как выбрать переменные в массиве (A) со значениями из переменной (B)
- 0Как preg_match, что число делится на 6,5 с помощью регулярного выражения
- 1Как я могу вставить магазин в панель инструментов панели?
- 1Python3: удалить подстроку между двумя символами-разделителями
- 1Как читать ObjectInputStream без знания того, что было сериализовано?
- 1Как создать персонализированный токен пользователя музыки в Apple Music?
- 0Фоны SVG не будут чрезмерно растягиваться, в отличие от других файлов изображений, таких как png
- 0Фронт-контроллер PHP и .htaccess с XAMPP и Windows
- 0почему при использовании сервиса не отображается предупреждение?
