Как мне прочитать / преобразовать InputStream в строку в Java?
Если у вас есть объект java.io.InputStream, как вы должны обработать этот объект и создать String?
Предположим, у меня есть InputStream который содержит текстовые данные, и я хочу преобразовать его в String, поэтому, например, я могу записать это в файл журнала.
Какой самый простой способ взять InputStream и преобразовать его в String?
public String convertStreamToString(InputStream is) {
// ???
}
-
763Мальчик, я абсолютно влюблен в Java, но этот вопрос возникает так часто, что вы могли бы подумать, что они просто поймут, что объединение потоков несколько затруднено и либо заставят помощников создавать различные комбинации, либо переосмыслить все это.Bill K
-
29Ответы на этот вопрос только работать , если вы хотите , чтобы прочитать содержимое потока , в полной мере (пока она не будет закрыта). Так как это не всегда подразумевается (запросы http с сохраняющим соединение соединением не будут закрыты), эти вызовы метода блокируются (без предоставления вам содержимого).f1sh
60 ответов
Хороший способ сделать это - использовать Apache commons IOUtils для копирования InputStream в StringWriter... что-то вроде
StringWriter writer = new StringWriter();
IOUtils.copy(inputStream, writer, encoding);
String theString = writer.toString();
или даже
// NB: does not close inputStream, you'll have to use try-with-resources for that
String theString = IOUtils.toString(inputStream, encoding);
Кроме того, вы можете использовать ByteArrayOutputStream если вы не хотите смешивать свои потоки и писатели
-
0я обнаружил исключение filenofound, когда я пытаюсь прочитать имя файла с именем файла «До_свидания» (русский язык), я пытаюсь с FileInputstream, но это не кабель, чтобы прочитать это имя файла из SDCard.
-
59Для разработчиков Android, похоже, что Android не поставляется с IOUtils от Apache. Так что вы можете рассмотреть возможность обращения к другим ответам.
Здесь можно использовать только стандартную библиотеку Java (обратите внимание, что поток не закрыт, ваш пробег может отличаться).
static String convertStreamToString(java.io.InputStream is) {
java.util.Scanner s = new java.util.Scanner(is).useDelimiter("\\A");
return s.hasNext() ? s.next() : "";
}
Я узнал об этом трюке из статьи "Трюки со сканером". Это работает потому, что Scanner перебирает токены в потоке, и в этом случае мы разделяем токены, используя "начало входной границы" (\ A), что дает нам только один токен для всего содержимого потока.
Обратите внимание: если вам нужно быть конкретным в отношении кодировки входного потока, вы можете предоставить второй аргумент конструктору Scanner который указывает, какой набор символов использовать (например, "UTF-8").
Наконечник шляпы идет также к Джейкобу, который однажды указал мне на упомянутую статью.
-
8Спасибо, для моей версии этого я добавил блок finally, который закрывает поток ввода, так что пользователю не нужно, так как вы закончили чтение ввода. Значительно упрощает код вызывающего абонента.
-
4@PavelRepin @Patrick, в моем случае, пустой inputStream вызвал NPE во время создания сканера. Мне пришлось добавить
if (is == null) return "";в самом начале метода; Я считаю, что этот ответ необходимо обновить, чтобы лучше обрабатывать нулевые inputStreams.
Подводя итог другим ответам, я нашел 11 основных способов сделать это (см. Ниже). И я написал некоторые тесты производительности (см. Результаты ниже):
Способы преобразования InputStream в строку:
-
Использование
IOUtils.toString(Apache Utils)String result = IOUtils.toString(inputStream, StandardCharsets.UTF_8); -
Использование
CharStreams(Guava)String result = CharStreams.toString(new InputStreamReader( inputStream, Charsets.UTF_8)); -
Использование
Scanner(JDK)Scanner s = new Scanner(inputStream).useDelimiter("\\A"); String result = s.hasNext() ? s.next() : ""; -
Использование Stream API (Java 8). Предупреждение. Это решение преобразует различные разрывы строк (например,
\r\n) в\n.String result = new BufferedReader(new InputStreamReader(inputStream)) .lines().collect(Collectors.joining("\n")); -
Использование параллельного Stream API (Java 8). Предупреждение. Это решение преобразует различные разрывы строк (например,
\r\n) в\n.String result = new BufferedReader(new InputStreamReader(inputStream)).lines() .parallel().collect(Collectors.joining("\n")); -
Использование
InputStreamReaderиStringBuilder(JDK)final int bufferSize = 1024; final char[] buffer = new char[bufferSize]; final StringBuilder out = new StringBuilder(); Reader in = new InputStreamReader(inputStream, "UTF-8"); for (; ; ) { int rsz = in.read(buffer, 0, buffer.length); if (rsz < 0) break; out.append(buffer, 0, rsz); } return out.toString(); -
Использование
StringWriterиIOUtils.copy(Apache Commons)StringWriter writer = new StringWriter(); IOUtils.copy(inputStream, writer, "UTF-8"); return writer.toString(); -
Использование
ByteArrayOutputStreamиinputStream.read(JDK)ByteArrayOutputStream result = new ByteArrayOutputStream(); byte[] buffer = new byte[1024]; int length; while ((length = inputStream.read(buffer)) != -1) { result.write(buffer, 0, length); } // StandardCharsets.UTF_8.name() > JDK 7 return result.toString("UTF-8"); -
Использование
BufferedReader(JDK). Предупреждение. Это решение преобразует различные разрывы строк (например,\n\r) в системное свойствоline.separator(например, в Windows - "\ r\n").String newLine = System.getProperty("line.separator"); BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream)); StringBuilder result = new StringBuilder(); boolean flag = false; for (String line; (line = reader.readLine()) != null; ) { result.append(flag? newLine: "").append(line); flag = true; } return result.toString(); -
Использование
BufferedInputStreamиByteArrayOutputStream(JDK)BufferedInputStream bis = new BufferedInputStream(inputStream); ByteArrayOutputStream buf = new ByteArrayOutputStream(); int result = bis.read(); while(result != -1) { buf.write((byte) result); result = bis.read(); } // StandardCharsets.UTF_8.name() > JDK 7 return buf.toString("UTF-8"); -
Использование
inputStream.read()иStringBuilder(JDK). Предупреждение. Это решение имеет проблемы с Unicode, например, с русским текстом (работает корректно только с текстом, отличным от Unicode)int ch; StringBuilder sb = new StringBuilder(); while((ch = inputStream.read()) != -1) sb.append((char)ch); reset(); return sb.toString();
Предупреждение:
-
Решения 4, 5 и 9 конвертируют разные разрывы строк в один.
-
Решение 11 не может работать корректно с текстом Unicode
Тесты производительности
Тесты производительности для небольшого String (длина = 175), url в github (режим = Среднее время, система = Linux, оценка 1,343 - лучшая):
Benchmark Mode Cnt Score Error Units
8. ByteArrayOutputStream and read (JDK) avgt 10 1,343 ± 0,028 us/op
6. InputStreamReader and StringBuilder (JDK) avgt 10 6,980 ± 0,404 us/op
10. BufferedInputStream, ByteArrayOutputStream avgt 10 7,437 ± 0,735 us/op
11. InputStream.read() and StringBuilder (JDK) avgt 10 8,977 ± 0,328 us/op
7. StringWriter and IOUtils.copy (Apache) avgt 10 10,613 ± 0,599 us/op
1. IOUtils.toString (Apache Utils) avgt 10 10,605 ± 0,527 us/op
3. Scanner (JDK) avgt 10 12,083 ± 0,293 us/op
2. CharStreams (guava) avgt 10 12,999 ± 0,514 us/op
4. Stream Api (Java 8) avgt 10 15,811 ± 0,605 us/op
9. BufferedReader (JDK) avgt 10 16,038 ± 0,711 us/op
5. parallel Stream Api (Java 8) avgt 10 21,544 ± 0,583 us/op
Тесты производительности для большой String (длина = 50100), url в github (режим = Среднее время, система = Linux, оценка 200 715 - лучшая):
Benchmark Mode Cnt Score Error Units
8. ByteArrayOutputStream and read (JDK) avgt 10 200,715 ± 18,103 us/op
1. IOUtils.toString (Apache Utils) avgt 10 300,019 ± 8,751 us/op
6. InputStreamReader and StringBuilder (JDK) avgt 10 347,616 ± 130,348 us/op
7. StringWriter and IOUtils.copy (Apache) avgt 10 352,791 ± 105,337 us/op
2. CharStreams (guava) avgt 10 420,137 ± 59,877 us/op
9. BufferedReader (JDK) avgt 10 632,028 ± 17,002 us/op
5. parallel Stream Api (Java 8) avgt 10 662,999 ± 46,199 us/op
4. Stream Api (Java 8) avgt 10 701,269 ± 82,296 us/op
10. BufferedInputStream, ByteArrayOutputStream avgt 10 740,837 ± 5,613 us/op
3. Scanner (JDK) avgt 10 751,417 ± 62,026 us/op
11. InputStream.read() and StringBuilder (JDK) avgt 10 2919,350 ± 1101,942 us/op
Графики (тесты производительности в зависимости от длины входного потока в системе Windows 7) 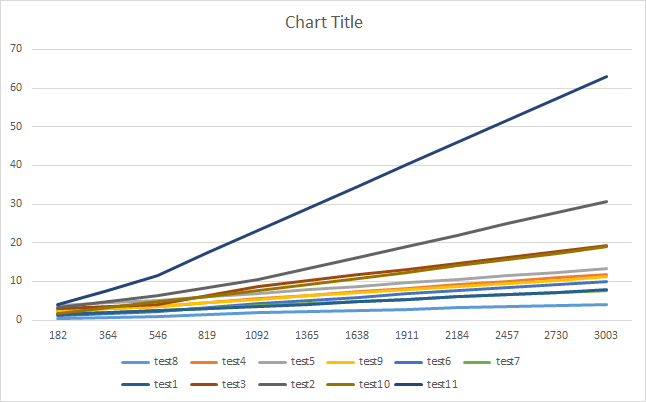
Тест производительности (среднее время) в зависимости от длины входного потока в системе Windows 7:
length 182 546 1092 3276 9828 29484 58968
test8 0.38 0.938 1.868 4.448 13.412 36.459 72.708
test4 2.362 3.609 5.573 12.769 40.74 81.415 159.864
test5 3.881 5.075 6.904 14.123 50.258 129.937 166.162
test9 2.237 3.493 5.422 11.977 45.98 89.336 177.39
test6 1.261 2.12 4.38 10.698 31.821 86.106 186.636
test7 1.601 2.391 3.646 8.367 38.196 110.221 211.016
test1 1.529 2.381 3.527 8.411 40.551 105.16 212.573
test3 3.035 3.934 8.606 20.858 61.571 118.744 235.428
test2 3.136 6.238 10.508 33.48 43.532 118.044 239.481
test10 1.593 4.736 7.527 20.557 59.856 162.907 323.147
test11 3.913 11.506 23.26 68.644 207.591 600.444 1211.545
-
15Когда вы пишете «краткий ответ», вы должны заметить, что некоторые решения автоматически преобразуют различные переносы строк (например,
\r\n) в\nчто может быть нежелательно в некоторых случаях. Также было бы неплохо увидеть необходимую дополнительную память или, по крайней мере, давление выделения (по крайней мере, вы можете запустить JMH с-prof gc). Для действительно классного поста было бы здорово увидеть графики (в зависимости от длины строки в пределах одного и того же размера ввода и в зависимости от размера ввода в пределах одной и той же длины строки). -
14Upvoted; Самое смешное, что результаты превзошли все ожидания: нужно использовать стандартный синтаксический сахар JDK и / или Apache Commons.
Apache Commons позволяет:
String myString = IOUtils.toString(myInputStream, "UTF-8");
Конечно, вы можете выбрать другие кодировки символов, кроме UTF-8.
Также см.: (документация)
-
1Кроме того, есть метод, который принимает аргумент inputStream только в том случае, если вы нашли кодировку по умолчанию.
-
13@Guillaume Coté Я предполагаю, что сообщение заключается в том, что вам никогда не должно быть "хорошо с кодировкой по умолчанию", так как вы не можете быть уверены в том, что это такое, в зависимости от платформы, на которой выполняется код Java.
Принимая во внимание файл, сначала нужно получить экземпляр java.io.Reader. Затем это можно прочитать и добавить в StringBuilder (нам не нужно StringBuffer, если мы не обращаемся к нему в нескольких потоках, а StringBuilder работает быстрее). Трюк здесь заключается в том, что мы работаем в блоках и, как таковые, не нуждаемся в других буферизационных потоках. Размер блока параметризуется для оптимизации производительности во время выполнения.
public static String slurp(final InputStream is, final int bufferSize) {
final char[] buffer = new char[bufferSize];
final StringBuilder out = new StringBuilder();
try (Reader in = new InputStreamReader(is, "UTF-8")) {
for (;;) {
int rsz = in.read(buffer, 0, buffer.length);
if (rsz < 0)
break;
out.append(buffer, 0, rsz);
}
}
catch (UnsupportedEncodingException ex) {
/* ... */
}
catch (IOException ex) {
/* ... */
}
return out.toString();
}
-
0есть ли шанс сломать многобайтовый символ в этом решении?
-
8Это решение использует многобайтовые символы. В этом примере используется кодировка UTF-8, которая позволяет выражать весь диапазон Unicode (включая китайский). Замена «UTF-8» другой кодировкой позволит использовать эту кодировку.
Использование:
InputStream in = /* Your InputStream */;
StringBuilder sb = new StringBuilder();
BufferedReader br = new BufferedReader(new InputStreamReader(in));
String read;
while ((read=br.readLine()) != null) {
//System.out.println(read);
sb.append(read);
}
br.close();
return sb.toString();
-
9Дело в том, что вы сначала разбиваетесь на строки, а затем удаляете это. Проще и быстрее просто читать произвольные буферы.
-
18Кроме того, readLine не различает \ n и \ r, поэтому вы не можете снова воспроизвести точный поток.
Если вы используете Google-Collections/Guava, вы можете сделать следующее:
InputStream stream = ...
String content = CharStreams.toString(new InputStreamReader(stream, Charsets.UTF_8));
Closeables.closeQuietly(stream);
Обратите внимание, что второй параметр (т.е. Charsets.UTF_8) для InputStreamReader не нужен, но, как правило, рекомендуется указывать кодировку, если вы ее знаете (что вам нужно!)
-
2@harschware: задан вопрос: «Если у вас есть объект java.io.InputStream, как вы должны обработать этот объект и создать строку?» Я предположил, что поток уже присутствует в ситуации.
-
0Вы не очень хорошо объяснили свой ответ и имели посторонние переменные; user359996 сказал то же самое, что и вы, но гораздо понятнее.
Это мое чистое решение для Java и Android, и оно работает хорошо...
public String readFullyAsString(InputStream inputStream, String encoding)
throws IOException {
return readFully(inputStream).toString(encoding);
}
public byte[] readFullyAsBytes(InputStream inputStream)
throws IOException {
return readFully(inputStream).toByteArray();
}
private ByteArrayOutputStream readFully(InputStream inputStream)
throws IOException {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int length = 0;
while ((length = inputStream.read(buffer)) != -1) {
baos.write(buffer, 0, length);
}
return baos;
}
-
4Хорошо работает на Android по сравнению с другими ответами, которые работают только в корпоративной Java.
-
0Сбой в Android с ошибкой OutOfMemory в строке «.write» каждый раз для коротких строк.
Использование:
import java.io.BufferedInputStream;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.io.IOException;
public static String readInputStreamAsString(InputStream in)
throws IOException {
BufferedInputStream bis = new BufferedInputStream(in);
ByteArrayOutputStream buf = new ByteArrayOutputStream();
int result = bis.read();
while(result != -1) {
byte b = (byte)result;
buf.write(b);
result = bis.read();
}
return buf.toString();
}
-
3Этот медленный, потому что читает побайтово.
-
0@ DanielDeLeón Нет, это не так. Это
BufferedInputStream. Базовые чтения составляют 8192 байта за раз.
Здесь самое элегантное, чисто-Java (без библиотеки) решение, которое я придумал после некоторых экспериментов:
public static String fromStream(InputStream in) throws IOException
{
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
StringBuilder out = new StringBuilder();
String newLine = System.getProperty("line.separator");
String line;
while ((line = reader.readLine()) != null) {
out.append(line);
out.append(newLine);
}
return out.toString();
}
-
4Разве не отсутствует reader.close ()? В идеале с try / finally ...
-
7@TorbenKohlmeier, читатели и буферы не нужно закрывать. Предоставленный
InputStreamдолжен быть закрыт вызывающей стороной.
Для полноты здесь решение Java 9:
public static String toString(InputStream input) throws IOException {
return new String(input.readAllBytes(), StandardCharsets.UTF_8);
}
readAllBytes в настоящее время находится в основной базе JDK 9, поэтому он может появиться в выпуске. Вы можете попробовать прямо сейчас, используя моментальные снимки JDK 9.
-
0Разве метод не выделяет много памяти для чтения?
byte[] buf = new byte[DEFAULT_BUFFER_SIZE];гдеMAX_BUFFER_SIZE = Integer.MAX_VALUE - 8;который даетMAX_BUFFER_SIZE = 2147483639. Google говорит, что его около 2,147 ГБ. -
0Извините, я допустил ошибку в расчетах. Это 2 ГБ. Я отредактировал комментарий. Итак, даже если я читаю как файл 4 КБ, я использую 2 ГБ памяти?
Я проверил здесь 14 различных ответов (извините, что не предоставил кредиты, но дубликатов слишком много).
Результат очень удивителен. Оказывается, что Apache IOUtils является самым медленным, а ByteArrayOutputStream - самым быстрым решением:
Итак, сначала вот лучший метод:
public String inputStreamToString(InputStream inputStream) throws IOException {
try(ByteArrayOutputStream result = new ByteArrayOutputStream()) {
byte[] buffer = new byte[1024];
int length;
while ((length = inputStream.read(buffer)) != -1) {
result.write(buffer, 0, length);
}
return result.toString(UTF_8);
}
}
Результаты теста 20 МБ случайных байтов за 20 циклов
Время в миллисекундах
- ByteArrayOutputStreamTest: 194
- NioStream: 198
- Java9ISTransferTo: 201
- Java9ISReadAllBytes: 205
- BufferedInputStreamVsByteArrayOutputStream: 314
- ApacheStringWriter2: 574
- GuavaCharStreams: 589
- ScannerReaderNoNextTest: 614
- ScannerReader: 633
- ApacheStringWriter: 1544
- StreamApi: ошибка
- ParallelStreamApi: ошибка
- BufferReaderTest: Ошибка
- InputStreamAndStringBuilder: ошибка
Исходный код теста
import com.google.common.io.CharStreams;
import org.apache.commons.io.IOUtils;
import java.io.*;
import java.nio.ByteBuffer;
import java.nio.channels.Channels;
import java.nio.channels.ReadableByteChannel;
import java.nio.channels.WritableByteChannel;
import java.util.Arrays;
import java.util.List;
import java.util.Random;
import java.util.stream.Collectors;
/**
* Created by Ilya Gazman on 2/13/18.
*/
public class InputStreamToString {
private static final String UTF_8 = "UTF-8";
public static void main(String... args) {
log("App started");
byte[] bytes = new byte[1024 * 1024];
new Random().nextBytes(bytes);
log("Stream is ready\n");
try {
test(bytes);
} catch (IOException e) {
e.printStackTrace();
}
}
private static void test(byte[] bytes) throws IOException {
List<Stringify> tests = Arrays.asList(
new ApacheStringWriter(),
new ApacheStringWriter2(),
new NioStream(),
new ScannerReader(),
new ScannerReaderNoNextTest(),
new GuavaCharStreams(),
new StreamApi(),
new ParallelStreamApi(),
new ByteArrayOutputStreamTest(),
new BufferReaderTest(),
new BufferedInputStreamVsByteArrayOutputStream(),
new InputStreamAndStringBuilder(),
new Java9ISTransferTo(),
new Java9ISReadAllBytes()
);
String solution = new String(bytes, "UTF-8");
for (Stringify test : tests) {
try (ByteArrayInputStream inputStream = new ByteArrayInputStream(bytes)) {
String s = test.inputStreamToString(inputStream);
if (!s.equals(solution)) {
log(test.name() + ": Error");
continue;
}
}
long startTime = System.currentTimeMillis();
for (int i = 0; i < 20; i++) {
try (ByteArrayInputStream inputStream = new ByteArrayInputStream(bytes)) {
test.inputStreamToString(inputStream);
}
}
log(test.name() + ": " + (System.currentTimeMillis() - startTime));
}
}
private static void log(String message) {
System.out.println(message);
}
interface Stringify {
String inputStreamToString(InputStream inputStream) throws IOException;
default String name() {
return this.getClass().getSimpleName();
}
}
static class ApacheStringWriter implements Stringify {
@Override
public String inputStreamToString(InputStream inputStream) throws IOException {
StringWriter writer = new StringWriter();
IOUtils.copy(inputStream, writer, UTF_8);
return writer.toString();
}
}
static class ApacheStringWriter2 implements Stringify {
@Override
public String inputStreamToString(InputStream inputStream) throws IOException {
return IOUtils.toString(inputStream, UTF_8);
}
}
static class NioStream implements Stringify {
@Override
public String inputStreamToString(InputStream in) throws IOException {
ReadableByteChannel channel = Channels.newChannel(in);
ByteBuffer byteBuffer = ByteBuffer.allocate(1024 * 16);
ByteArrayOutputStream bout = new ByteArrayOutputStream();
WritableByteChannel outChannel = Channels.newChannel(bout);
while (channel.read(byteBuffer) > 0 || byteBuffer.position() > 0) {
byteBuffer.flip(); //make buffer ready for write
outChannel.write(byteBuffer);
byteBuffer.compact(); //make buffer ready for reading
}
channel.close();
outChannel.close();
return bout.toString(UTF_8);
}
}
static class ScannerReader implements Stringify {
@Override
public String inputStreamToString(InputStream is) throws IOException {
java.util.Scanner s = new java.util.Scanner(is).useDelimiter("\\A");
return s.hasNext() ? s.next() : "";
}
}
static class ScannerReaderNoNextTest implements Stringify {
@Override
public String inputStreamToString(InputStream is) throws IOException {
java.util.Scanner s = new java.util.Scanner(is).useDelimiter("\\A");
return s.next();
}
}
static class GuavaCharStreams implements Stringify {
@Override
public String inputStreamToString(InputStream is) throws IOException {
return CharStreams.toString(new InputStreamReader(
is, UTF_8));
}
}
static class StreamApi implements Stringify {
@Override
public String inputStreamToString(InputStream inputStream) throws IOException {
return new BufferedReader(new InputStreamReader(inputStream))
.lines().collect(Collectors.joining("\n"));
}
}
static class ParallelStreamApi implements Stringify {
@Override
public String inputStreamToString(InputStream inputStream) throws IOException {
return new BufferedReader(new InputStreamReader(inputStream)).lines()
.parallel().collect(Collectors.joining("\n"));
}
}
static class ByteArrayOutputStreamTest implements Stringify {
@Override
public String inputStreamToString(InputStream inputStream) throws IOException {
try(ByteArrayOutputStream result = new ByteArrayOutputStream()) {
byte[] buffer = new byte[1024];
int length;
while ((length = inputStream.read(buffer)) != -1) {
result.write(buffer, 0, length);
}
return result.toString(UTF_8);
}
}
}
static class BufferReaderTest implements Stringify {
@Override
public String inputStreamToString(InputStream inputStream) throws IOException {
String newLine = System.getProperty("line.separator");
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
StringBuilder result = new StringBuilder(UTF_8);
String line;
boolean flag = false;
while ((line = reader.readLine()) != null) {
result.append(flag ? newLine : "").append(line);
flag = true;
}
return result.toString();
}
}
static class BufferedInputStreamVsByteArrayOutputStream implements Stringify {
@Override
public String inputStreamToString(InputStream inputStream) throws IOException {
BufferedInputStream bis = new BufferedInputStream(inputStream);
ByteArrayOutputStream buf = new ByteArrayOutputStream();
int result = bis.read();
while (result != -1) {
buf.write((byte) result);
result = bis.read();
}
return buf.toString(UTF_8);
}
}
static class InputStreamAndStringBuilder implements Stringify {
@Override
public String inputStreamToString(InputStream inputStream) throws IOException {
int ch;
StringBuilder sb = new StringBuilder(UTF_8);
while ((ch = inputStream.read()) != -1)
sb.append((char) ch);
return sb.toString();
}
}
static class Java9ISTransferTo implements Stringify {
@Override
public String inputStreamToString(InputStream inputStream) throws IOException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
inputStream.transferTo(bos);
return bos.toString(UTF_8);
}
}
static class Java9ISReadAllBytes implements Stringify {
@Override
public String inputStreamToString(InputStream inputStream) throws IOException {
return new String(inputStream.readAllBytes(), UTF_8);
}
}
}
Я бы использовал некоторые трюки Java 8.
public static String streamToString(final InputStream inputStream) throws Exception {
// buffering optional
try
(
final BufferedReader br
= new BufferedReader(new InputStreamReader(inputStream))
) {
// parallel optional
return br.lines().parallel().collect(Collectors.joining("\n"));
} catch (final IOException e) {
throw new RuntimeException(e);
// whatever.
}
}
По существу то же самое, что и некоторые другие ответы, кроме более сжатых.
-
5Будет ли это
return nullкогда-либо вызываться? Либоbr.lines...возвращается, либоbr.lines...исключение.
Я провел несколько тестов времени, потому что время имеет значение, всегда.
Я попытался получить ответ в String 3 разными способами. (показано ниже)
Я оставил блоки try/catch для удобства чтения.
Чтобы дать контекст, это предыдущий код для всех трех подходов:
String response;
String url = "www.blah.com/path?key=value";
GetMethod method = new GetMethod(url);
int status = client.executeMethod(method);
1)
response = method.getResponseBodyAsString();
2)
InputStream resp = method.getResponseBodyAsStream();
InputStreamReader is=new InputStreamReader(resp);
BufferedReader br=new BufferedReader(is);
String read = null;
StringBuffer sb = new StringBuffer();
while((read = br.readLine()) != null) {
sb.append(read);
}
response = sb.toString();
3)
InputStream iStream = method.getResponseBodyAsStream();
StringWriter writer = new StringWriter();
IOUtils.copy(iStream, writer, "UTF-8");
response = writer.toString();
Итак, после выполнения 500 тестов для каждого подхода с одинаковыми данными запроса/ответа, вот цифры. Еще раз, это мои выводы, и ваши результаты могут быть не совсем одинаковыми, но я написал это, чтобы дать некоторые указания другим относительно различий в эффективности этих подходов.
Звания:
Подход №1
Подход №3 - на 2.6% медленнее, чем # 1
Подход №2 - на 4,3% медленнее, чем # 1
Любой из этих подходов является подходящим решением для захвата ответа и создания из него строки.
-
22) содержит ошибку, она всегда добавляет «ноль» в конец строки, поскольку вы всегда делаете еще один шаг, чем необходимо. В любом случае, производительность будет такой же. Это должно работать: String read = null; StringBuffer sb = new StringBuffer (); while ((read = br.readLine ())! = null) {sb.append (read); }
-
0Следует отметить, что GetMethod является частью org.apache.commons.httpclient, а не стандартной Java
Чистое решение Java с использованием Stream s, работает с Java 8.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.stream.Collectors;
// ...
public static String inputStreamToString(InputStream is) throws IOException {
try (BufferedReader br = new BufferedReader(new InputStreamReader(is))) {
return br.lines().collect(Collectors.joining(System.lineSeparator()));
}
}
Как упомянуто Кристоффером Хаммарстромом ниже в другом ответе, безопаснее явно указать кодировку. Т.е. конструктор InputStreamReader может быть изменен следующим образом:
new InputStreamReader(is, Charset.forName("UTF-8"))
-
11Вместо использования
Charset.forName("UTF-8")используйтеStandardCharsets.UTF_8(изjava.nio.charset).
Здесь более или менее ответ sampath, очищенный бит и представленный как функция:
String streamToString(InputStream in) throws IOException {
StringBuilder out = new StringBuilder();
BufferedReader br = new BufferedReader(new InputStreamReader(in));
for(String line = br.readLine(); line != null; line = br.readLine())
out.append(line);
br.close();
return out.toString();
}
Если вы чувствовали себя авантюрно, вы могли бы смешать Scala и Java и в итоге:
scala.io.Source.fromInputStream(is).mkString("")
Смешивание Java и Scala кода и библиотек имеет преимущества.
Смотрите полное описание здесь: Идиоматический способ преобразования InputStream в строку в Scala
-
2В настоящее время просто это работает отлично:
Source.fromInputStream(...).mkString
Если вы не можете использовать Commons IO (FileUtils/IOUtils/CopyUtils), вот пример использования BufferedReader для чтения файла построчно:
public class StringFromFile {
public static void main(String[] args) /*throws UnsupportedEncodingException*/ {
InputStream is = StringFromFile.class.getResourceAsStream("file.txt");
BufferedReader br = new BufferedReader(new InputStreamReader(is/*, "UTF-8"*/));
final int CHARS_PER_PAGE = 5000; //counting spaces
StringBuilder builder = new StringBuilder(CHARS_PER_PAGE);
try {
for(String line=br.readLine(); line!=null; line=br.readLine()) {
builder.append(line);
builder.append('\n');
}
}
catch (IOException ignore) { }
String text = builder.toString();
System.out.println(text);
}
}
Или, если вам нужна грубая скорость, я бы предложил вариант того, что предложил Пол де Вриз (в котором избегается использование StringWriter (который использует StringBuffer внутри):
public class StringFromFileFast {
public static void main(String[] args) /*throws UnsupportedEncodingException*/ {
InputStream is = StringFromFileFast.class.getResourceAsStream("file.txt");
InputStreamReader input = new InputStreamReader(is/*, "UTF-8"*/);
final int CHARS_PER_PAGE = 5000; //counting spaces
final char[] buffer = new char[CHARS_PER_PAGE];
StringBuilder output = new StringBuilder(CHARS_PER_PAGE);
try {
for(int read = input.read(buffer, 0, buffer.length);
read != -1;
read = input.read(buffer, 0, buffer.length)) {
output.append(buffer, 0, read);
}
} catch (IOException ignore) { }
String text = output.toString();
System.out.println(text);
}
}
-
0Чтобы заставить ваш код работать, я должен был использовать this.getClass (). GetClassLoader (). GetResourceAsStream () (используя Eclipse с проектом maven).
Это ответ, адаптированный из org.apache.commons.io.IOUtils исходного кода, для тех, кто хочет иметь реализацию apache, но не хочет, чтобы вся библиотека.
private static final int BUFFER_SIZE = 4 * 1024;
public static String inputStreamToString(InputStream inputStream, String charsetName)
throws IOException {
StringBuilder builder = new StringBuilder();
InputStreamReader reader = new InputStreamReader(inputStream, charsetName);
char[] buffer = new char[BUFFER_SIZE];
int length;
while ((length = reader.read(buffer)) != -1) {
builder.append(buffer, 0, length);
}
return builder.toString();
}
Обязательно закройте потоки в конце, если вы используете Stream Readers
private String readStream(InputStream iStream) throws IOException {
//build a Stream Reader, it can read char by char
InputStreamReader iStreamReader = new InputStreamReader(iStream);
//build a buffered Reader, so that i can read whole line at once
BufferedReader bReader = new BufferedReader(iStreamReader);
String line = null;
StringBuilder builder = new StringBuilder();
while((line = bReader.readLine()) != null) { //Read till end
builder.append(line);
builder.append("\n"); // append new line to preserve lines
}
bReader.close(); //close all opened stuff
iStreamReader.close();
//iStream.close(); //EDIT: Let the creator of the stream close it!
// some readers may auto close the inner stream
return builder.toString();
}
EDIT: в JDK 7+ вы можете использовать конструкцию try-with-resources.
/**
* Reads the stream into a string
* @param iStream the input stream
* @return the string read from the stream
* @throws IOException when an IO error occurs
*/
private String readStream(InputStream iStream) throws IOException {
//Buffered reader allows us to read line by line
try (BufferedReader bReader =
new BufferedReader(new InputStreamReader(iStream))){
StringBuilder builder = new StringBuilder();
String line;
while((line = bReader.readLine()) != null) { //Read till end
builder.append(line);
builder.append("\n"); // append new line to preserve lines
}
return builder.toString();
}
}
-
1Вы правы в отношении закрытия потоков, однако ответственность за закрытие потоков обычно лежит на конструкторе потоков (завершите то, что вы начали). Таким образом,
iStreamдействительно должен быть закрыт вызывающим, потому что вызывающий создалiStream. Кроме того, закрытие потоков должно выполняться в блокеfinallyили, что еще лучше, в инструкции Java 7 try-with-resources. В вашем коде, когдаreadLine()builder.append()IOExceptionилиbuilder.append()OutOfMemoryError, потоки остаются открытыми.
Вот полный метод преобразования InputStream в String без использования сторонней библиотеки. Используйте StringBuilder для однопоточной среды, иначе используйте StringBuffer.
public static String getString( InputStream is) throws IOException {
int ch;
StringBuilder sb = new StringBuilder();
while((ch = is.read()) != -1)
sb.append((char)ch);
return sb.toString();
}
-
2В этом методе кодировка не применяется. Итак, скажем, данные, полученные из InputStream, кодируются с использованием UTF-8, вывод будет неправильным. Чтобы это исправить, вы можете использовать
in = new InputStreamReader(inputStream)и(char)in.read(). -
0Разве чтение за символом не слишком медленное?
Здесь, как это сделать, используя только JDK с использованием буферов массива байтов. На самом деле все методы commons-io IOUtils.copy() работают. Вы можете заменить byte[] на char[], если вы копируете из Reader вместо InputStream.
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
...
InputStream is = ....
ByteArrayOutputStream baos = new ByteArrayOutputStream(8192);
byte[] buffer = new byte[8192];
int count = 0;
try {
while ((count = is.read(buffer)) != -1) {
baos.write(buffer, 0, count);
}
}
finally {
try {
is.close();
}
catch (Exception ignore) {
}
}
String charset = "UTF-8";
String inputStreamAsString = baos.toString(charset);
-
1Пожалуйста, дайте описание того, что вы пытаетесь достичь.
Другой, для всех пользователей Spring:
import java.nio.charset.StandardCharsets;
import org.springframework.util.FileCopyUtils;
public String convertStreamToString(InputStream is) throws IOException {
return new String(FileCopyUtils.copyToByteArray(is), StandardCharsets.UTF_8);
}
Методы утилиты в org.springframework.util.StreamUtils аналогичны методам в FileCopyUtils, но они оставляют поток открытым, когда это делается.
Используйте java.io.InputStream.transferTo(OutputStream), поддерживаемый в Java 9 и ByteArrayOutputStream.toString(String), который берет имя кодировки:
public static String gobble(InputStream in, String charsetName) throws IOException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
in.transferTo(bos);
return bos.toString(charsetName);
}
-
0Что вы дали за имя кодировки в вашем случае?
-
1@virsha Вы должны определить это по источнику, предоставившему InputStream. Помните, что не имеет смысла иметь строку, не зная, какую кодировку она использует.
Пользователи Kotlin просто делают:
println(InputStreamReader(is).readText())
тогда как
readText()
- встроенный метод расширения стандартной библиотеки Kotlin.
Это хорошо, потому что:
- Безопасность рук в кодировке.
- Вы управляете размером буфера чтения.
- Вы можете указать длину построителя и не точно.
- Свободен от зависимостей библиотек.
- Является ли для Java 7 или выше.
Что для?
public static String convertStreamToString(InputStream is) {
if (is == null) return null;
StringBuilder sb = new StringBuilder(2048); // Define a size if you have an idea of it.
char[] read = new char[128]; // Your buffer size.
try (InputStreamReader ir = new InputStreamReader(is, StandardCharsets.UTF_8)) {
for (int i; -1 != (i = ir.read(read)); sb.append(read, 0, i));
} catch (Throwable t) {}
return sb.toString();
}
-
0
catch (Throwable)не должен быть пустым, если этоcatch (Throwable)код.
Самый простой способ в JDK состоит в следующем: snipplets кода.
String convertToString(InputStream in){
String resource = new Scanner(in).useDelimiter("\\Z").next();
return resource;
}
Здесь мое решение Java 8, которое использует новый Stream API для сбора всех строк из InputStream:
public static String toString(InputStream inputStream) {
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream));
return reader.lines().collect(Collectors.joining(
System.getProperty("line.separator")));
}
-
1Кажется, что вы на самом деле не прочитали все ответы, опубликованные ранее. Версия Stream API уже была здесь как минимум два раза .
-
0Я посмотрел на все решения, но не нашел подходящих. Я считаю, что две строки с кратким описанием точно представлены. Например, блок try-catch из другого решения никогда не используется. Но ты прав. С таким количеством ответов я переключился в режим fast-skipping-read-mode ... :-)
inputStream.getText()
-
3это желаемый результат, не в состоянии понять, почему Java сделан таким хитрым ...
С точки зрения reduce и concat это может быть выражено в Java 8 как:
String fromFile = new BufferedReader(new
InputStreamReader(inputStream)).lines().reduce(String::concat).get();
-
0Это будет безумно медленно.
-
0Интересно, а почему? Не могли бы вы уточнить?
Raghu K Nair Был единственным, кто использовал сканер. Код, который я использую, немного отличается:
String convertToString(InputStream in){
Scanner scanner = new Scanner(in)
scanner.useDelimiter("\\A");
boolean hasInput = scanner.hasNext();
if (hasInput) {
return scanner.next();
} else {
return null;
}
}
О разделителях: Как использовать разделитель в сканере Java?
Основываясь на второй части принятого ответа Apache Commons, но с небольшим зазором, заполненным для всегда закрытия потока:
String theString;
try {
theString = IOUtils.toString(inputStream, encoding);
} finally {
IOUtils.closeQuietly(inputStream);
}
-
0Обратите внимание, что это решение является наиболее неэффективным на основе моих результатов теста
Guava предоставляет гораздо более короткое эффективное решение для автоматического закрытия в случае, если поток ввода поступает из ресурса classpath (который, кажется, является популярной задачей):
byte[] bytes = Resources.toByteArray(classLoader.getResource(path));
или
String text = Resources.toString(classLoader.getResource(path), StandardCharsets.UTF_8);
Существует также общая концепция ByteSource и CharSource, которые нежно заботятся об открытии и закрытии потока.
Так, например, вместо явного открытия небольшого файла для чтения его содержимого:
String content = Files.asCharSource(new File("robots.txt"), StandardCharsets.UTF_8).read();
byte[] data = Files.asByteSource(new File("favicon.ico")).read();
или просто
String content = Files.toString(new File("robots.txt"), StandardCharsets.UTF_8);
byte[] data = Files.toByteArray(new File("favicon.ico"));
-
0Отличный совет о ресурсах гуавы.
InputStream is = Context.openFileInput(someFileName); // whatever format you have
ByteArrayOutputStream bos = new ByteArrayOutputStream();
byte[] b = new byte[8192];
for (int bytesRead; (bytesRead = is.read(b)) != -1;) {
bos.write(b, 0, bytesRead);
}
String output = bos.toString(someEncoding);
Я написал класс, который делает именно это, поэтому я решил, что поделюсь им со всеми. Иногда вы не хотите добавлять Apache Commons только для одной вещи и хотите, чтобы что-то нелепо, чем сканер, который не проверяет содержимое.
Использование выглядит следующим образом
// Read from InputStream
String data = new ReaderSink(inputStream, Charset.forName("UTF-8")).drain();
// Read from File
data = new ReaderSink(file, Charset.forName("UTF-8")).drain();
// Drain input stream to console
new ReaderSink(inputStream, Charset.forName("UTF-8")).drainTo(System.out);
Вот код для ReaderSink:
import java.io.*;
import java.nio.charset.Charset;
/**
* A simple sink class that drains a {@link Reader} to a {@link String} or
* to a {@link Writer}.
*
* @author Ben Barkay
* @version 2/20/2014
*/
public class ReaderSink {
/**
* The default buffer size to use if no buffer size was specified.
*/
public static final int DEFAULT_BUFFER_SIZE = 1024;
/**
* The {@link Reader} that will be drained.
*/
private final Reader in;
/**
* Constructs a new {@code ReaderSink} for the specified file and charset.
* @param file The file to read from.
* @param charset The charset to use.
* @throws FileNotFoundException If the file was not found on the filesystem.
*/
public ReaderSink(File file, Charset charset) throws FileNotFoundException {
this(new FileInputStream(file), charset);
}
/**
* Constructs a new {@code ReaderSink} for the specified {@link InputStream}.
* @param in The {@link InputStream} to drain.
* @param charset The charset to use.
*/
public ReaderSink(InputStream in, Charset charset) {
this(new InputStreamReader(in, charset));
}
/**
* Constructs a new {@code ReaderSink} for the specified {@link Reader}.
* @param in The reader to drain.
*/
public ReaderSink(Reader in) {
this.in = in;
}
/**
* Drains the data from the underlying {@link Reader}, returning a {@link String} containing
* all of the read information. This method will use {@link #DEFAULT_BUFFER_SIZE} for
* its buffer size.
* @return A {@link String} containing all of the information that was read.
*/
public String drain() throws IOException {
return drain(DEFAULT_BUFFER_SIZE);
}
/**
* Drains the data from the underlying {@link Reader}, returning a {@link String} containing
* all of the read information.
* @param bufferSize The size of the buffer to use when reading.
* @return A {@link String} containing all of the information that was read.
*/
public String drain(int bufferSize) throws IOException {
StringWriter stringWriter = new StringWriter();
drainTo(stringWriter, bufferSize);
return stringWriter.toString();
}
/**
* Drains the data from the underlying {@link Reader}, writing it to the
* specified {@link Writer}. This method will use {@link #DEFAULT_BUFFER_SIZE} for
* its buffer size.
* @param out The {@link Writer} to write to.
*/
public void drainTo(Writer out) throws IOException {
drainTo(out, DEFAULT_BUFFER_SIZE);
}
/**
* Drains the data from the underlying {@link Reader}, writing it to the
* specified {@link Writer}.
* @param out The {@link Writer} to write to.
* @param bufferSize The size of the buffer to use when reader.
*/
public void drainTo(Writer out, int bufferSize) throws IOException {
char[] buffer = new char[bufferSize];
int read;
while ((read = in.read(buffer)) > -1) {
out.write(buffer, 0, read);
}
}
}
Следующий код работал у меня.
URL url = MyClass.class.getResource("/" + configFileName);
BufferedInputStream bi = (BufferedInputStream) url.getContent();
byte[] buffer = new byte[bi.available() ];
int bytesRead = bi.read(buffer);
String out = new String(buffer);
Обратите внимание, что в соответствии с документами Java метод available() может работать не с InputStream, но всегда работает с BufferedInputStream.
Если вы не хотите использовать метод available(), мы всегда можем использовать приведенный ниже код
URL url = MyClass.class.getResource("/" + configFileName);
BufferedInputStream bi = (BufferedInputStream) url.getContent();
File f = new File(url.getPath());
byte[] buffer = new byte[ (int) f.length()];
int bytesRead = bi.read(buffer);
String out = new String(buffer);
Я не уверен, будут ли какие-либо проблемы с кодировкой. Прокомментируйте, если будут какие-либо проблемы с кодом.
-
4Весь смысл использования
InputStreamв том, что а) вы не знаете длину полного потока (который вываливается что - нибудь в зависимости отavailable) и б) поток может быть любым - файл, сокет - то внутреннее (который выручает что-нибудь на основеFile.size()). Относительноavailable: Это обрезает данные, если поток длиннее, чем размер буфера. -
0Существует предупреждение в Javadoc specificaly против того , как вы используете
available(), и нет ничего в спецификацииread(), который гарантирует , что заполняет буфер: поэтому он возвращает число чтения.
С Окио:
String result = Okio.buffer(Okio.source(inputStream)).readUtf8();
public String read(InputStream in) throws IOException {
try (BufferedReader buffer = new BufferedReader(new InputStreamReader(in))) {
return buffer.lines().collect(Collectors.joining("\n"));
}
}
Попробуйте эти 4 утверждения..
В соответствии с точкой, на которую ссылается Fred, не рекомендуется добавлять оператор String с +=, поскольку каждый раз, когда новый char добавляется к существующему String, создавая новый объект String снова и присваивая свой адрес st, в то время как старый объект st становится мусором.
public String convertStreamToString(InputStream is)
{
int k;
StringBuffer sb=new StringBuffer();
while((k=fin.read()) != -1)
{
sb.append((char)k);
}
return sb.toString();
}
Не рекомендуется, но это также способ
public String convertStreamToString(InputStream is) {
int k;
String st="";
while((k=is.read()) != -1)
{
st+=(char)k;
}
return st;
}
-
2Конкатенация строк в цикле с оператором
+=не очень хорошая идея. Лучше использоватьStringBuilderилиStringBuffer.
Вы можете использовать Apache Commons.
В IOUtils вы можете найти метод toString с тремя полезными реализациями.
public static String toString(InputStream input) throws IOException {
return toString(input, Charset.defaultCharset());
}
public static String toString(InputStream input) throws IOException {
return toString(input, Charset.defaultCharset());
}
public static String toString(InputStream input, String encoding)
throws IOException {
return toString(input, Charsets.toCharset(encoding));
}
-
0В чем разница между первыми 2 методами?
Ответ JDK 7/8, который закрывает поток и все еще вызывает исключение IOException:
StringBuilder build = new StringBuilder();
byte[] buf = new byte[1024];
int length;
try (InputStream is = getInputStream()) {
while ((length = is.read(buf)) != -1) {
build.append(new String(buf, 0, length));
}
}
Ну, вы можете запрограммировать это для себя... Это не сложно...
String Inputstream2String (InputStream is) throws IOException
{
final int PKG_SIZE = 1024;
byte[] data = new byte [PKG_SIZE];
StringBuilder buffer = new StringBuilder(PKG_SIZE * 10);
int size;
size = is.read(data, 0, data.length);
while (size > 0)
{
String str = new String(data, 0, size);
buffer.append(str);
size = is.read(data, 0, data.length);
}
return buffer.toString();
}
-
1Поскольку вы используете локальную переменную
bufferбез возможности совместного использования в нескольких потоках, вам следует рассмотреть возможность изменения ее типа наStringBuilder, чтобы избежать издержек (бесполезной) синхронизации. -
0Это хороший момент, Алекс! Я считаю, что мы оба согласны, что этот метод не является многопоточным. Даже операции ввода потока не являются потокобезопасными.
ISO-8859-1
Вот очень эффективный способ сделать это, если вы знаете, что кодировка входного потока - ISO-8859-1 или ASCII. Это (1) позволяет избежать ненужной синхронизации, присутствующий в StringWriter внутренней StringBuffer, (2), позволяет избежать накладных расходов InputStreamReader, и (3) минимизирует число раз StringBuilder внутренний char массив должен быть скопирован.
public static String iso_8859_1(InputStream is) throws IOException {
StringBuilder chars = new StringBuilder(Math.max(is.available(), 4096));
byte[] buffer = new byte[4096];
int n;
while ((n = is.read(buffer)) != -1) {
for (int i = 0; i < n; i++) {
chars.append((char)(buffer[i] & 0xFF));
}
}
return chars.toString();
}
UTF-8,
Та же общая стратегия может использоваться для потока, закодированного с помощью UTF-8:
public static String utf8(InputStream is) throws IOException {
StringBuilder chars = new StringBuilder(Math.max(is.available(), 4096));
byte[] buffer = new byte[4096];
int n;
int state = 0;
while ((n = is.read(buffer)) != -1) {
for (int i = 0; i < n; i++) {
if ((state = nextStateUtf8(state, buffer[i])) >= 0) {
chars.appendCodePoint(state);
} else if (state == -1) { //error
state = 0;
chars.append('\uFFFD'); //replacement char
}
}
}
return chars.toString();
}
где nextStateUtf8() определяется следующим образом:
/**
* Returns the next UTF-8 state given the next byte of input and the current state.
* If the input byte is the last byte in a valid UTF-8 byte sequence,
* the returned state will be the corresponding unicode character (in the range of 0 through 0x10FFFF).
* Otherwise, a negative integer is returned. A state of -1 is returned whenever an
* invalid UTF-8 byte sequence is detected.
*/
static int nextStateUtf8(int currentState, byte nextByte) {
switch (currentState & 0xF0000000) {
case 0:
if ((nextByte & 0x80) == 0) { //0 trailing bytes (ASCII)
return nextByte;
} else if ((nextByte & 0xE0) == 0xC0) { //1 trailing byte
if (nextByte == (byte) 0xC0 || nextByte == (byte) 0xC1) { //0xCO & 0xC1 are overlong
return -1;
} else {
return nextByte & 0xC000001F;
}
} else if ((nextByte & 0xF0) == 0xE0) { //2 trailing bytes
if (nextByte == (byte) 0xE0) { //possibly overlong
return nextByte & 0xA000000F;
} else if (nextByte == (byte) 0xED) { //possibly surrogate
return nextByte & 0xB000000F;
} else {
return nextByte & 0x9000000F;
}
} else if ((nextByte & 0xFC) == 0xF0) { //3 trailing bytes
if (nextByte == (byte) 0xF0) { //possibly overlong
return nextByte & 0x80000007;
} else {
return nextByte & 0xE0000007;
}
} else if (nextByte == (byte) 0xF4) { //3 trailing bytes, possibly undefined
return nextByte & 0xD0000007;
} else {
return -1;
}
case 0xE0000000: //3rd-to-last continuation byte
return (nextByte & 0xC0) == 0x80 ? currentState << 6 | nextByte & 0x9000003F : -1;
case 0x80000000: //3rd-to-last continuation byte, check overlong
return (nextByte & 0xE0) == 0xA0 || (nextByte & 0xF0) == 0x90 ? currentState << 6 | nextByte & 0x9000003F : -1;
case 0xD0000000: //3rd-to-last continuation byte, check undefined
return (nextByte & 0xF0) == 0x80 ? currentState << 6 | nextByte & 0x9000003F : -1;
case 0x90000000: //2nd-to-last continuation byte
return (nextByte & 0xC0) == 0x80 ? currentState << 6 | nextByte & 0xC000003F : -1;
case 0xA0000000: //2nd-to-last continuation byte, check overlong
return (nextByte & 0xE0) == 0xA0 ? currentState << 6 | nextByte & 0xC000003F : -1;
case 0xB0000000: //2nd-to-last continuation byte, check surrogate
return (nextByte & 0xE0) == 0x80 ? currentState << 6 | nextByte & 0xC000003F : -1;
case 0xC0000000: //last continuation byte
return (nextByte & 0xC0) == 0x80 ? currentState << 6 | nextByte & 0x3F : -1;
default:
return -1;
}
}
Автоопределение кодирования
Если ваш входной поток был закодирован с использованием ASCII или ISO-8859-1 или UTF-8, но вы не уверены, какой, мы можем использовать метод, аналогичный последнему, но с дополнительным компонентом обнаружения кодирования для автоматического обнаружения кодировка перед возвратом строки.
public static String autoDetect(InputStream is) throws IOException {
StringBuilder chars = new StringBuilder(Math.max(is.available(), 4096));
byte[] buffer = new byte[4096];
int n;
int state = 0;
boolean ascii = true;
while ((n = is.read(buffer)) != -1) {
for (int i = 0; i < n; i++) {
if ((state = nextStateUtf8(state, buffer[i])) > 0x7F)
ascii = false;
chars.append((char)(buffer[i] & 0xFF));
}
}
if (ascii || state < 0) { //probably not UTF-8
return chars.toString();
}
//probably UTF-8
int pos = 0;
char[] charBuf = new char[2];
for (int i = 0, len = chars.length(); i < len; i++) {
if ((state = nextStateUtf8(state, (byte)chars.charAt(i))) >= 0) {
boolean hi = Character.toChars(state, charBuf, 0) == 2;
chars.setCharAt(pos++, charBuf[0]);
if (hi) {
chars.setCharAt(pos++, charBuf[1]);
}
}
}
return chars.substring(0, pos);
}
Если ваш входной поток имеет кодировку, которая не соответствует ни ISO-8859-1, ни ASCII, ни UTF-8, то я перехожу к другим уже присутствующим ответам.
Вы можете использовать Cactoos:
String text = new TextOf(inputStream).asString();
Кодировка UTF-8 по умолчанию. Если вам нужен еще один:
String text = new TextOf(inputStream, "UTF-16").asString();
Ниже не рассматривается исходный вопрос, а скорее некоторые из ответов.
Несколько ответов показывают петли формы
String line = null;
while((line = reader.readLine()) != null) {
// ...
}
или
for(String line = reader.readLine(); line != null; line = reader.readLine()) {
// ...
}
Первая форма загрязняет пространство имен охватывающей области, объявляя переменную "read" в охватывающей области, которая не будет использоваться ни для чего вне цикла for. Вторая форма дублирует вызов readline().
Вот гораздо более чистый способ написания такого цикла в Java. Оказывается, первое предложение в цикле for не требует действительного значения инициализатора. Это удерживает область действия переменной "строка" внутри тела цикла for. Гораздо более элегантно! Я не видел никого, кто использовал эту форму где-нибудь (я случайно обнаружил ее один день назад), но я использую ее все время.
for (String line; (line = reader.readLine()) != null; ) {
//...
}
InputStreamReader i = new InputStreamReader(s);
BufferedReader str = new BufferedReader(i);
String msg = str.readLine();
System.out.println(msg);
Здесь s - ваш объект InputStream, который преобразуется в String
-
0это будет работать, если последние 2 строки будут вставлены в цикл
do-whilewhile? -
5будет работать только если InputStream однострочный
Использование:
String theString = IOUtils.toString(inputStream, encoding);
-
1Оказывается, этот метод самый медленный
-
1Это просто повторяет одно из решений в ответе с наибольшим количеством голосов. Без объяснения
Это решение этого вопроса не является самым простым, но поскольку потоки и каналы NIO не упоминались, здесь идет версия, которая использует каналы NIO и ByteBuffer для преобразования потока в строку.
public static String streamToStringChannel(InputStream in, String encoding, int bufSize) throws IOException {
ReadableByteChannel channel = Channels.newChannel(in);
ByteBuffer byteBuffer = ByteBuffer.allocate(bufSize);
ByteArrayOutputStream bout = new ByteArrayOutputStream();
WritableByteChannel outChannel = Channels.newChannel(bout);
while (channel.read(byteBuffer) > 0 || byteBuffer.position() > 0) {
byteBuffer.flip(); //make buffer ready for write
outChannel.write(byteBuffer);
byteBuffer.compact(); //make buffer ready for reading
}
channel.close();
outChannel.close();
return bout.toString(encoding);
}
Вот пример того, как его использовать:
try (InputStream in = new FileInputStream("/tmp/large_file.xml")) {
String x = streamToStringChannel(in, "UTF-8", 1);
System.out.println(x);
}
Производительность этого метода должна быть хорошей для больших файлов.
InputStream inputStream = null;
BufferedReader bufferedReader = null;
try {
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
String stringBuilder = new StringBuilder();
String content;
while((content = bufferedReader.readLine()) != null){
stringBuilder.append(content);
}
System.out.println("content of file::" + stringBuilder.toString());
}
catch (IOException e) {
e.printStackTrace();
}finally{
if(bufferedReader != null){
try{
bufferedReader.close();
}catch(IoException ex){
ex.printStackTrace();
}
Способ преобразования inputStream в String
public static String getStringFromInputStream(InputStream inputStream) {
BufferedReader bufferedReader = null;
StringBuilder stringBuilder = new StringBuilder();
String line;
try {
bufferedReader = new BufferedReader(new InputStreamReader(
inputStream));
while ((line = bufferedReader.readLine()) != null) {
stringBuilder.append(line);
}
} catch (IOException e) {
logger.error(e.getMessage());
} finally {
if (bufferedReader != null) {
try {
bufferedReader.close();
} catch (IOException e) {
logger.error(e.getMessage());
}
}
}
return stringBuilder.toString();
}
Этот фрагмент был найден в \sdk\samples\android-19\connectivity\NetworkConnect\NetworkConnectSample\src\main\java\com\example\android\networkconnect\MainActivity.java, который лицензирован в соответствии с Apache License, Version 2.0 и написанный Google.
/** Reads an InputStream and converts it to a String.
* @param stream InputStream containing HTML from targeted site.
* @param len Length of string that this method returns.
* @return String concatenated according to len parameter.
* @throws java.io.IOException
* @throws java.io.UnsupportedEncodingException
*/
private String readIt(InputStream stream, int len) throws IOException, UnsupportedEncodingException {
Reader reader = null;
reader = new InputStreamReader(stream, "UTF-8");
char[] buffer = new char[len];
reader.read(buffer);
return new String(buffer);
}
Я предлагаю класс StringWriter для этой проблемы.
StringWriter wt= new StringWriter();
IOUtils.copy(inputStream, wt, encoding);
String st= wt.toString();
String resultString = IOUtils.toString(userInputStream, "UTF-8");
Я создал этот код, и он работает. Там нет обязательных внешних плагинов.
Есть конвертировать строку в поток и поток в строку...
import java.io.ByteArrayInputStream;
import java.io.InputStream;
public class STRINGTOSTREAM {
public static void main(String[] args)
{
String text = "Hello Bhola..!\nMy Name Is Kishan ";
InputStream strm = new ByteArrayInputStream(text.getBytes()); // Convert String to Stream
String data = streamTostring(strm);
System.out.println(data);
}
static String streamTostring(InputStream stream)
{
String data = "";
try
{
StringBuilder stringbuld = new StringBuilder();
int i;
while ((i=stream.read())!=-1)
{
stringbuld.append((char)i);
}
data = stringbuld.toString();
}
catch(Exception e)
{
data = "No data Streamed.";
}
return data;
}
Также вы можете получить InputStream из указанного пути ресурса:
public static InputStream getResourceAsStream(String path)
{
InputStream myiInputStream = ClassName.class.getResourceAsStream(path);
if (null == myiInputStream)
{
mylogger.info("Can't find path = ", path);
}
return myiInputStream;
}
Чтобы получить InputStream по определенному пути:
public static URL getResource(String path)
{
URL myURL = ClassName.class.getResource(path);
if (null == myURL)
{
mylogger.info("Can't find resource path = ", path);
}
return myURL;
}
-
0Это не отвечает на вопрос.
Примечание: это, вероятно, не очень хорошая идея. Этот метод использует рекурсию и, таким образом, очень быстро ударит по StackOverflowError:
public String read (InputStream is) {
byte next = is.read();
return next == -1 ? "" : next + read(is); // Recursive part: reads next byte recursively
}
Пожалуйста, не отрицайте это только потому, что это плохой выбор; это было в основном креативно :)
-
0Это не просто плохой выбор. Это приведет к
StackOverflowErrorесли входной поток содержит более нескольких сотен символов. -
0@ StefhenC Это плохой выбор, по моему мнению
У меня был log4j, поэтому я смог использовать org.apache.log4j.lf5.util.StreamUtils.getBytes, чтобы получить байты, которые я смог преобразовать в строку, используя String ctor
String result = new String(StreamUtils.getBytes(inputStream));
-
3-1. То, что что-то доступно, не означает, что его следует использовать. Когда вы переключаете провайдера регистрации, вам придется заменить это. Кроме того, похоже, что он является внутренним и не должен использоваться вне log4j.
InputStream IS=new URL("http://www.petrol.si/api/gas_prices.json").openStream();
ByteArrayOutputStream BAOS=new ByteArrayOutputStream();
IOUtils.copy(IS, BAOS);
String d= new String(BAOS.toByteArray(),"UTF-8");
System.out.println(d);
-
0См. Комментарий ChristofferHammarström в ответе HarryLime.
-
0В этом вопросе нет ничего, что отдаленно указывало бы на то, в какую кодировку конвертировать или решение должно быть защищено от любой кодировки.
Во-первых, вы должны знать кодировку строки, которую хотите преобразовать. Поскольку java.io.InputStream работает с базовым массивом байтов, однако строка состоит из массива символов, для которого требуется кодировка, например, UTF-8, JDK примет кодировку по умолчанию, которая берется из
System.getProperty("file.encoding","UTF-8");
byte[] bytes=new byte[inputStream.available()];
inputStream.read(bytes);
String s = new String(bytes);
Если байтовый массив inputStream очень большой, вы можете сделать это в цикле.
-
7От javadocs: Обратите внимание, что хотя некоторые реализации InputStream будут возвращать общее количество байтов в потоке, многие не будут. Никогда не правильно использовать возвращаемое значение этого метода для выделения буфера, предназначенного для хранения всех данных в этом потоке.
-
0Это плохая идея! Не переживайте из-за недопонимания того, что вам
available().
Быстро и просто:
String result = (String)new ObjectInputStream( inputStream ).readObject();
-
1Я получаю
java.io.StreamCorruptedException: invalid stream header -
3
ObjectInputStream- о десериализации, и поток должен соблюдать протокол сериализации для работы, что не всегда верно в контексте этого вопроса.
Ещё вопросы
- 0Реализация моей собственной линзы в Panda3D
- 1какой тип лучше всего подходит для трех радиокнопок?
- 1Влияет ли размер приложения Android на неиспользуемый импорт?
- 0После указания аргумента placer в boost :: bind, почему он опускается при вызове?
- 0Как смоделировать нажатие клавиши или Keyup, когда ссылка нажата с помощью jQuery
- 0Удаление CSS-класса из HTML с помощью jQuery
- 02D массив не заполняется правильно или ...? C ++
- 0Значение неинициализированного поля в классе
- 0как установить кнопку положения внизу?
- 1сохранить несколько каталогов изображений в одном файле после предварительной обработки
- 1как получить значения строки, когда флажок установлен в gridview
- 1Не определено в Sails js «Неправильные атрибуты отправлены на неопределенное»
- 1Как настроить фоновый процесс, используя asyncio как часть модуля
- 1Переменная класса обновления Python
- 0Как проверить поле ввода внутри ng-repeat
- 0Живые данные не отправляются с использованием ненавязчивой проверки MVC 4.5
- 1Группировать массив объектов javascript на основе значения в свой собственный массив объектов
- 1Ошибка сериализации Gson с val в котлине
- 1Лямбда-ошибка Python 3: Истинное значение Серии неоднозначно
- 1Не отображается фактическая ошибка через командную строку в Node.js
- 0GLUT взаимодействие с мышью
- 1Key Listener не работает?
- 0Невозможно использовать возвращаемое значение метода в контексте записи
- 1pyspark - как я могу удалить все дублирующиеся строки (игнорируя определенные столбцы) и не оставляя после себя пары дубликатов?
- 0QSystemTrayIcon не отображается
- 0Пример работы с редактором текстового редактора tinymce не запущен
- 1Как я могу выбрать все подузлы узла, а не всех потомков?
- 0Как я могу вставить количество в эту корзину php
- 1Усечение строки до количества символов X?
- 0Как прочитать конкретное строковое значение с помощью JSoup
- 0Получить видео идентификаторы из плейлиста ID - YouTube API V3
- 1Как использовать Loop для выполнения процедуры хранения в Cosmos-DB / Document-DB?
- 1Панды - создать столбец на основе имен столбцов, на которые есть ссылки в другом столбце
- 0Как MySQL выбирает, какое ведомое устройство отправляет запрос?
- 1Сортировка не работает в области базы данных в моем приложении
- 1Есть ли способ синхронно ждать завершения рекурсивной асинхронной функции в Javascript?
- 0Генерация PDF-файлов в Ionic из pdf-строки, уже сгенерированной на стороне клиента, и сохранение ее на устройстве
- 0удалить регистр из идентификатора элемента перед добавлением правила?
- 1Аварийный запуск native-android с помощью приложения «Task: app: compileDebugJavaWithJavac FAILED» завершился неудачей. После установки response-native-fbsdk
- 1Java вводит десятичные дроби и работает с мнимыми числами
- 1Использование HttpResponseMessage для просмотра ошибок
- 1Java-приложение, которое конвертирует CSV в JSON
- 0Угловое двустороннее приветствие привязки данных
- 0Угловая проверка разрешений JS
- 0Qt: joinMulticastGroup для всего интерфейса
- 1Как исправить ошибку при обновлении targetSdkVersion с версии 25 до 27?
- 1Проблема с D3.JS и Flask - попытка получить карту США
- 0Как использовать PHP монолог
- 0как разбирать в каком то улье?
- 1discord.js Отправить сообщение как кодовый блок?
