Составление приложения для использования в высокорадиоактивных средах
Мы собираем встроенное приложение C/С++, которое развертывается в экранированном устройстве в среде, облученной ионизирующим излучением . Мы используем GCC и кросс-компиляцию для ARM. При развертывании наше приложение генерирует некоторые ошибочные данные и чаще всего падает, что нам хотелось бы. Аппаратное обеспечение предназначено для этой среды, и наше приложение работает на этой платформе в течение нескольких лет.
Могут ли быть внесены изменения в наш код или улучшения времени компиляции, которые могут быть сделаны для идентификации/исправления мягких ошибок и повреждения памяти, вызванного разоблачение одного события? Были ли у каких-либо других разработчиков успехи в снижении вредных последствий мягких ошибок в долгосрочном приложении?
-
169Изменяются ли значения в памяти или значения в процессоре? Если оборудование предназначено для среды, программное обеспечение должно работать так, как будто оно работает в нерадиоактивной среде.Thomas Matthews
-
3Если возможно, вы должны настроить систему регистрации событий, которая хранит события в энергонезависимой памяти, устойчивой к излучению. Храните достаточно информации, чтобы вы могли отследить событие и легко найти основную причину.Thomas Matthews
22 ответа
Работая около 4-5 лет с разработкой ПО/прошивки и тестированием среды миниатюризированных спутников *, я хотел бы поделиться своим опытом здесь.
* (миниатюрные спутники намного более склонны к разовым событиям, чем более крупные спутники из-за относительно небольших, ограниченных размеров для своих электронных компонентов).
Быть очень кратким и прямым: нет механизма для восстановления от обнаруживаемых, ошибочных ситуации с помощью программного обеспечения/самой прошивки без, по крайней мере, одного копия минимальной рабочей версии программного обеспечения/прошивки где-то для цели восстановления - и с аппаратным обеспечением, поддерживающим восстановление (функциональное).
Теперь эту ситуацию обычно обрабатывают как на аппаратном, так и на программном уровне. Здесь, по вашему запросу, я расскажу, что мы можем сделать на уровне программного обеспечения.
-
... цель восстановления.... Предоставляйте возможность обновлять/перекомпилировать/перепрограммировать ваше программное обеспечение/прошивку в реальной среде. Это почти обязательная функция для любого программного обеспечения/прошивки в сильно ионизированной среде. Без этого у вас может быть избыточное программное обеспечение или аппаратное обеспечение столько, сколько вы хотите, но в какой-то момент они все взорвутся. Итак, подготовьте эту функцию!
-
... минимальная рабочая версия... Имейте отзывчивые, множественные копии, минимальную версию программного обеспечения/прошивки в вашем коде. Это похоже на безопасный режим в Windows. Вместо того, чтобы иметь только одну, полностью функциональную версию вашего программного обеспечения, есть несколько копий минимальной версии вашего программного обеспечения/прошивки. Минимальная копия обычно имеет гораздо меньший размер, чем полная копия, и почти всегда имеет только следующие две или три функции:
- способный слушать команду из внешней системы,
- способный обновлять текущее программное обеспечение/прошивку,
- способный отслеживать основные эксплуатационные данные по эксплуатации.
-
... копировать... где-то... У вас есть избыточное программное обеспечение/прошивка.
-
Вы можете с избыточным оборудованием или без него попытаться иметь избыточное программное обеспечение/прошивку в вашем ARM uC. Обычно это делается при наличии двух или более идентичных программ/прошивок в отдельных адресах, которые посылают друг другу сердцебиение, но только один будет активен одновременно. Если известно, что одно или несколько программных/прошивок не реагируют, переключитесь на другое программное обеспечение/прошивку. Преимущество использования этого подхода заключается в том, что мы можем иметь функциональную замену сразу после возникновения ошибки - без какого-либо контакта с какой-либо внешней системой/стороной, которая несет ответственность за обнаружение и исправление ошибки (в случае с сателлитом обычно используется Центр управления полетами ( MCC)).
Строго говоря, без избыточного оборудования недостатком этого является то, что вы на самом деле не можете устранить все отдельные ошибки. По крайней мере, у вас все равно будет одна точка отказа, которая сама является коммутатором (или часто началом кода). Тем не менее, для устройства, ограниченного размером в сильно ионизированной среде (например, спутники pico/femto), сокращение одной точки отказов до одной точки без дополнительного оборудования по-прежнему стоит рассмотреть. Somemore, фрагмент кода для переключения, безусловно, будет намного меньше, чем код для всей программы, что значительно снижает риск получения в нем одного события.
-
Но если вы этого не сделаете, у вас должна быть хотя бы одна копия в вашей внешней системе, которая может соприкасаться с устройством и обновить программное обеспечение/прошивку (в случае с сателлитом это снова миссия центр управления).
- У вас также может быть копия в вашем постоянном хранилище памяти на вашем устройстве, которое может быть запущено для восстановления запущенного программного обеспечения системы/прошивки
-
-
... обнаружимая ошибочная ситуация.Ошибка должна обнаруживаться, как правило, с помощью схемы исправления/обнаружения аппаратной ошибки или небольшим фрагментом кода для исправления/обнаружения ошибок. Лучше всего поставить такой код небольшим, многократным и независимым от основного программного обеспечения/прошивки. Его основная задача - только проверка/исправление. Если аппаратная схема/прошивка надежна (например, она более подвержена воздействию радиации, чем остатки) или имеет несколько схем/логик, то вы можете подумать об исправлении ошибок. Но если это не так, лучше сделать это как обнаружение ошибок. Поправкой может быть внешняя система/устройство. Для исправления ошибок вы можете рассмотреть возможность использования базового алгоритма коррекции ошибок, такого как Hamming/Golay23, потому что они могут быть проще реализованы как в схеме/программном обеспечении. Но это в конечном счете зависит от возможностей вашей команды. Для обнаружения ошибок обычно используется CRC.
-
... аппаратное обеспечение, поддерживающее восстановление. Теперь это самый сложный аспект в этой проблеме. В конечном итоге для восстановления требуется аппаратное обеспечение, которое отвечает за восстановление как минимум функциональное. Если аппаратное обеспечение постоянно повреждено (обычно это происходит после того, как его Общая ионизирующая доза достигает определенного уровня), тогда (к сожалению) нет способа помочь программному обеспечению в восстановлении. Таким образом, аппаратное обеспечение по праву имеет первостепенное значение для устройства, подверженного воздействию высокого уровня излучения (такого как спутник).
В дополнение к предложению выше, предполагающему ошибку прошивки из-за разоблачения одного события, я также хотел бы предложить вам:
-
Алгоритм обнаружения ошибок и/или ошибок в протоколе связи между подсистемами. Это еще один пример, который должен иметься во избежание неполных/неправильных сигналов, полученных от другой системы.
-
Отфильтруйте показания АЦП. Не используйте непосредственно чтение АЦП. Отфильтруйте его средним фильтром, средним фильтром или любыми другими фильтрами - никогда не доверяйте одному значению чтения. Образец больше, не менее - разумно.
В НАСА была статья о радиационно-упрочненном программном обеспечении. Он описывает три основные задачи:
- Регулярный мониторинг памяти для ошибок, затем очистка этих ошибок,
- надежные механизмы восстановления ошибок и
- возможность перенастроить, если что-то больше не работает.
Обратите внимание, что скорость сканирования памяти должна быть достаточно частым, чтобы редко встречались многобитовые ошибки, так как большинство ECC памяти могут восстанавливаться из однобитовых ошибок, а не многобитовые ошибки.
Надежное восстановление ошибок включает в себя передачу потока управления (как правило, перезапуск процесса в точке до ошибки), освобождение ресурсов и восстановление данных.
Их основная рекомендация по восстановлению данных заключается в том, чтобы избежать необходимости в ней, поскольку промежуточные данные обрабатываются как временные, так что перезапуск перед ошибкой также возвращает данные в надежное состояние. Это похоже на концепцию "транзакций" в базах данных.
Они обсуждают методы, особенно подходящие для объектно-ориентированных языков, таких как С++. Например
- Программные ECC для смежных объектов памяти
- Программирование по контракту: проверка предварительных условий и постусловий, а затем проверка объекта для проверки его работоспособности.
-
25Это на самом деле звучит как то, что чистый язык был бы хорош в. Так как значения никогда не меняются, если они повреждены, вы можете просто вернуться к исходному определению (что и должно быть), и вы не будете случайно делать одно и то же дважды (из-за отсутствия побочных эффектов).
-
18RAII - плохая идея, потому что вы не можете полагаться на то, что он работает правильно или вообще не работает. Это может привести к случайному повреждению ваших данных и т. Д. Вы действительно хотите получить как можно больше неизменности, а также механизмы исправления ошибок. Гораздо проще просто выбросить сломанные вещи, чем попытаться как-то их починить (как именно вы знаете достаточно, чтобы вернуться к правильному старому состоянию?). Возможно, вы захотите использовать довольно глупый язык для этого - оптимизация может повредить больше, чем помочь.
Вот некоторые мысли и идеи:
Используйте ПЗУ более творчески.
Храните все, что вы можете в ПЗУ. Вместо того, чтобы вычислять вещи, храните поисковые таблицы в ПЗУ. (Убедитесь, что ваш компилятор выводит ваши поисковые таблицы в раздел только для чтения! Распечатайте адреса памяти во время выполнения, чтобы проверить!) Сохраните таблицу векторов прерываний в ПЗУ. Разумеется, запустите несколько тестов, чтобы убедиться, насколько ваш ПЗУ сравнивается с вашей оперативной памятью.
Используйте свою лучшую оперативную память для стека.
SEU в стеке, вероятно, являются наиболее вероятным источником сбоев, потому что там обычно живут такие вещи, как индексные переменные, переменные состояния, обратные адреса и указатели разных типов.
Реализовать таймер-таймер и контрольные таймеры.
Вы можете запустить процедуру проверки работоспособности каждого таймера, а также процедуру сторожевого таймера для блокировки системы. Ваш основной код также может периодически увеличивать счетчик, указывая на прогресс, и процедура проверки работоспособности может гарантировать, что это произошло.
Внедрить коды исправления ошибок в программном обеспечении.
Вы можете добавить избыточность в свои данные, чтобы иметь возможность обнаруживать и/или исправлять ошибки. Это добавит время обработки, что потенциально может привести к тому, что процессор подвергнется воздействию излучения в течение более длительного времени, что увеличит вероятность ошибок, поэтому вы должны рассмотреть компромисс.
Помните кеши.
Проверьте размеры кэшей процессора. Данные, которые вы недавно получили или изменили, вероятно, находятся в кеше. Я считаю, что вы можете отключить хотя бы некоторые из кэшей (при большой производительности); вы должны попробовать это, чтобы понять, насколько уязвимы кэши для SEU. Если кеши выносливее, чем оперативная память, вы можете регулярно читать и переписывать критические данные, чтобы убедиться, что они остаются в кеше и возвращают RAM обратно.
Использовать обработчики ошибок страницы.
Если вы помечаете страницу памяти как не существующую, то при попытке доступа к ней CPU выдает ошибку страницы. Вы можете создать обработчик ошибок страницы, который выполняет некоторую проверку перед обслуживанием запроса на чтение. (Операционные системы для ПК используют это для прозрачной загрузки страниц, которые были заменены на диск.)
Используйте язык ассемблера для критических вещей (это может быть все).
С ассемблером вы знаете, что находится в регистрах и что находится в ОЗУ; вы знаете, какие специальные таблицы оперативной памяти использует процессор, и вы можете проектировать вещи окольными способами, чтобы снизить риск.
Используйте objdump, чтобы на самом деле посмотреть на сгенерированный язык ассемблера и определить, какой код выполняет каждый из ваших подпрограмм.
Если вы используете большую ОС, такую как Linux, вы просите о неприятностях; есть так много сложности и так много вещей, чтобы пойти не так.
Помните, что это игра с вероятностями.
Комментарий сказал
Каждая рутина, которую вы пишете, чтобы ловить ошибки, будет подвержена самому отказу от одной и той же причины.
Хотя это верно, вероятность ошибок в (скажем) 100 байт кода и данных, необходимых для правильной работы проверки, намного меньше, чем вероятность ошибок в других местах. Если ваш ПЗУ достаточно надежный, и почти весь код/данные на самом деле находятся в ПЗУ, ваши шансы еще лучше.
Использовать избыточное оборудование.
Используйте 2 или более идентичные аппаратные настройки с идентичным кодом. Если результаты отличаются друг от друга, необходимо запустить reset. С 3 или более устройствами вы можете использовать систему голосования, чтобы попытаться определить, какой из них был скомпрометирован.
-
13В настоящее время есть ECC, доступный через аппаратное обеспечение, которое экономит время обработки. Первый шаг - выбрать микроконтроллер со встроенным ECC.
-
22Где-то в глубине моего сознания есть отсылка к аппаратному обеспечению авионики (возможно, космического челнока?), Где избыточная архитектура была явно разработана, чтобы не быть идентичной (и разными командами). Это уменьшает вероятность системной ошибки в конструкции аппаратного / программного обеспечения, уменьшая вероятность одновременного сбоя всех систем голосования при столкновении с одинаковыми входными данными.
Вы также можете быть заинтересованы в богатой литературе по предмету алгоритмической отказоустойчивости. Это включает в себя старое назначение: напишите сортировку, которая правильно сортирует свой вход, когда число постоянных сравнений будет терпеть неудачу (или немного более злая версия, когда асимптотическое число неудачных сравнений оценивается как log(n) для сравнений n).
Место для начала чтения - статья Хуанга и Авраама 1984 года "" Отказоустойчивость на основе алгоритмов для матричных операций". Их идея смутно похожа на гомоморфные зашифрованные вычисления (но это не совсем то же самое, поскольку они пытаются обнаружить/исправлять ошибки на рабочем уровне).
Более поздним потомком этой статьи являются Bosilca, Delmas, Dongarra и Langou " Алгоритмическая отказоустойчивость, применяемая для высокопроизводительных вычислений".
-
4Мне очень нравится ваш ответ. Это более общий программный подход к целостности данных, и в нашем конечном продукте будет использовано решение по отказоустойчивости на основе алгоритмов. Спасибо!
Код записи для радиоактивных сред на самом деле не отличается от написания кода для любого критически важного приложения.
В дополнение к тому, что уже было упомянуто, вот несколько разных советов:
- Используйте ежедневные меры безопасности "хлеб и масло", которые должны присутствовать на любой полупрофессиональной встроенной системе: внутренний сторожевой таймер, внутреннее детектирование низкого напряжения, внутренний монитор часов. Эти вещи не нужно даже упоминать в 2016 году, и они стандартизированы практически во всех современных микроконтроллерах.
- Если у вас есть безопасный и/или автомобильный MCU, у него будут определенные функции сторожевого таймера, такие как заданное временное окно, внутри которого необходимо обновить сторожевой таймер. Это предпочтительнее, если у вас есть критически важная система реального времени.
- В общем, используйте MCU, подходящий для таких систем, а не какой-нибудь общий пух, который вы получили в пакете кукурузных хлопьев. Почти каждый производитель MCU в настоящее время имеет специализированные микроконтроллеры, предназначенные для приложений безопасности (TI, Freescale, Renesas, ST, Infineon и т.д.). Они имеют множество встроенных функций безопасности, включая ядра блокировки: это означает, что есть два ядра ЦП, выполняющих один и тот же код, и они должны соглашаться друг с другом.
-
ВАЖНО: вы должны обеспечить целостность внутренних регистров MCU. Все регистры управления и состояния аппаратных периферийных устройств, которые могут быть записаны, могут быть расположены в ОЗУ и поэтому уязвимы.
Чтобы защитить себя от сбоев в регистрации, желательно выбрать микроконтроллер со встроенными функциями "write-once" регистров. Кроме того, вам необходимо хранить значения по умолчанию всех аппаратных регистров в NVM и регулярно копировать эти значения в свои регистры. Вы можете обеспечить целостность важных переменных таким же образом.
Примечание: всегда используйте защитное программирование. Это означает, что вам нужно настроить все регистры в MCU, а не только те, которые используются приложением. Вы не хотите внезапно просыпаться случайное аппаратное периферийное устройство.
-
Существуют всевозможные способы проверки ошибок в ОЗУ или NVM: контрольные суммы, "шаблоны ходьбы", программное обеспечение ECC и т.д. Самое лучшее решение в наши дни - не использовать ни одно из них, а использовать MCU с встроенным ECC и аналогичными проверками. Поскольку выполнение этого в программном обеспечении является сложным, и сама проверка ошибок может привести к ошибкам и неожиданным проблемам.
- Использовать избыточность. Вы можете хранить как энергозависимую, так и энергонезависимую память в двух идентичных "зеркальных" сегментах, которые всегда должны быть эквивалентными. Каждый сегмент может иметь контрольную сумму CRC.
- Избегайте использования внешних запоминающих устройств вне MCU.
- Реализация функции обработки прерываний по умолчанию/обработчика исключений по умолчанию для всех возможных прерываний/исключений. Даже те, которые вы не используете. Программа по умолчанию не должна ничего делать, кроме отключения собственного источника прерывания.
-
Понять и принять концепцию защитного программирования. Это означает, что ваша программа должна обрабатывать все возможные случаи, даже те, которые не могут возникнуть в теории. Примеры.
Высококачественная критически важная прошивка обнаруживает как можно больше ошибок, а затем игнорирует их безопасным образом.
- Никогда не пишите программы, которые полагаются на плохо определенное поведение. Вполне вероятно, что такое поведение может резко измениться с неожиданными аппаратными изменениями, вызванными излучением или электромагнитными помехами. Лучший способ гарантировать, что ваша программа свободна от такого дерьма, - использовать стандарт кодирования, такой как MISRA, вместе со средством статического анализатора. Это также поможет в защитном программировании и устранении ошибок (почему вы не хотите обнаруживать ошибки в любом приложении?).
-
ВАЖНО: не используйте какую-либо зависимость значений по умолчанию от статических переменных продолжительности хранения. То есть не доверяйте содержимому по умолчанию
.dataили.bss. Между точкой инициализации до точки, где фактически используется переменная, может быть любое количество времени, возможно, было достаточно времени для того, чтобы ОЗУ получило повреждение. Вместо этого напишите программу так, чтобы все такие переменные были установлены из NVM во время выполнения, незадолго до того момента, когда такая переменная используется в первый раз.На практике это означает, что если переменная объявлена в области файлов или в качестве
static, вы никогда не должны использовать=для ее инициализации (или можете, но это бессмысленно, потому что вы не можете полагаться на значение так или иначе). Всегда устанавливайте его во время выполнения, как раз перед использованием. Если можно многократно обновлять такие переменные из NVM, сделайте это.Аналогично в С++ не полагайтесь на конструкторы для переменных статической продолжительности хранения. Попросите конструктора (-ов) вызвать общедоступную "настройку", которую вы также можете вызвать позже во время выполнения, прямо из приложения-вызывающего.
Если возможно, удалите код запуска "copy-down", который полностью инициализирует
.dataи.bss(и вызывает конструкторы С++), так что вы получаете ошибки компоновщика, если вы пишете код, полагающийся на такой. Многие компиляторы имеют возможность пропустить это, обычно называемое "минимальным/быстрым запуском" или аналогичным.Это означает, что любые внешние библиотеки должны быть проверены, чтобы они не содержали такой уверенности.
-
Внедрить и определить безопасное состояние для программы, где вы вернетесь в случае критических ошибок.
- Внедрение системы отчетов об ошибках/журнала ошибок всегда полезно.
-
0Один из способов справиться с повреждением логических значений (как в вашем примере ссылки) мог бы сделать
TRUEравным0xffffffffзатем использоватьPOPCNTс порогом. -
0@ wizzwizz4 Учитывая, что значение 0xff является значением по умолчанию для непрограммированной флэш-ячейки, это звучит как плохая идея.
Возможно, можно использовать C для написания программ, которые ведут себя устойчиво в таких средах, но только в том случае, если большинство форм оптимизации компилятора отключены. Оптимизация компиляторов предназначена для замены многих, казалось бы, избыточных шаблонов кодирования на "более эффективные", и, возможно, не имеет понятия, что причина, по которой программист тестирует x==42, когда компилятор знает, что нет способа x потому что программист хочет предотвратить выполнение определенного кода с x, удерживая какое-то другое значение, даже в тех случаях, когда единственным способом, которым он мог бы удерживать это значение, было бы, если система получила какой-то электрический сбой.
Объявление переменных как volatile часто полезно, но не может быть панацеей.
Особо важно отметить, что безопасное кодирование часто требует, чтобы опасные
операции имеют аппаратные блокировки, требующие нескольких шагов для активации,
и этот код записывается с использованием шаблона:
... code that checks system state
if (system_state_favors_activation)
{
prepare_for_activation();
... code that checks system state again
if (system_state_is_valid)
{
if (system_state_favors_activation)
trigger_activation();
}
else
perform_safety_shutdown_and_restart();
}
cancel_preparations();
Если компилятор переводит код относительно буквальным образом, и если все
проверки состояния системы повторяются после prepare_for_activation(),
система может быть устойчивой к практически любому правдоподобному событию с одним сбоем,
даже те, которые произвольно испортили бы счетчик программ и стек. Если
сбой происходит сразу после вызова prepare_for_activation(), что подразумевает
что активация была бы подходящей (поскольку нет другой причины
prepare_for_activation() было бы вызвано до сбоя). Если
сбой приводит к тому, что код достигает prepare_for_activation() ненадлежащим образом, но там
не являются последующими событиями с ошибками, не будет никакого способа для последующего кода
достигните trigger_activation(), не пройдя проверку проверки или сначала вызвав cancel_preparations [если глюк стека, выполнение может перейти к месту непосредственно перед trigger_activation() после возврата контекста, который вызвал prepare_for_activation(), но вызов cancel_preparations() произошли между вызовами prepare_for_activation() и trigger_activation(), тем самым делая последний вызов безвредным.
Такой код может быть безопасным в традиционном C, но не в современных компиляторах C. Такие компиляторы могут быть очень опасны в такой среде, потому что агрессивные они стремятся включить только код, который будет иметь значение в ситуациях, которые могут возникнуть через какой-то четко определенный механизм и чьи последствия будут также хорошо определены. Код, целью которого является обнаружение и очистка после сбоев, может в некоторых случаях ухудшить ситуацию. Если компилятор определяет, что попытка восстановления в некоторых случаях вызывает поведение undefined, он может сделать вывод о том, что условия, которые потребуют такого восстановления в таких случаях, не могут произойти, тем самым устраняя код, который был бы проверен для них.
-
6Реально говоря, сколько современных компиляторов, которые не предлагают
-O0или эквивалентный переключатель? GCC будет делать много странных вещей, если вы дадите ему разрешение , но если вы попросите его не делать этого, он, как правило, тоже может быть довольно буквальным. -
22Извините, но эта идея принципиально опасна. Отключение оптимизации приводит к более медленной программе. Или, другими словами, вам нужен более быстрый процессор. Как это бывает, более быстрые процессоры быстрее, потому что заряды на их транзисторных затворах меньше. Это делает их гораздо более восприимчивыми к радиации. Лучшая стратегия состоит в том, чтобы использовать медленный, большой чип, где один фотон с гораздо меньшей вероятностью может немного опрокинуться, и вернуть скорость с
-O2.
Это очень широкий предмет. В принципе, вы действительно не можете восстановить повреждение памяти, но вы можете хотя бы попытаться быстро выполнить. Вот несколько методов, которые вы могли бы использовать:
-
данные контрольной суммы. Если у вас есть какие-либо данные конфигурации, которые остаются постоянными в течение длительного времени (включая настроенные аппаратные регистры), вычислите его контрольную сумму при инициализации и проверите ее периодически. Когда вы видите несоответствие, время для повторной инициализации или reset.
-
хранить переменные с резервированием. Если у вас есть важная переменная
x, напишите ее значение вx1,x2иx3и прочитайте ее как(x1 == x2) ? x2 : x3. -
реализовать мониторинг потока программ. XOR - глобальный флаг с уникальным значением в важных функциях/ветвях, вызываемых из основного цикла. Запуск программы в безрисковой среде с почти 100% -ным охватом тестирования должен дать вам список допустимых значений флага в конце цикла. Reset, если вы видите отклонения.
-
отслеживать указатель стека. В начале основного цикла сравните указатель стека с его ожидаемым значением. Reset при отклонении.
Что может вам помочь - watchdog. В 1980-х годах сторожевые псы широко использовались в промышленных вычислениях. Аппаратные сбои были гораздо более распространены тогда - другой ответ также относится к этому периоду.
Watchdog - это комбинированная аппаратная/программная функция. Аппаратное обеспечение - это простой счетчик, который отсчитывает от числа (например, 1023) до нуля. TTL или другая логика.
Программное обеспечение разработано таким образом, что одна рутина контролирует правильную работу всех основных систем. Если эта процедура завершится правильно = обнаруживает, что компьютер работает нормально, он устанавливает счетчик обратно на 1023.
Общая конструкция такова, что при нормальных обстоятельствах программное обеспечение предотвращает достижение нуля счетчика оборудования. Если счетчик достигает нуля, аппаратное обеспечение счетчика выполняет свою единственную задачу и сбрасывает всю систему. С точки зрения счетчика, нуль равен 1024, и счетчик продолжает отсчет снова.
Этот сторожевой таймер гарантирует перезагрузку подключенного компьютера во многих случаях отказа. Должен признать, что я не знаком с оборудованием, которое может выполнять такую функцию на сегодняшних компьютерах. Интерфейсы для внешнего оборудования теперь намного сложнее, чем раньше.
Врожденным недостатком сторожевого таймера является то, что система недоступна с момента ее провала, пока счетчик сторожевого таймера не достигнет нуля + время перезагрузки. Хотя это время, как правило, намного короче любого внешнего или человеческого вмешательства, поддерживаемое оборудование должно будет продолжать работать без управления компьютером на этот таймфрейм.
-
9Бинарные счетчики со стандартными микросхемами TTL действительно являются решением 1980-х годов. Не делай этого. Сегодня на рынке не существует ни одного MCU без встроенной схемы сторожевого таймера. Все, что вам нужно проверить, - это если встроенный сторожевой таймер имеет отдельный источник синхронизации (хорошо, скорее всего, так) или он наследует свои часы от системных часов (плохо).
-
1Или внедрите сторожевой таймер в FPGA: ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/20130013486.pdf
В этом ответе предполагается, что у вас есть система, которая работает правильно, сверх того, у которой минимальная стоимость или скорость системы; большинство людей, играющих с радиоактивными вещами, ценят правильность/безопасность по скорости/стоимости
Несколько человек предложили аппаратные изменения, которые вы можете сделать (хорошо - там много хороших вещей здесь, в ответах уже, и я не собираюсь повторять все это), а другие предложили избыточность (в принципе это принципиально), но я Думаю, кто-то предложил, как это избыточность может работать на практике. Как вы терпите неудачу? Откуда вы знаете, когда что-то "пошло не так"? Многие технологии работают на основе того, что все будет работать, и неудача, таким образом, является сложной задачей. Однако некоторые распределенные вычислительные технологии, разработанные для масштабирования, ожидают неудачи (ведь с достаточным масштабом неудача одного node из многих неизбежна с любым MTBF для одного node); вы можете использовать это для своей среды.
Вот несколько идей:
-
Убедитесь, что все ваше оборудование реплицировано
nраз (гдеnбольше 2, а предпочтительно нечетно) и что каждый аппаратный элемент может связываться друг с другом аппаратным элементом. Ethernet - один из очевидных способов сделать это, но есть много других гораздо более простых маршрутов, которые обеспечивали бы лучшую защиту (например, CAN). Минимизируйте общие компоненты (даже источники питания). Это может означать, например, выборки АЦП в нескольких местах. -
Убедитесь, что состояние вашего приложения находится в одном месте, например. в машине конечного состояния. Это может быть полностью основано на ОЗУ, но не исключает стабильного хранения. Таким образом, он будет храниться в нескольких местах.
-
Принять протокол кворума для изменения состояния. Например, смотрите RAFT. Поскольку вы работаете на С++, для этого существуют хорошо известные библиотеки. Изменения в FSM будут сделаны только тогда, когда большинство узлов согласуются. Используйте известную хорошую библиотеку для стека протоколов и протокол кворума, а не скатывайте самостоятельно, или вся ваша хорошая работа по избыточности будет потрачена впустую, когда протокол кворума зависает.
-
Обеспечьте контрольную сумму (например, CRC/SHA) вашего FSM и сохраните CRC/SHA в самом FSM (а также передайте в сообщении и проверив сами сообщения). Получите узлы, чтобы регулярно проверять их FSM на эту контрольную сумму, входящие сообщения контрольной суммы и проверять их контрольную сумму на контрольную сумму кворума.
-
Постройте как можно больше внутренних проверок в вашей системе, создавая узлы, которые обнаруживают свою собственную перезагрузку отказа (это лучше, чем переносить половину работы, если у вас достаточно узлов). Попытайтесь позволить им очистить себя от кворума во время перезагрузки, если они не появятся снова. При перезагрузке имейте контрольную сумму программного образа (и всего остального, что они загружают), и выполняйте полный тест RAM, прежде чем повторно вводить себя в кворум.
-
Используйте оборудование для поддержки, но делайте это осторожно. Например, вы можете получить ОЗУ ECC и регулярно читать/записывать через него для исправления ошибок ECC (и паники, если ошибка не исправляется). Однако (из памяти) статическая ОЗУ гораздо более терпима к ионизирующей радиации, чем DRAM, в первую очередь, поэтому лучше использовать статическую DRAM. См. Первый пункт под "вещами, которые я бы не сделал".
Скажем, у вас есть 1% -ный шанс выхода из строя любого данного node в течение одного дня, и пусть притворяется, что вы можете сделать неудачи полностью независимыми. С 5 узлами вам понадобится три, чтобы провалиться в течение одного дня, что является вероятностью .00001%. Более того, вы получите эту идею.
Вещи, которые я бы не сделал:
-
Недооценить значение, которое не имеет проблемы для начала. Если вес не вызывает беспокойства, большой блок металла вокруг вашего устройства будет намного дешевле и надежнее, чем может предложить команда программистов. Точно оптическое соединение входов EMI является проблемой и т.д. Независимо от того, пытаетесь ли вы подключить ваши компоненты к источникам, которые лучше всего подходят для ионизирующего излучения.
-
Создайте собственные алгоритмы. Люди делали это раньше. Используйте их работу. Отказоустойчивость и распределенные алгоритмы сложны. По возможности используйте других людей.
-
Используйте сложные настройки компилятора в наивной надежде, что вы обнаружите больше сбоев. Если вам повезет, вы можете обнаружить больше сбоев. Скорее всего, вы будете использовать код-код в компиляторе, который был менее проверен, особенно если вы сами его выполнили.
-
Использовать методы, не прошедшие проверку в вашей среде. Большинство людей, пишущих программное обеспечение высокой доступности, должны моделировать режимы отказа, чтобы проверить работоспособность их HA, и, в результате, пропустить многие режимы отказа. Вы находитесь в "счастливой" позиции с частыми неудачами по требованию. Поэтому проверяйте каждую технику и убедитесь, что ее применение действительно улучшает MTBF на сумму, превышающую сложность ее внедрения (при сложностях возникают ошибки). Особенно примените это к моим рекомендациям по алгоритму кворума и т.д.
-
2Ethernet, вероятно, не очень хорошая идея для использования в критически важных приложениях. I2C также не находится вне самой платы. Кое-что грубое как CAN было бы намного более подходящим.
-
1@ Lundin Справедливо, хотя все оптически подключенное (включая Ethernet) должно быть в порядке.
Поскольку вы специально запрашиваете программные решения и используете С++, почему бы не использовать перегрузку оператора, чтобы создавать собственные безопасные типы данных? Например:
Вместо использования uint32_t (и double, int64_t и т.д.) создайте свой собственный SAFE_uint32_t, который содержит несколько (минимум 3) из uint32_t. Перегрузите все операции, которые вы хотите (* + -/< < → = ==!= И т.д.), Чтобы выполнить перегруженные операции независимо от каждого внутреннего значения, т.е. Не делать это один раз и копировать результат. И до, и после убедитесь, что все внутренние значения совпадают. Если значения не совпадают, вы можете обновить неверный до значения с наиболее распространенным. Если нет наиболее распространенного значения, вы можете спокойно уведомить об ошибке.
Таким образом, не имеет значения, происходит ли коррупция в ALU, регистры, оперативная память или на шине, вы все равно будете иметь несколько попыток и очень хорошие шансы поймать ошибки. Однако обратите внимание, что это работает только для переменных, которые вы можете заменить - ваш указатель стека, например, будет по-прежнему восприимчивым.
Боковая история: у меня возникла аналогичная проблема, также на старом чипе ARM. Оказалось, что это инструментальная цепочка, в которой использовалась старая версия GCC, которая вместе с конкретным чипом, который мы использовали, вызвала ошибку в некоторых случаях кросс, которые (иногда) передавали коррумпированные значения в функции. Убедитесь, что у вашего устройства нет никаких проблем, прежде чем обвинять его в радио-активности, и да, иногда это ошибка компилятора =)
-
1Некоторые из этих предложений основаны на аналогичном подходе «многоуровневой проверки работоспособности» для обнаружения коррупции, мне действительно нравится этот, с предложением наиболее критичных для безопасности пользовательских типов данных, хотя
-
1В мире существуют системы, в которых каждый резервный узел проектировался и разрабатывался разными группами, причем арбитр следил за тем, чтобы они случайно не остановились на одних и тех же решениях. Таким образом, вы не получаете их всех для одной и той же ошибки, и похожие переходные процессы не проявляют схожих режимов отказа.
Отказ от ответственности: я не профессионал в области радиоактивности и не работал для такого приложения. Но я работал над мягкими ошибками и избыточности для долговременного архивирования критических данных, что несколько связано (одна и та же проблема, разные цели).
Основная проблема с радиоактивностью, на мой взгляд, заключается в том, что радиоактивность может переключать биты, поэтому радиоактивность может/будет изменять любую цифровую память. Эти ошибки обычно называются мягкие ошибки, бит-гниль и т.д.
Вопрос заключается в следующем: как надежно вычислить, когда ваша память ненадежна?
Чтобы значительно снизить скорость мягких ошибок (за счет вычислительных издержек, поскольку в основном это программные решения), вы можете:
-
полагаются на старую схему резервирования, а точнее - более эффективную коды исправления ошибок (такие же цели, но более умные алгоритмы, чтобы вы могли восстановить больше бит с меньшей избыточностью). Это иногда (ошибочно) также называют контрольным суммированием. С помощью такого решения вам нужно будет в любой момент сохранить полное состояние вашей программы в главной переменной/классе (или структуре?), Вычислить ECC и проверить правильность ECC, прежде чем что-либо делать, и если не ремонтировать поля. Это решение, однако, не гарантирует, что ваше программное обеспечение может работать (просто потому, что оно будет работать правильно, когда это возможно, или перестанет работать, если нет, потому что ECC может сказать вам, что-то не так, и в этом случае вы можете остановить свое программное обеспечение, чтобы вы не получайте поддельные результаты).
-
или вы можете использовать отказоустойчивые алгоритмические структуры данных, которые гарантируют, до некоторой степени, что ваша программа все равно даст правильные результаты даже при наличии мягких ошибок. Эти алгоритмы можно рассматривать как сочетание общих алгоритмических структур с схемами ECC, изначально смешанными, но это гораздо более устойчиво, чем это, потому что схема отказоустойчивости тесно связана с структурой, так что вам не нужно кодировать дополнительные процедуры чтобы проверить ECC, и, как правило, они намного быстрее. Эти структуры обеспечивают возможность гарантировать, что ваша программа будет работать в любых условиях, вплоть до теоретической границы мягких ошибок. Вы также можете смешивать эти устойчивые структуры с схемой резервирования /ECC для дополнительной безопасности (или кодировать ваши наиболее важные структуры данных как устойчивые, а остальные - расходные данные, которые вы можете перекомпилировать из основных структур данных, в качестве нормальных структур данных с бит ECC или проверка четности, которая очень быстро вычисляется).
Если вас интересуют устойчивые структуры данных (это последнее, но захватывающее, новое поле в области алгоритмики и избыточности), я советую вам прочитать следующие документы:
-
Встраиваемые структуры данных алгоритмов Джузеппе Ф. Илиано, Universita di Roma "Tor Vergata"
-
Christiano, P., Demaine, E. D., and Kishore, S. (2011). Отказоустойчивые отказоустойчивые структуры данных с накладными расходами. В алгоритмах и структурах данных (стр. 243-254). Springer Berlin Heidelberg.
-
Ферраро-Петрильо, У., Грандони, Ф. и Итальяно, Г. Ф. (2013). Структуры данных, устойчивые к ошибкам памяти: экспериментальное исследование словарей. Journal of Experimental Algorithmics (JEA), 18, 1-6.
-
Italiano, G. F. (2010). Устойчивые алгоритмы и структуры данных. В алгоритмах и сложностях (стр. 13-24). Springer Berlin Heidelberg.
Если вам интересно узнать больше о области устойчивых структур данных, вы можете проверить работы Giuseppe F. Italiano (и проделайте свой путь через refs) и модель Faulty-RAM (представленная в Finocchi et al., 2005; Finocchi and Italiano 2008).
/EDIT: Я проиллюстрировал предупреждение/восстановление от мягких ошибок, главным образом, для ОЗУ и хранения данных, но я не говорил о ошибках вычисления (CPU). Другие ответы уже указывали на использование атомных транзакций, например, в базах данных, поэтому я предлагаю другую, более простую схему: избыточность и большинство голосов.
Идея состоит в том, что вы просто выполняете x раз такое же вычислениедля каждого вычисления, которое вам нужно сделать, и сохранить результат в x разных переменных (с x >= 3). Затем вы можете сравнить переменные x:
- если все согласны, тогда нет никакой ошибки вычисления.
- Если они не согласны, тогда вы можете использовать большинство голосов, чтобы получить правильное значение, и поскольку это означает, что вычисление было частично повреждено, вы также можете запустить сканирование состояния системы/программы, чтобы проверить, что все в порядке.
- Если большинство голосов не может определить победителя (все значения x различны), тогда это идеальный сигнал для запуска процедуры отказоустойчивости (перезагрузка, повышение оповещения пользователя и т.д.).
Эта схема резервирования очень быстро по сравнению с ECC (практически O (1)) и предоставляет вам сигнал очистки, когда вам нужно отказоустойчивое. Большинство голосов также (почти) гарантировано никогда не выдают поврежденный выход, а также восстанавливаются из-за незначительных ошибок вычисления, поскольку вероятность того, что вычисления x дают один и тот же результат, бесконечно мала ( потому что существует огромное количество возможных выходов, практически невозможно случайным образом получить в 3 раза то же самое, еще меньше шансов, если x > 3).
Таким образом, с большинством голосов вы защищены от поврежденного вывода и с избыточностью x == 3, вы можете восстановить 1 ошибку (при x == 4 это будет 2 ошибки восстановления и т.д. - точное уравнение nb_error_recoverable == (x-2) где x - количество повторений вычислений, потому что вам нужно как минимум 2 согласованных расчета для восстановления с использованием большинства голосов).
Недостаток заключается в том, что вам нужно вычислить x раз, а не один раз, так что у вас есть дополнительные вычислительные затраты, но линейная сложность, поэтому асимптотически вы не теряете много преимуществ, которые вы получаете. Быстрый способ сделать большинство голосов - вычислить режим в массиве, но вы также можете использовать медианный фильтр.
Кроме того, если вы хотите удостовериться, что расчеты выполнены правильно, если вы можете создать собственное оборудование, вы можете построить свое устройство с помощью x процессоров и подключить систему, чтобы вычисления автоматически дублировались по x процессорам с мажоритарное голосование сделано механически в конце (например, с использованием ворот И/ИЛИ). Это часто реализуется в самолетах и критически важных устройствах (см. тройное модульное резервирование). Таким образом, у вас не было бы вычислительных накладных расходов (так как дополнительные вычисления будут выполняться параллельно), и у вас есть еще один уровень защиты от мягких ошибок (поскольку дублирование вычислений и большинство голосов будут управляться непосредственно аппаратными средствами, а не программное обеспечение, которое может быть более легко повреждено, поскольку программа представляет собой просто бит, хранящийся в памяти...).
Кажется, что одна точка больше не упоминается. Вы говорите, что работаете в GCC и перекрестно скомпилируете ARM. Откуда вы знаете, что у вас нет кода, который делает предположения о свободной ОЗУ, размере целого числа, размере указателя, сколько времени требуется для выполнения определенной операции, как долго система будет работать непрерывно или что-то вроде этого? Это очень распространенная проблема.
Ответ - это, как правило, автоматическое модульное тестирование. Напишите тестовые жгуты, которые используют код в системе разработки, затем запустите те же тестовые жгуты в целевой системе. Ищите различия!
Также проверьте наличие ошибок на встроенном устройстве. Вы можете найти там что-то о "не делайте этого, потому что он сбой, поэтому включите этот параметр компилятора, и компилятор будет работать вокруг него".
Короче говоря, ваш наиболее вероятный источник сбоев - это ошибки в вашем коде. До тех пор, пока вы не заметите, что это не так, не беспокойтесь (еще) о более эзотерических режимах отказа.
-
1Действительно, нигде в тесте вопроса автор не упоминает, что было обнаружено, что приложение отлично работает вне радиоактивной среды.
Вам нужны 3-х ведомые машины с мастером вне радиационной среды. Все операции ввода-вывода проходят через мастер, который содержит механизм голосования и/или повтора. Ведомые должны иметь сторожевой таймер для каждого из них, и вызов для их вызова должен быть окружен CRC или тому подобным, чтобы уменьшить вероятность непроизвольного удара. Bumping должен контролироваться мастером, поэтому потерянное соединение с мастером равно перезагрузке в течение нескольких секунд.
Одно из преимуществ этого решения заключается в том, что вы можете использовать тот же API для ведущего, что и для ведомых устройств, поэтому избыточность становится прозрачной функцией.
Изменить: Из комментариев я чувствую необходимость уточнить "идею CRC". Возможность подчиненного буксирования его собственного сторожевого таймера близка к нулю, если вы окружаете удар с помощью CRC или перевариваете проверки случайных данных от мастера. Эти случайные данные отправляются только от мастера, когда подчиненный подконтроль выравнивается с другими. Случайные данные и CRC/дайджест немедленно очищаются после каждого удара. Частота релаксации ведущего-ведомого должна быть больше double тайм-аута сторожевого таймера. Данные, отправленные от мастера, генерируются уникально каждый раз.
-
6Я пытаюсь понять сценарий, в котором вы можете иметь мастера вне радиационной среды, способного надежно общаться с рабами в радиационной среде, когда вы не можете просто разместить рабов вне радиационной среды.
-
1@fostandy: ведомые устройства либо измеряют, либо управляют, используя оборудование, для которого требуется контроллер. Скажи счетчик Гейгера. Ведущий не нуждается в надежной связи из-за избыточности подчиненного устройства.
Кто-то упомянул об использовании более медленных чипов, чтобы не допустить, чтобы ионы сбрасывали биты. Аналогичным образом, возможно, используется специализированный CPU/RAM, который фактически использует несколько бит для хранения одного бита. Таким образом, обеспечивается аппаратная отказоустойчивость, потому что было бы очень маловероятно, чтобы все биты были перевернуты. Итак, 1 = 1111, но нужно было бы получить 4 раза, чтобы фактически перевернуться. (4 может быть плохим числом, поскольку, если 2 бита перевернут его уже неоднозначным). Таким образом, если вы идете с 8, вы получаете в 8 раз меньше бара и немного более медленное время доступа, но гораздо более надежное представление данных. Вероятно, вы можете сделать это как на уровне программного обеспечения, так и со специализированным компилятором (выделить x больше места для всего) или языковой реализацией (писать оболочки для структур данных, которые распределяют вещи таким образом). Или специализированное оборудование, которое имеет одну и ту же логическую структуру, но делает это в прошивке.
То, что вы задаете, - довольно сложная тема - нелегко ответить. Другие ответы в порядке, но они охватывают лишь небольшую часть всех вещей, которые вам нужно сделать.
Как видно из комментариев, невозможно устранить аппаратные проблемы на 100%, однако с высокой вероятностью можно уменьшить или уловить их с помощью различных методов.
Если бы я был вами, я бы создал программное обеспечение самого высокого уровня Уровень целостности безопасности (SIL-4). Получите документ IEC 61513 (для ядерной промышленности) и следуйте за ним.
-
11Или, скорее, прочитайте технические требования и реализуйте те, которые имеют смысл. Большая часть стандартов SIL - это нонсенс, если вы будете следовать им догматически, вы получите небезопасные и опасные продукты. Сегодня сертификация SIL в основном сводится к производству тонны документации, а затем к подкупу тестового дома. Уровень SIL ничего не говорит о фактической безопасности системы. Вместо этого вы захотите сосредоточиться на реальных технических мерах безопасности. В документах SIL есть несколько очень хороших, и есть несколько полных бессмысленных.
Как запустить много экземпляров вашего приложения. Если сбои происходят из-за случайных изменений бита памяти, скорее всего, некоторые из ваших экземпляров приложения пройдут и получат точные результаты. Вероятно, довольно легко (для кого-то со статистическим фоном) рассчитать, сколько экземпляров вам понадобится, чтобы бит-флоп мог достичь как крошечной общей ошибки, как вы пожелаете.
-
2Конечно, встроенная система предпочла бы критические уловы безопасности в одном экземпляре надежного приложения, чем просто запускать несколько экземпляров, повышая требования к оборудованию и в некоторой степени надеясь на слепую удачу, что хотя бы один экземпляр справится, ладно? Я понял идею, и она верна, но больше склоняюсь к предложениям, которые не опираются на грубую силу
Возможно, это поможет узнать, означает ли это, что аппаратное обеспечение "предназначено для этой среды". Как он исправляет и/или указывает на наличие ошибок SEU?
В одном проекте, связанном с исследованием космоса, у нас был специальный MCU, который мог бы вызвать исключение/прерывание ошибок SEU, но с некоторой задержкой, то есть некоторые циклы могут проходить/инструкции выполняться после одного insn, вызвавшего исключение SEU.
Особенно уязвимым был кеш данных, поэтому обработчик сделал бы недействительным строку оскорбительного кэша и перезапустил программу. Только это из-за неточного характера исключения последовательность insns, возглавляемая исключающим insn, не может быть перезапущена.
Мы идентифицировали опасные (не перезапускаемые) последовательности (например, lw $3, 0x0($2), а затем insn, который изменяет $2 и не зависит от данных от $3), и я вносил изменения в GCC, поэтому такие последовательности (например, в крайнем случае, разделяя два insns на nop).
Просто подумать...
Если ваше оборудование выходит из строя, вы можете использовать механическое хранилище для его восстановления. Если ваша база кода мала и имеет некоторое физическое пространство, вы можете использовать механическое хранилище данных.
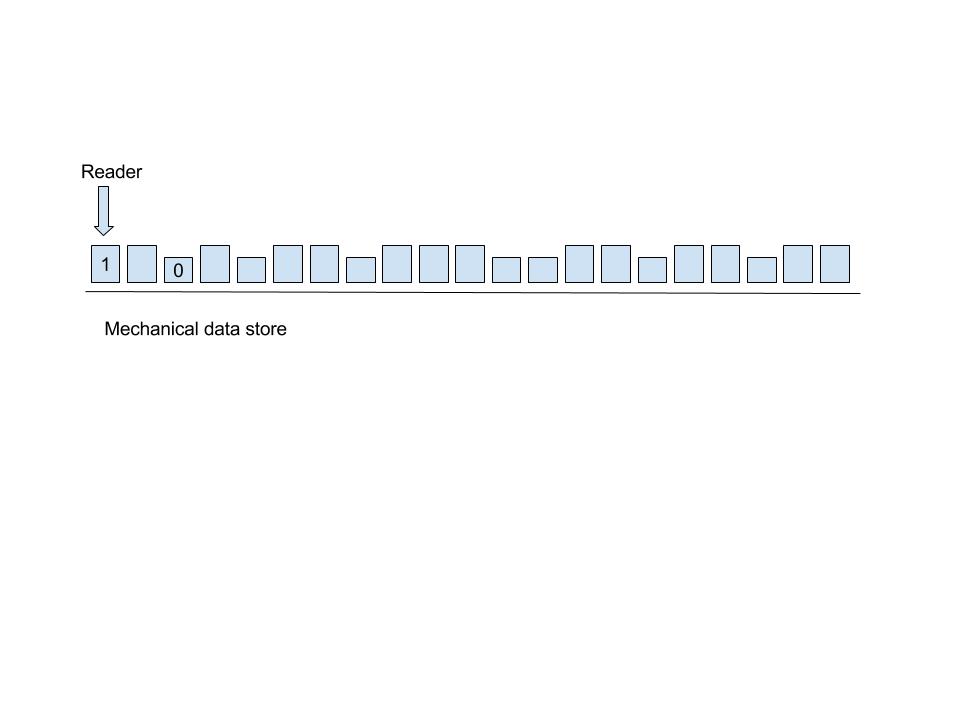
Будет поверхность материала, на которую не будет влиять излучение. Там будет множество передач. Механический считыватель будет работать на всех передачах и будет гибким для перемещения вверх и вниз. Вниз означает, что оно равно 0, а вверх означает, что оно равно 1. От 0 до 1 вы можете сгенерировать свою базу кода.
-
2Возможно, оптический носитель, такой как CD-ROM, будет соответствовать этому определению. Это будет иметь дополнительный бонус большой емкости.
-
2Да, это будет похоже, но CD-ROM будет использовать меньше, но это будет полностью механическая система.
Используйте циклический планировщик . Это дает вам возможность добавлять регулярное время обслуживания для проверки правильности критических данных. Самой большой проблемой часто является повреждение стека. Если ваше программное обеспечение циклично, вы можете повторно инициализировать стек между циклами. Не используйте повторно стеки для вызовов прерываний, настройте отдельный стек каждого важного вызова прерывания.
Подобно концепции Watchdog, применяются таймеры timeline. Запустите аппаратный таймер перед вызовом функции. Если функция не вернется до истечения срока, перезагрузите стек и повторите попытку. Если он по-прежнему не работает после 3/5 попыток, вам нужно перезагрузить ROM.
Разделите свое программное обеспечение на части и изолируйте эти детали (особенно в среде управления). Пример: получение сигнала, предварительные данные, основной алгоритм и реализация/передача результата. Это означает, что сбой в одной части не приведет к сбоям через остальную часть программы.
Все нуждается в CRC. Если вы выполняете RAM, даже ваш .text нуждается в CRC. Регулярно проверяйте CRC, если вы используете циклический планировщик. Некоторые компиляторы (не GCC) могут генерировать CRC для каждого раздела, а некоторые процессоры имеют выделенное оборудование для выполнения CRC-вычислений, но я думаю, что это будет падать в сторону вашего вопроса.
Во-первых, создайте приложение с ошибкой. Убедитесь, что в процессе нормальной работы он ожидает reset (в зависимости от вашего приложения и типа отказа, мягкого или жесткого). Это трудно понять: критические операции, требующие некоторой степени трансакции, могут потребоваться проверять и настраивать на уровне сборки, чтобы прерывание в ключевой точке не могло приводить к противоречивым внешним командам. Сбой быстро, как только обнаружено какое-либо неустранимое повреждение памяти или отклонение потока управления. Ошибки журнала, если это возможно.
Во-вторых, по возможности, исправлять коррупцию и продолжать. Это означает, что проверка и фиксирование постоянных таблиц (и программный код, если можно) часто; возможно, перед каждой крупной операцией или при прерывании по времени и хранением переменных в структурах, которые автокорректируются (снова перед каждым крупным оператором или при прерывании по времени принимается большинство голосов от 3 и исправляется, если это одно отклонение). Корректировки журнала, если это возможно.
В-третьих, сбой теста. Настройте повторяемую тестовую среду, которая переворачивает биты в памяти psuedo-randomly. Это позволит вам реплицировать ситуации с коррупцией и помочь в разработке приложения вокруг них.
Учитывая комментарии суперкара, тенденции современных компиляторов и т.д., у меня возникнет соблазн вернуться к древним временам и написать весь код в сборке и распределении статической памяти везде. Для такой полной надежности я думаю, что сборка больше не несет большой процентной разницы в стоимости.
-
0Я большой поклонник ассемблера (как вы можете видеть из моих ответов на другие вопросы), но я не думаю, что это хороший ответ. Вполне возможно узнать, чего ожидать от компилятора для большей части кода C (с точки зрения значений, хранящихся в регистрах или в памяти), и вы всегда можете проверить, что это то, что вы ожидали. Написание большого проекта в asm - это просто тонна дополнительной работы, даже если у вас есть разработчики, которым очень удобно писать ARM asm. Может быть, если вы хотите выполнить такие вещи, как вычисление одного и того же результата 3 раза, написание некоторых функций в asm имеет смысл. (компиляторы откажутся от него)
-
0Более высокий риск, который должен быть сбалансирован с обновлением компилятора, может привести к неожиданным изменениям.
Вот огромное количество ответов, но я постараюсь подвести итоги по этому поводу.
Что-то сбой или не работает должным образом, может быть результатом ваших собственных ошибок - тогда это должно быть легко исправить, когда вы обнаружите проблему. Но есть также возможность аппаратных сбоев - и это трудно, если не невозможно, исправить в целом.
Я бы порекомендовал сначала попытаться поймать проблематичную ситуацию путем регистрации (стек, регистры, вызовы функций) - либо путем записи их в файл или передачи их как-то напрямую ( "о нет, я сбой" ).
Восстановление из такой ситуации с ошибкой - либо перезагрузка (если программное обеспечение все еще жива и ногами), либо аппаратное обеспечение reset (например, hw watchdogs). Легче начать с первого.
Если проблема связана с оборудованием - тогда регистрация должна помочь вам определить, в какой проблеме с вызовом функции, и которая может дать вам знания о том, что не работает и где.
Также, если код относительно сложный - имеет смысл "делить и побеждать" - это означает, что вы удаляете или отключите некоторые вызовы функций, где вы подозреваете, что проблема - как правило, отключает половину кода и разрешает другую половину - вы можете получить ". work" / "не работает", после чего вы можете сосредоточиться на другой половине кода. (Где проблема)
Если проблема возникает через некоторое время - возможно подозрение на переполнение стека - тогда лучше контролировать регистры точек стека - если они постоянно растут.
И если вам удастся полностью свести к минимуму ваш код до тех пор, пока приложение типа "привет мир" - и оно все равно не удастся случайным образом - тогда ожидаются аппаратные проблемы - и там должно быть "обновление аппаратного обеспечения" - что означает изобретать такие процессоры cpu/ram/... - комбинация, которая лучше переносит излучение.
Самое главное, вероятно, вы вернете свои журналы, если машина полностью остановлена /перезагружена/не работает - возможно, первое, что нужно сделать bootstap, - это вернуться домой, если затронута проблема.
Если в вашей среде также возможно передать сигнал и получить ответ - вы можете попробовать создать какую-то сетевую удаленную среду отладки, но тогда у вас должно быть хотя бы от среды связи, и какой-то процессор/рабочее состояние. И путем удаленной отладки я имею в виду либо подход GDB/gdb-заглушки, либо собственную реализацию того, что вам нужно, чтобы вернуться из вашего приложения (например, загружать файлы журналов, загружать стек вызовов, загружать баран, перезапускать).
-
0Извините, но речь идет о радиоактивной среде, в которой произойдет сбой оборудования. Ваш ответ об общей оптимизации программного обеспечения и о том, как найти ошибки. Но в этой ситуации ошибки не вызваны ошибками
-
0Да, вы можете обвинять также в гравитации Земли, оптимизации компилятора, сторонней библиотеке, радиоактивной среде и так далее. Но вы уверены, что это не ваши собственные ошибки? :-) Если не доказано - я не верю в это. Когда-то я запускал какое-то обновление прошивки и тестировал ситуацию отключения питания - мое программное обеспечение переживало все ситуации отключения питания только после того, как я исправил все свои собственные ошибки. (Более 4000 отключений в ночное время) Но трудно поверить, что в некоторых случаях была ошибка. Особенно, когда мы говорим о повреждении памяти.
Ещё вопросы
- 1Почему значение в List <T> изменяется, если есть копии в ObservableCollection?
- 0cpp файлы работают правильно, но редактор не работает
- 1SSL не работает на Android 2.2 (только в 2.3)
- 1Как заставить сеть Keras не выводить все 1с
- 0Нарисуйте 2 куба в OpenGL, используя GLM
- 1Добавить String в ArrayList, если только не пустой
- 0Как я могу использовать RLIKE для эффективного объединения символов LIKE и IN, * и * escape regex, где это необходимо?
- 0Я пытаюсь запустить код C ++, который использует библиотеку Boost
- 1Как сохранить лучшие веса части энкодера только во время обучения авто-энкодеру ??
- 1Не уверен, почему мой вызов FETCH JavaScript не удается, когда сервер возвращает HttpStatus 200 OK
- 0Структура индекса для вторичного поиска по ключевым словам
- 1Как разбить панду dataframe одной строки на две строки?
- 0Возврат и передача массива для работы в C ++
- 1всплывающее окно на веб-карте
- 0Выборка площади против выборки BRDF при рендеринге
- 1Python: присвоение переменной с использованием «или» с лямбда-функциями? [Дубликат]
- 0ng-repeat для массива объектов выдает $$ hash
- 0Вертикально выровнять div относительно родного брата
- 1Как передать значение свойства в метод init в SAPUI5?
- 0Как использовать mysql после установки более старой версии mariadb через homebrew?
- 0Создайте объект JSON динамически Angular
- 1Рассчитать RA DEC / AZ EL точек Лагранжа, видимых с места на земле
- 0Аутентификация пользователя с использованием сессий с PHP
- 0проблема в кнопке выхода FB
- 1Покупки в приложении (IAP) в Android с ОБА аутентификацией Google и Facebook?
- 1Как вы передаете обнуляемый список объектов с Parcelable
- 0получить идентификатор из ng-repeat
- 1Текстовый редактор с Tkinter Python 3
- 0Разбивка на результаты поиска только с PHP
- 0Добавление двух карт Google на одну страницу HTML
- 0нпм ERR! сеть прочитала ECONNRESET но я не на прокси
- 0анимация ngAnimate не отображается
- 0PHP с помощью MySQL конвертировать набор результатов в массив, а затем в JSON
- 1Разве этот код не должен сделать всю картинку черной?
- 1Получить средние строки, столбца матрицы из текстового файла
- 0Записать переменные JavaScript в файл JSON
- 0Как использовать Backbone на нескольких страницах?
- 1Редактирование текстового средства просмотра текста для всех редактируемых текстов в просмотре списка
- 1Есть ли способ применить метод finalize ()?
- 1XPath выберите узел в Xaml
- 1Как настроить формат отображения DataFrame с комплексными числами?
- 0Доступ к элементам HTML Parent, Child, Sibling в Angular JS
- 0Скрыть / показать веб-часть, щелкнув гиперссылку в карусели Sharepoint 2010
- 0Код OpenGL Работает в Windows, но не в Mac
- 1Расширение двух базовых классов в C # альтернатива
- 1Раскрывающийся список с 4 уровнями одинакового выбора
- 0Ссылаясь на корневой каталог
- 1Файл не создан в SDCARD
- 0MySQL не может отображать полные данные
- 0Angular js: динамические значения в виде строки в ng-модели внутри ng-repeat
