C ++ 11 представил стандартизированную модель памяти. Что это значит? И как это повлияет на программирование на C ++?
C++ 11 представила стандартизованную модель памяти, но что именно это означает? И как это повлияет на программирование C++?
Эта статья (Гэвин Кларк, цитирующая Херба Саттера) говорит, что,
Модель памяти означает, что код C++ теперь имеет стандартизованную библиотеку для вызова независимо от того, кто создал компилятор и на какой платформе он работает. Там стандартный способ контролировать, как разные потоки разговаривают с памятью процессора.
"Когда вы говорите о разделении [кода] на разные ядра, которые находятся в стандарте, мы говорим о модели памяти. Мы собираемся ее оптимизировать, не нарушая следующих предположений, которые люди собираются сделать в коде", - сказал Саттер.
Ну, я могу запомнить этот и аналогичные абзацы, доступные в Интернете (так как у меня была моя собственная модель памяти с момента рождения: P), и я могу даже написать ответ на вопросы, заданные другими, но, честно говоря, я не совсем понимаю этот.
C++ программисты использовали для разработки многопоточных приложений еще раньше, поэтому как это важно, если это потоки POSIX или потоки Windows или C++ 11 потоков? Каковы преимущества? Я хочу понять детали низкого уровня.
Я также чувствую, что модель памяти C++ 11 каким-то образом связана с поддержкой многопоточности C++ 11, так как я часто вижу эти два вместе. Если да, то как именно? Почему они должны быть связаны?
Поскольку я не знаю, как работают работы с несколькими потоками и какая модель памяти в целом, пожалуйста, помогите мне понять эти понятия. :-)
6 ответов
Во-первых, вы должны научиться думать, как юрист по языку.
Спецификация C++ не ссылается ни на какой конкретный компилятор, операционную систему или процессор. Он ссылается на абстрактную машину, которая является обобщением реальных систем. В мире юристов, работа программиста заключается в написании кода для абстрактной машины; работа компилятора заключается в том, чтобы реализовать этот код на конкретной машине. Если вы строго кодируете спецификацию, вы можете быть уверены, что ваш код будет компилироваться и запускаться без изменений в любой системе с совместимым компилятором C++, будь то сегодня или через 50 лет.
Абстрактная машина в спецификации C++ 98/C++ 03 принципиально однопоточная. Таким образом, невозможно написать многопоточный код C++, который полностью переносится по спецификации. Спецификация даже не говорит ничего об атомарности загрузок и хранилищ памяти или о порядке загрузки и хранения данных, не говоря уже о таких вещах, как мьютексы.
Конечно, вы можете написать многопоточный код на практике для конкретных конкретных систем - например, pthreads или Windows. Но нет стандартного способа написания многопоточного кода для C++ 98/C++ 03.
Абстрактная машина в C++ 11 многопоточная по дизайну. Он также имеет хорошо определенную модель памяти; то есть он говорит, что компилятор может и не может делать, когда дело доходит до доступа к памяти.
Рассмотрим следующий пример, при котором пару глобальных переменных обращаются одновременно двумя потоками:
Global
int x, y;
Thread 1 Thread 2
x = 17; cout << y << " ";
y = 37; cout << x << endl;
Что могло бы вывести Thread 2?
В C++ 98/C++ 03 это даже не неопределенное поведение; сам вопрос бессмыслен, поскольку стандарт не рассматривает ничего, называемое "нитью".
В C++ 11 результатом является неопределенное поведение, потому что нагрузки и магазины не обязательно должны быть атомарными вообще. Что может показаться не очень хорошим улучшением... И само по себе это не так.
Но с C++ 11 вы можете написать следующее:
Global
atomic<int> x, y;
Thread 1 Thread 2
x.store(17); cout << y.load() << " ";
y.store(37); cout << x.load() << endl;
Теперь все становится намного интереснее. Прежде всего, здесь определяется поведение. Thread 2 теперь может печатать 0 0 (если он работает до Thread 1), 37 17 (если он выполняется после Thread 1) или 0 17 (если он запускается после того, как Thread 1 назначает x, но до того, как он назначит y).
То, что он не может напечатать, равен 37 0, потому что режим по умолчанию для атомных нагрузок/хранилищ в C++ 11 заключается в обеспечении последовательной согласованности. Это означает, что все нагрузки и хранилища должны быть "как если бы", они произошли в том порядке, в котором вы их записывали в каждом потоке, тогда как операции между потоками могут чередоваться, но система нравится. Таким образом, поведение Atomics по умолчанию обеспечивает как атомарность, так и порядок загрузки и хранения.
Теперь, на современном процессоре, обеспечение последовательной согласованности может быть дорогостоящим. В частности, компилятор, вероятно, испускает полномасштабные барьеры памяти между каждым доступом здесь. Но если ваш алгоритм может терпеть неуправляемые нагрузки и магазины; т.е. если он требует атомарности, но не упорядочивает; т.е. если он может вынести 37 0 качестве выхода из этой программы, тогда вы можете написать это:
Global
atomic<int> x, y;
Thread 1 Thread 2
x.store(17,memory_order_relaxed); cout << y.load(memory_order_relaxed) << " ";
y.store(37,memory_order_relaxed); cout << x.load(memory_order_relaxed) << endl;
Чем более современный процессор, тем более вероятно, что это будет быстрее, чем предыдущий пример.
Наконец, если вам просто нужно сохранить определенные нагрузки и магазины в порядке, вы можете написать:
Global
atomic<int> x, y;
Thread 1 Thread 2
x.store(17,memory_order_release); cout << y.load(memory_order_acquire) << " ";
y.store(37,memory_order_release); cout << x.load(memory_order_acquire) << endl;
Это возвращает нас к упорядоченным нагрузкам и магазинам - поэтому 37 0 больше не является возможным выходом, но он делает это с минимальными накладными расходами. (В этом тривиальном примере результат такой же, как полномасштабная последовательная согласованность, в более крупной программе этого не будет).
Конечно, если только выходы, которые вы хотите увидеть, 0 0 или 37 17, вы можете просто обернуть мьютексом вокруг исходного кода. Но если вы зачитали это далеко, я уверен, вы уже знаете, как это работает, и этот ответ уже дольше, чем я предполагал :-).
Итак, нижняя строка. Мьютексы велики, и C++ 11 их стандартизирует. Но иногда по соображениям производительности вам нужны примитивы нижнего уровня (например, классический шаблон с двойной проверкой блокировки). Новый стандарт обеспечивает высокоуровневые гаджеты, такие как мьютексы и переменные состояния, а также предоставляет низкоуровневые гаджеты, такие как атомные типы и различные варианты защиты памяти. Итак, теперь вы можете писать сложные высокопроизводительные параллельные подпрограммы полностью на языке, указанном стандартом, и вы можете быть уверены, что ваш код будет компилироваться и работать без изменений как на сегодняшних, так и на завтрашних.
Хотя, если быть откровенным, если вы не являетесь экспертом и не работаете над каким-то серьезным низкоуровневым кодом, вы, вероятно, должны придерживаться мьютексов и переменных условий. Это то, что я намереваюсь сделать.
Подробнее об этом см. В этом сообщении в блоге.
-
32Хороший ответ, но это действительно требует некоторых примеров новых примитивов. Кроме того, я думаю, что порядок памяти без примитивов такой же, как и до C ++ 0x: никаких гарантий нет.John Ripley
-
4@John: я знаю, но я все еще изучаю примитивы сам :-). Также я думаю, что они гарантируют, что доступ к байту является атомарным (хотя и не упорядоченным), поэтому я выбрал «char» для моего примера ... Но я даже не уверен на 100% в этом ... Если вы хотите предложить что-нибудь хорошее » учебник "ссылки я добавлю их в мой ответNemo
Я просто дам аналогию, с которой я понимаю модели согласованности памяти (или модели памяти, для краткости). Его вдохновляет семантическая бумага Лесли Лампорта "Время, часы и порядок событий в распределенной системе" . Аналогия уместна и имеет фундаментальное значение, но может быть излишним для многих людей. Однако я надеюсь, что это дает мысленный образ (графическое представление), что облегчает рассуждение о моделях согласованности памяти.
Позволяет просмотреть истории всех мест памяти в диаграмме пространства-времени, в которой горизонтальная ось представляет адресное пространство (т.е. каждая ячейка памяти представлена точкой на этой оси), а вертикальная ось представляет время (мы будем см., что в общем, нет универсального понятия времени). Таким образом, история значений, хранящихся в каждой ячейке памяти, представлена вертикальным столбцом по этому адресу памяти. Каждое изменение значения связано с тем, что один из потоков записывает новое значение в это место. Под изображением памяти мы будем понимать совокупность/комбинацию значений всех мест памяти, которые наблюдаются в определенное время, с помощью конкретного потока.
Цитата из "Основатель согласованности и согласованности кеша"
Интуитивная (и наиболее ограничительная) модель памяти представляет собой последовательную согласованность (SC), в которой многопоточное выполнение должно выглядеть как чередование последовательных исполнений каждого составного потока, как если бы потоки были мультиплексированы по времени на одноядерном процессор.
Этот глобальный порядок памяти может варьироваться от одного запуска программы к другому и может быть не известен заранее. Характерной особенностью SC является набор горизонтальных срезов в диаграмме адрес-пространство-время, представляющий плоскости одновременности (т.е. Изображения в памяти). На данной плоскости все его события (или значения памяти) являются одновременными. Существует понятие Абсолютного времени, в котором все нити согласуются с тем, какие значения памяти являются одновременными. В SC в каждый момент времени есть только один образ памяти, общий для всех потоков. То есть, в каждый момент времени все процессоры согласуются с образом памяти (т.е. Совокупным содержимым памяти). Это не только означает, что все потоки рассматривают одну и ту же последовательность значений для всех мест памяти, но также и то, что все процессоры выполняют одни и те же комбинации значений всех переменных. Это то же самое, что сказать, что все операции с памятью (по всем ячейкам памяти) наблюдаются в том же полном порядке всеми потоками.
В моделях с ослабленной памятью каждый поток будет разделять адрес-пространство-время по-своему, единственным ограничением является то, что срезы каждого потока не пересекаются друг с другом, потому что все потоки должны согласовывать историю каждой отдельной ячейки памяти (конечно, кусочки разных нитей могут и будут пересекаться друг с другом). Нет универсального способа разрезать его (без привилегированного слоения адресного пространства-времени). Ломтики не должны быть плоскими (или линейными). Они могут быть изогнутыми, и это то, что может сделать значения чтения потока, написанные другим потоком, из того, в каком они были написаны. Истории разных мест памяти могут скользить (или растягиваться) произвольно относительно друг друга при просмотре любой конкретный поток. Каждый поток будет иметь другое представление о том, какие события (или, что то же самое, значения памяти) являются одновременными. Набор событий (или значений памяти), которые одновременно связаны с одним потоком, не являются одновременными с другими. Таким образом, в модели с ослабленной памятью все потоки по-прежнему сохраняют одну и ту же историю (то есть последовательность значений) для каждой ячейки памяти. Но они могут наблюдать разные образы памяти (т.е. Сочетания значений всех мест памяти). Даже если два разных места памяти записаны одним и тем же потоком в последовательности, два новых записанных значения могут наблюдаться в другом порядке другими потоками.
[Иллюстрация из Википедии]
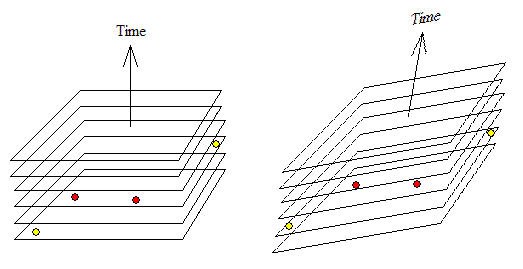
Читатели, знакомые с Einsteins Специальная теория относительностизаметят, о чем я говорю. Перевод слов Минковского в область моделей памяти: адресное пространство и время - это тени адресного пространства-времени. В этом случае каждый наблюдатель (т.е. Поток) будет проектировать тени событий (т.е. Запоминает память/нагрузки) на свою собственную линию мира (т.е. Свою временную ось) и свою собственную плоскость одновременности (его ось адресного пространства), Темы в модели памяти С++ 11 соответствуют наблюдателям, которые перемещаются относительно друг друга в специальной теории относительности. Последовательная согласованность соответствует галилеевому пространству-времени (т.е. Все наблюдатели соглашаются на один абсолютный порядок событий и глобальное чувство одновременности).
Сходство между моделями памяти и специальной теорией относительности связано с тем, что оба определяют частично упорядоченный набор событий, часто называемый причинным множеством. Некоторые события (т.е. Хранилища памяти) могут влиять (но не влиять) на другие события. Поток С++ 11 (или наблюдатель в физике) представляет собой не более чем цепочку (т.е. Полностью упорядоченную совокупность) событий (например, память загружает и сохраняет к возможным различным адресам).
В теории относительности некоторый порядок восстанавливается на кажущуюся хаотичную картину частично упорядоченных событий, так как единственным временным порядком, с которым согласны все наблюдатели, является упорядочение среди "временных событий" (т.е. те события, которые в принципе могут быть связаны любым частица идет медленнее, чем скорость света в вакууме). Только упорядоченные по времени события инвариантно упорядочены. Время в физике, Craig Callender.
В модели памяти С++ 11 аналогичный механизм (модель согласованности-освобождения-выпуска) используется для установления этих локальных причинно-следственных связей.
Чтобы обеспечить определение последовательности памяти и мотивации отказа от SC, я приведу из Primer по согласованности памяти и согласованности кеша
Для компьютера с общей памятью модель согласованности памяти определяет архитектурно видимое поведение своей системы памяти. Критерий правильности одного ядра процессора разбивает поведение между "одним правильным результатом" и "множеством неправильных альтернатив". Это связано с тем, что архитектура процессоров предусматривает, что выполнение потока преобразует заданное входное состояние в одно четко определенное состояние вывода даже на ядре вне порядка. Однако модели согласованности с общей памятью относятся к нагрузкам и хранилищам нескольких потоков и обычно позволяют много правильных исполнений, не допуская многих (более) неправильных. Возможность множественных правильных исполнений обусловлена тем, что ISA позволяет одновременному выполнению нескольких потоков, часто со многими возможными законными перехватами команд из разных потоков.
Relaxed или слабые модели согласованности памяти мотивированы тем, что большинство упорядочений памяти в сильных моделях не нужно. Если поток обновляет десять элементов данных, а затем флаг синхронизации, программистам обычно не важно, обновлены ли элементы данных по порядку относительно друг друга, а только обновлены все элементы данных до обновления флага (обычно они реализуются с использованием инструкции FENCE). Расслабленные модели стремятся уловить эту повышенную гибкость порядка и сохранить только заказы, которые программисты "требуют", чтобы получить как более высокую производительность, так и правильность SC. Например, в некоторых архитектурах буферы записи FIFO используются каждым ядром для хранения результатов фиксированных (удаленных) хранилищ перед тем, как записывать результаты в кеши. Эта оптимизация повышает производительность, но нарушает SC. Буфер записи скрывает задержку обслуживания пропусков магазина. Поскольку магазины являются общими, возможность избежать остановки большинства из них является важным преимуществом. Для одноядерного процессора буфер записи может быть сделан архитектурно невидимым, гарантируя, что загрузка адреса A возвращает значение самого последнего хранилища в A, даже если один или несколько хранилищ для A находятся в буфере записи. Обычно это делается путем обхода значения самого последнего хранилища в до нагрузки от A, где "последнее" определяется порядком программы или путем остановки нагрузки A, если хранилище A находится в буфере записи, Когда используется несколько ядер, каждый из них будет иметь свой собственный байпас записи. Без буферов записи аппаратное обеспечение является SC, но с буферами записи это не так, что делает буферы записи архитектурно видимыми в многоядерном процессоре.
Переупорядочение магазина-хранилища может произойти, если в ядре есть буфер записи, отличный от FIFO, который позволяет магазинам уходить в другом порядке, чем в том порядке, в котором они были введены. Это может произойти, если первый магазин промахивается в кеше, а второй - или если второй магазин может объединиться с более ранним хранилищем (то есть перед первым хранилищем). Переупорядочение нагрузки может также происходить в динамически запланированных ядрах, которые выполняют инструкции из программы. Это может вести себя так же, как переупорядочение магазинов на другом ядре (можете ли вы придумать пример чередования между двумя потоками?). Переупорядочение ранней загрузки с последующим хранилищем (переупорядочение хранилища-загрузки) может привести к множеству неправильных действий, таких как загрузка значения после отпускания блокировки, которая его защищает (если хранилище является операцией разблокировки). Обратите внимание, что переупорядочивание в хранилище может также возникать из-за локального обхода в обычно реализованном буфере записи FIFO даже с ядром, которое выполняет все команды в порядке выполнения программы.
Поскольку согласованность кэша и согласованность памяти иногда сбиты с толку, поучительно также иметь эту цитату:
В отличие от согласованности, когерентность кэша не отображается ни в программном обеспечении, ни в запросе. Когерентность направлена на то, чтобы кэши системы с разделяемой памятью были функционально невидимы как кеши в одноядерной системе. Правильная согласованность гарантирует, что программист не может определить, имеет ли и где система кэширует, анализируя результаты нагрузок и хранилищ. Это связано с тем, что правильная когерентность гарантирует, что кэши никогда не будут включать новое или другое поведение функционировать (программисты могут все еще иметь возможность вывести вероятную структуру кэша, используя информацию время). Основная цель протоколов когерентности кеша - поддерживать инвариант одиночного писателя-множественного считывателя (SWMR) для каждой ячейки памяти. Важным различием между согласованностью и согласованностью является то, что согласованность указана в на основе расположения памяти, тогда как согласованность указана в отношении местоположений памяти all.
Продолжая нашу ментальную картину, инвариант SWMR соответствует физическому требованию, чтобы в одной точке находилось не более одной частицы, но может быть неограниченное количество наблюдателей любого местоположения.
-
47+1 за аналогию со специальной теорией относительности, я сам пытался провести аналогию. Слишком часто я вижу программистов, исследующих многопоточный код, пытающихся интерпретировать поведение как операции, происходящие в разных потоках, чередующиеся друг с другом в определенном порядке, и я должен сказать им, нет, с многопроцессорными системами понятие одновременности между различными > Точки отсчета </ s> темы теперь бессмысленны. Сравнение со специальной теорией относительности - это хороший способ заставить их уважать сложность проблемы.
-
54Таким образом, вы должны сделать вывод, что Вселенная является многоядерной?
Теперь это многолетний вопрос, но, будучи очень популярным, стоит упомянуть фантастический ресурс для изучения модели памяти С++ 11.Я не вижу смысла подытоживать его разговор, чтобы сделать этот еще один полный ответ, но учитывая, что это тот парень, который на самом деле написал стандарт, я думаю, что стоит посмотреть разговор.
Herb Sutter имеет трехчасовой разговор о модели памяти С++ 11 под названием "атомное оружие", доступное на сайте Channel9 - часть 1 и часть 2. Разговор довольно технический и охватывает следующие темы:
- Оптимизации, расы и модель памяти
- Заказ - Что: Приобретать и выпускать
- Заказ - Как: Мьютекс, Атомная техника и/или Заборы
- Другие ограничения на компиляторы и аппаратные средства
- Код Gen & Performance: x86/x64, IA64, POWER, ARM
- Расслабленная атомная энергия
В разговоре не говорится об API, а скорее о рассуждениях, предпосылках под капотом и за кулисами (знаете ли вы, что смягченная семантика была добавлена к стандарту только потому, что POWER и ARM не поддерживают синхронизированную нагрузку эффективно?).
-
6Этот разговор действительно фантастический, он стоит тех трех часов, которые вы потратите на его просмотр.
-
4@ZunTzu: на большинстве видеоплееров вы можете установить скорость в 1,25, 1,5 или даже в 2 раза больше оригинальной.
Это означает, что стандарт теперь определяет многопоточность, и он определяет, что происходит в контексте нескольких потоков. Конечно, люди использовали различные реализации, но это, как и вопрос о том, почему мы должны иметь std::string, когда мы все могли бы использовать класс, состоящий из класса string.
Когда вы говорите о потоках POSIX или потоках Windows, это немного иллюзия, поскольку вы говорите о потоках x86, так как это аппаратная функция для запуска одновременно. Модель памяти С++ 0x дает гарантии, будь вы на x86 или ARM, или MIPS, или что-нибудь еще, что вы можете придумайте.
-
25Потоки Posix не ограничиваются x86. Действительно, первые системы, на которых они были реализованы, были, вероятно, не системами x86. Потоки Posix не зависят от системы и действуют на всех платформах Posix. Это также не совсем верно, что это аппаратное свойство, потому что потоки Posix также могут быть реализованы посредством совместной многозадачности. Но, конечно же, большинство проблем с многопоточностью возникают только при реализации аппаратных потоков (а некоторые даже только в многопроцессорных / многоядерных системах).
Для языков, не определяющих модель памяти, вы пишете код для языка и модель памяти, указанную в архитектуре процессора. Процессор может выбрать способ переназначения доступа к памяти для производительности. Итак, , если ваша программа имеет расы данных (гонка данных - это когда возможно одновременное обращение к нескольким ядрам/гиперпотокам к одной и той же памяти), то ваша программа не является перекрестной платформой из-за ее зависимости от процессор. Вы можете обратиться к руководствам по программному обеспечению Intel или AMD, чтобы узнать, как процессоры могут повторно заказать доступ к памяти.
Очень важно, что блокировки (и concurrency семантики с блокировкой) обычно реализуются кросс-платформенным способом... Поэтому, если вы используете стандартные блокировки в многопоточной программе без расчётов данных, вы не выполняете приходится беспокоиться о моделях памяти с межплатформенной платформой.
Интересно, что компиляторы Microsoft для С++ имеют семантику получения/выпуска для volatile, которая является расширением С++, чтобы справиться с отсутствием модели памяти в С++ http://msdn.microsoft.com/en-us/library/12a04hfd(v=vs.80).aspx. Однако, учитывая, что Windows работает только на x86/x64, это не говорит о многом (модели памяти Intel и AMD позволяют легко и эффективно реализовать семантику получения/выпуска на языке).
-
1Это правда, что когда был написан ответ, Windows работала только на x86 / x64, но в какой-то момент Windows работала на IA64, MIPS, Alpha AXP64, PowerPC и ARM. Сегодня он работает на различных версиях ARM, которые отличаются от памяти x86, и нигде не так просты.
-
0Эта ссылка несколько неработающая (говорится в документации по Visual Studio 2005 «Устаревшие» ). Хотите обновить его?
Если вы используете мьютексы для защиты всех ваших данных, вам действительно не нужно беспокоиться. Мьютексы всегда обеспечивали достаточные гарантии порядка и видимости.
Теперь, если вы использовали атомы или алгоритмы блокировки, вам нужно подумать о модели памяти. Модель памяти точно описывает, когда атомистика обеспечивает гарантии порядка и видимости и обеспечивает переносные ограждения для гарантированных вручную гарантий.
Ранее атомы выполнялись с использованием встроенных средств компилятора или некоторой библиотеки более высокого уровня. Заборы были бы выполнены с использованием инструкций, специфичных для процессора (барьеров памяти).
-
18Раньше проблема заключалась в том, что не было такого понятия, как мьютекс (с точки зрения стандарта C ++). Таким образом, единственные гарантии, которые вам предоставили, были от производителя мьютекса, что было хорошо, если вы не портировали код (так как незначительные изменения в гарантиях трудно обнаружить). Теперь мы получаем гарантии, предусмотренные стандартом, который должен быть переносимым между платформами.
-
4@Martin: в любом случае одна вещь - это модель памяти, а другая - это атомарные и потоковые примитивы, которые работают поверх этой модели памяти.
Ещё вопросы
- 1Python Selenium: получить значения из выпадающего списка
- 1какой тип лучше всего подходит для трех радиокнопок?
- 1Нужно ли разрабатывать для нескольких разрешений экрана в Unity?
- 1Springdata: mongodb находит запрос с необязательными «критериями»
- 1Показать список из списка viewbag в MVC4
- 0как я могу сделать выпадающее меню на всю ширину
- 1Запрет проверки Struts 2 для определенных действий
- 0Удалить из всех таблиц, где ip равен ip
- 0ionic не удалось загрузить веб-страницу с ошибкой: операция не может быть завершена. (NSURLErrorDomain ошибка -999.)
- 0Вызов URL-адреса неблокирующим способом на веб-странице
- 0Я получаю «Усеченное неверное значение даты и времени:« 0000-00-00 »» даже при выключенном строгом режиме.
- 0Вернуть функцию несколько раз вместо одного, используя .fadeOut ();
- 0mysql 0000-00-00 ошибка обновления
- 0Rails 4 + AngularJS: функции конфигурации и запуска App.js не работают
- 0Контроллер ресурсов показывает белый экран в Laravel 4, несмотря на рабочие маршруты
- 0файл загружен в папку, но путь не сохраняется в базе данных
- 1«ggbApplet не определен» ошибка в JavaScript
- 0CSS Divs перекрывают друг друга
- 0Как мне преобразовать ответ $ http.post в $ resource в angularjs?
- 1Unity вращает камеру с помощью сенсорного экрана - мобильный
- 0Слишком много символов в символьном литерале при преобразовании тега HTML в ссылку на сущность
- 1Как передать параметр в JavaScript найти функцию?
- 1Можно ли выполнить условную сортировку по двум различным столбцам, но где порядок двух столбцов меняется на обратный в зависимости от вторичного условия?
- 0jQuery bind и click click evnts не работают в IE9
- 0Как правильно выровнять то, что изменяет размеры в определенном месте
- 0Почему я не могу загрузить значения базы данных в мой список?
- 1Проблема при компиляции привет мирового класса с использованием Javassist
- 0использование итераторов вставки без std :: copy
- 1Поместите текст внутри круга. d3.js
- 0Доступ к индивидуальному свойству из SimpleXMLElement Object
- 0SIGBUS при уничтожении объекта с помощью std :: fstream объектов
- 0Добавление двух карт Google на одну страницу HTML
- 0Jquery переключения. Аналогичный пример
- 0Случайное число в пределах диапазона для Float ИЛИ Int
- 1Доступ к новым экземплярам UserControl в других методах
- 0Два всплывающих окна не работают должным образом
- 0Удаленный доступ к серверу MySQL на виртуальной машине
- 1Как получить идентификатор электронной почты в [email protected] вместо «CN = пример / OU = Сервер / O = компания» в заметках лотоса в Java
- 0Angularjs Многомерный массив и два относительных поля выбора
- 0опция по умолчанию в поле выбора - угловой JS
- 1Как мне проанализировать JSON, у которого экранированы акценты ключей и значений, не влияя на экранирование в значениях полей?
- 1Реальные объявления не показываются с помощью Admob
- 1XPath выберите узел в Xaml
- 1Как определить регулярное выражение
- 0ngSwitch не обновляется при изменении модели данных
- 0настроить веб-страницу под любое устройство
- 1Как получить ArrayList из ArrayList.subList?
- 0Советы по базе данных MySQL
- 1JavaScript, ошибка JavaScript
- 0Обработка неопределенных переменных в Javascript
