Механика и задачи
Системы распределенной трассировки позволяют пользователям отслеживать запрос через программную систему, которая распределена по нескольким приложениям, службам и базам данных, а также через посредников, таких как прокси. Это позволяет глубже понять, что происходит в системе программного обеспечения. Эти системы создают графические представления, которые показывают, сколько времени занимал запрос на каждом шаге, и перечисляют каждый известный шаг.
Пользователь, просматривающий этот контент, может определить, где система испытывает задержки или блокировки. Вместо того, чтобы тестировать систему, как бинарное дерево поиска (когда запросы начинают давать сбои), операторы и разработчики могут точно видеть, где начинаются проблемы. Это также может показать, где могут произойти изменения производительности от развертывания к развертыванию. Всегда лучше автоматически отслеживать регрессии, заранее зная об аномальном поведении, чем узнавать об этом от ваших клиентов.
Как работает эта трассирующая система? Каждый запрос получает специальный идентификатор, который обычно вводится в заголовки. Этот идентификатор уникально идентифицирует эту транзакцию. Эта транзакция обычно называется трассировкой. Трассировка является общей абстрактной идеей всей транзакции. Каждая трассировка составлена из промежутков. Эти промежутки представляют собой фактическую выполняемую работу, например, вызов службы или запрос к базе данных. Каждый промежуток также имеет уникальный идентификатор. Пролеты могут создавать последующие промежутки, называемые дочерними, а дочерние пролеты могут иметь несколько родительных идентификаторов.
Как только транзакция (или трассировка) прошла курс, ее можно искать на уровне представления. В этом пространстве есть несколько инструментов, о которых мы поговорим позже, но на рисунке ниже показан Jaeger из моего прохождения Istio. Он показывает несколько отрезков одной трассировки. Польза от этого сразу очевидна, так как вы можете лучше понять историю транзакции.
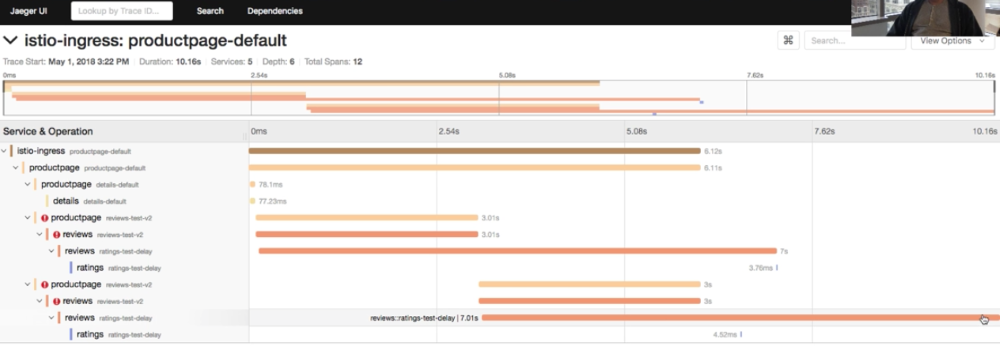
В этом демонстрационном примере используется встроенная в Istio реализация OpenTracing, поэтому я могу получить трассировку, даже не меняя свое приложение. Тут также используется Jaeger, который совместим с OpenTracing.
Так что же такое OpenTracing? Давайте разберемся.
OpenTracing API
OpenTracing – это спецификация, которая выросла из Zipkin для обеспечения кроссплатформенной совместимости. Она предлагает независимый от поставщика API для добавления трассировки в приложения и доставки этих данных в распределенные системы трассировки. Библиотека, написанная для спецификации OpenTracing, может использоваться с любой системой, совместимой с OpenTracing. Zipkin, Jaeger и Appdash являются примерами инструментов с открытым исходным кодом, которые приняли открытый стандарт, но даже такие проприетарные инструменты, как Datadog и Instana, принимают его. Ожидается, что такая тенденция продолжится, когда OpenTracing достигнет и повсеместного статуса.
OpenCensus
Хорошо, у нас есть OpenTracing, но что это за вещь OpenCensus, которая постоянно появляется в моих результатах поисках? Это конкурирующий стандарт, что-то совершенно другое или что-то дополнительное?
OpenCensus использует более целостный или всеобъемлющий подход. OpenTracing нацелен на создание открытого API и спецификации, а не на открытые реализации для каждого языка и системы трассировки. OpenCensus предоставляет не только спецификацию, но и языковые реализации и протокол связи. Он также выходит за рамки трассировки, включая дополнительные метрики, которые обычно выходят за рамки распределенных систем трассировки.
OpenCensus позволяет просматривать данные на хосте, на котором выполняется приложение, но также имеет подключаемую систему экспорта для экспорта данных в центральные агрегаторы. В настоящее время экспортерами, созданными командой OpenCensus, являются Zipkin, Prometheus, Jaeger, Stackdriver, Datadog и SignalFx, но любой может создать свой экспортер.
С моей точки зрения, у этих программных решений много общего. Одно не обязательно лучше другого, но важно знать, что каждый делает, а что нет. OpenTracing – это, прежде всего, спецификация, а другие занимаются реализацией. OpenCensus обеспечивает целостный подход к локальному компоненту, но все еще требует других систем для удаленного агрегирования.
Вариации инструментов
Zipkin
Zipkin был одной из первых систем такого рода. Он был разработан Twitter на основе Google Dapper о внутренней системе, которую использует Google. Zipkin был написан с использованием Java, и он может использовать Cassandra или ElasticSearch в качестве масштабируемого бэкэнда. Большинство компаний должны быть удовлетворены одним из этих вариантов. Самая низкая поддерживаемая версия Java – Java 6. Он также использует двоичный протокол связи Thrift, который популярен в стеке Twitter и размещается как проект Apache.
Система состоит из репортеров (клиентов), сборщиков, службы запросов и веб-интерфейса. Предполагается, что Zipkin безопасен в производстве, передавая только идентификатор трассировки в контексте транзакции, чтобы информировать получателей о том, что трасса находится в процессе обработки. Данные, собранные в каждом репортере, затем асинхронно передаются коллекторам. Сборщики хранят эти промежутки в базе данных, а веб-интерфейс представляет эти данные конечному пользователю в формате расходных материалов. Доставка данных сборщикам может осуществляться тремя различными способами: HTTP, Kafka и Scribe.
Сообщество Zipkin также создало Brave, реализацию Java-клиента, совместимую с Zipkin. У него нет никаких зависимостей, поэтому он не будет тянуть ваши проекты или загромождать их библиотеками, несовместимыми с вашими корпоративными стандартами. Существует много других реализаций, и Zipkin совместим со стандартом OpenTracing, поэтому эти реализации также должны работать с другими системами распределенной трассировки. В популярной среде Spring есть компонент под названием Spring Cloud Sleuth, совместимый с Zipkin.
Jaeger
Jaeger – это более новый проект от Uber Technologies, который CNCF с тех пор принял как Incubating project. Он написан на Golang, так что вам не нужно беспокоиться об установках зависимостей на хосте или каких-либо накладных расходах на интерпретаторы или языковые виртуальные машины. Подобно Zipkin, Jaeger также поддерживает Cassandra и ElasticSearch в качестве масштабируемого бэкэнда хранилища. Jaeger также полностью совместим со стандартом OpenTracing.
Архитектура Jaeger похожа на Zipkin, с клиентами (репортерами), сборщиками, службой запросов и веб-интерфейсом, но на каждом хосте также есть агент, который локально агрегирует данные. Агент получает данные по UDP-соединению, которое он пакетирует и отправляет сборщику. Сборщик получает эти данные в форме протокола Thrift и сохраняет эти данные в Cassandra или ElasticSearch. Служба запросов может напрямую обращаться к хранилищу данных и предоставлять эту информацию в веб-интерфейс.
По умолчанию пользователь не получает все трассировки от клиентов Jaeger. Система выбирает 0,1% (1 на 1000) трассировок, которые проходят через каждого клиента. Хранение и передача всех трассировок была бы немного сложной для большинства систем. Однако их количество может быть увеличено или уменьшено путем настройки агентов, с которыми клиент консультируется для своей конфигурации. Эта выборка не совсем случайна, и она становится лучше. Jaeger использует вероятностную выборку, которая пытается сделать обоснованное предположение о том, следует ли отбирать новую трассировку или нет. Адаптивная выборка включена в план, который улучшит алгоритм выборки, добавив дополнительный контекст для принятия решений.
Appdash
Appdash – это распределенная система трассировки, написанная на Golang, как Jaeger. Она была создана Sourcegraph на основе Google Dapper и Twitter Zipkin. Подобно Jaeger и Zipkin, Appdash поддерживает стандарт OpenTracing, который был добавлен позднее и требует компонента, который отличается от компонента по умолчанию. Это добавляет ему рисков и сложностей в использовании.
На высоком уровне архитектура Appdash состоит в основном из трех компонентов: клиента, локального сборщика и удаленного сборщика. Клиент в Appdash добавляется в ваш код. Appdash предоставляет реализации Python, Golang и Ruby, но библиотеки OpenTracing можно использовать с реализацией OpenTracing Appdash. Клиент собирает пролеты и отправляет их местному сборщику. Затем локальный сборщик отправляет данные на централизованный сервер Appdash, на котором работает собственный локальный сборщик, который является удаленным сборщиком для всех других узлов в системе.